Introducing Soda 4.0: Bringing AI, Engineers and Business SMEs together to automate data quality.
Introducing Soda 4.0: Bringing AI, Engineers and Business SMEs together to automate data quality.
Jan 28, 2026

Santiago Viquez
Santiago Viquez
Santiago Viquez
DevRel at Soda
DevRel at Soda
DevRel at Soda
Table of Contents

For a long time, data quality has lived as aspirational rules in documents humans could read, but machines could not execute.
Data teams have spent gazillions of hours in Zoom meetings, circle-backs, and "as per my last email" back-and-forths trying to agree on which business rules a field should comply with, only to then spend weeks waiting for engineers to turn those rules into code.
All of this is about to change. It no longer makes sense to separate rule definition from enforcement. Businesses should write rules in natural language, and AI should automatically translate them into code, so collaboration with engineers is simple and fast.
It should be virtually impossible for a table to go untested. Every table should start with a baseline Data Contract, created from dataset context, metadata, and catalog information. Contracts that can later be refined through business and engineering workflows. AI-powered data observability should run automatically, so even if we forget to add a descriptive check, anomaly detection is always running in the background, alerting us to anything unusual.
Today, we introduce Soda 4.0: a unified data quality platform that does all of that. And more. It helps teams validate and continuously improve the quality of their data.
This is the beginning of a self-driving data quality platform.
Everything new in Soda 4.0
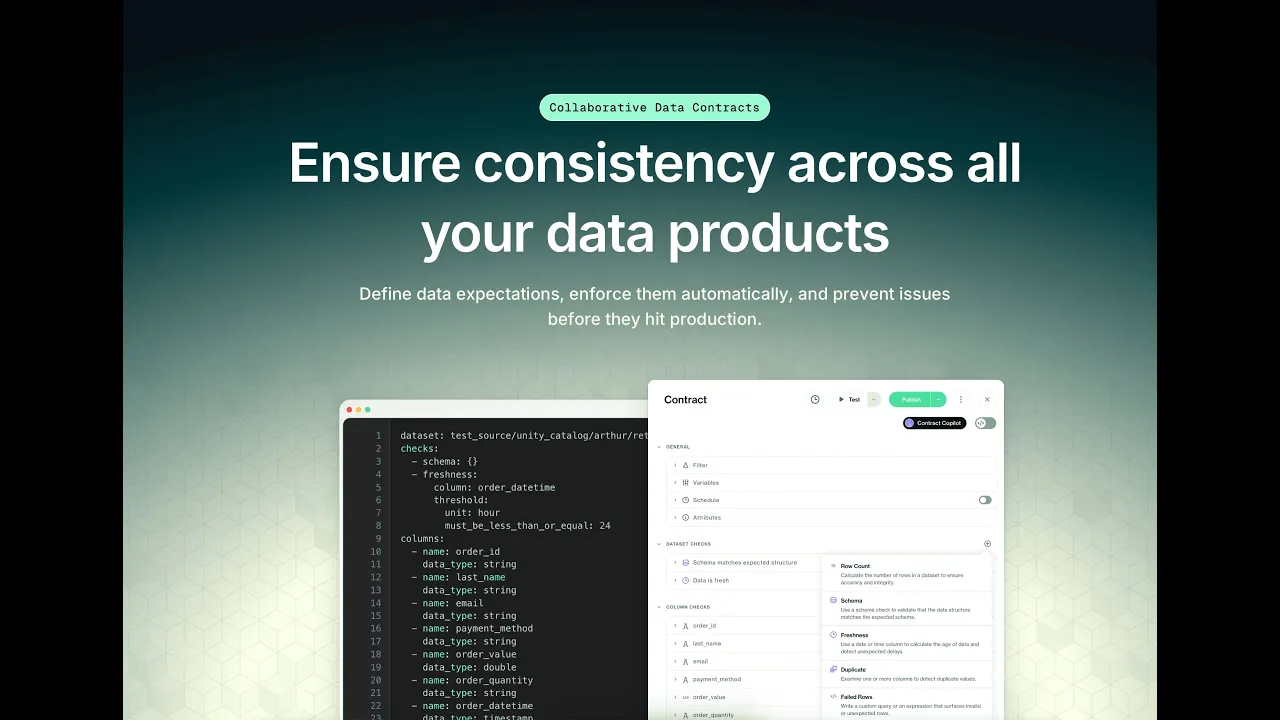
We are introducing a new data contracts engine and a unified cloud platform that brings observability, AI, and data quality enforcement together.
Soda Core 4.0 — Data Contracts Engine: An open-source engine that formalizes the standard for defining and executing data contracts. A clean, data-quality–first syntax supporting 50+ built-in check types.
Soda Cloud 4.0 — Unified, self-driving data quality platform: It unites AI-powered contract generation, feedback-driven anomaly detection, deep diagnostic capabilities, and a faster, cleaner interface into a single platform where quality rules write themselves, bad data gets isolated instantly.
Soda Core 4.0 — The Data Contracts Engine
Soda Core 4.0 introduces Data Contracts as the default way to define data quality for tables.
Instead of scattered checks and ad hoc rules, data quality is now defined by a clear, structured contract. This approach is easier to understand, easier to maintain, and reflects how teams actually work in production.
Why data contracts
Data Contracts are the best way to manage data quality because they bring everything together in one place. They explicitly define what a dataset is and what it guarantees, in a form that machines can execute.
Contract enforcement
Soda Core 4.0 provides scalable contract enforcement that validates both schema and data quality. Contracts run automatically as part of your pipelines and orchestration tools, making enforcement easy to integrate into your existing ecosystem.
You configure your data quality infrastructure as code, and Soda executes it. Out of the box, Soda Core supports 50+ built-in data quality checks, covering common and advanced validation patterns.
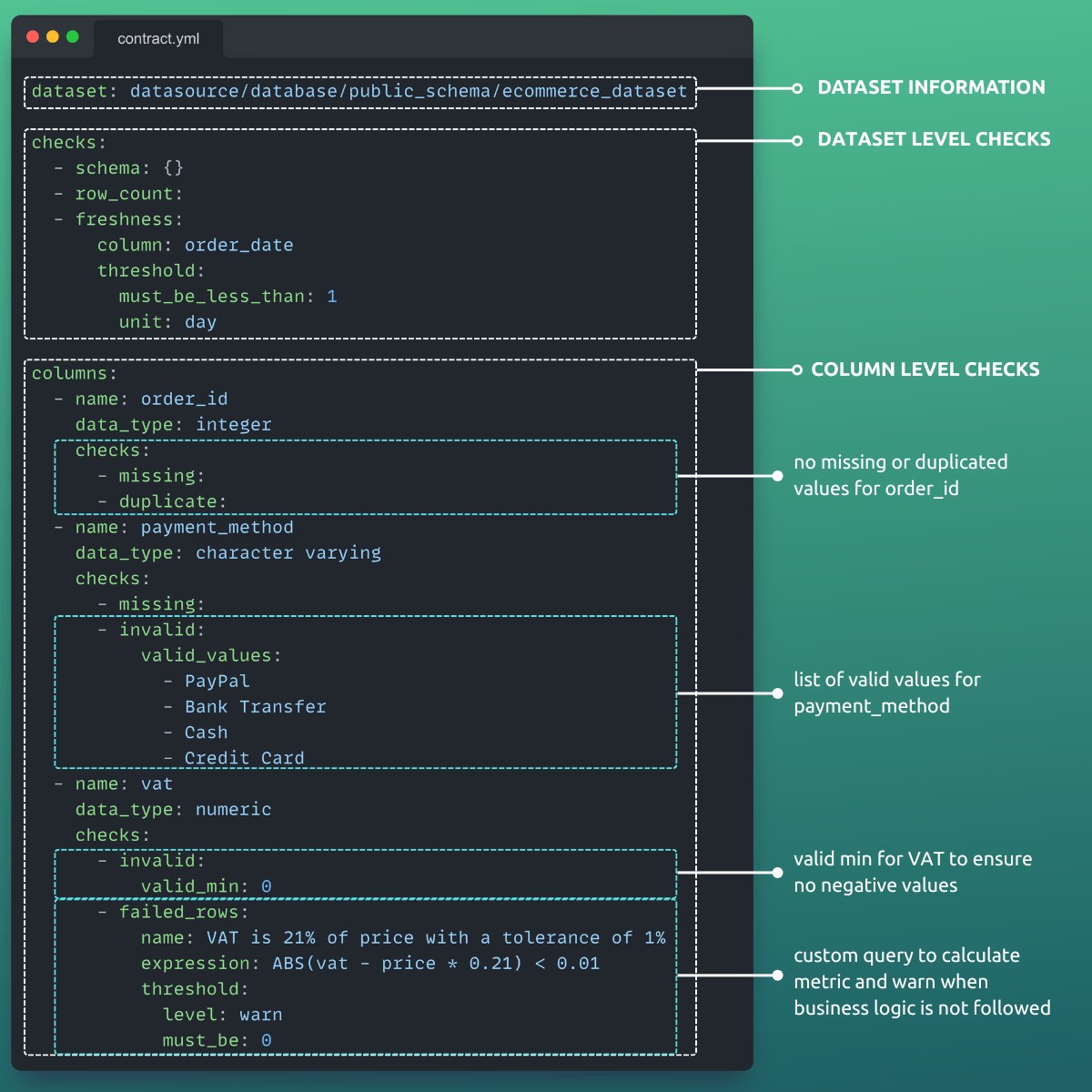
Data Contract syntax — What’s inside a data contract
A data contract can contain any metadata you want to manage as code, including:
Schema definitions
Data quality checks from the dataset to the column level
Everything that defines “what good data looks like” lives in one executable contract.
Broad data source support
Soda Core 4.0 works across a wide range of data sources, including Databricks, Snowflake, BigQuery, Postgres, DuckDB, Spark, SQL Server, Synapse, Athena, Fabric, and Redshift.
What’s changing from Soda Core v3
Soda Core is moving from the checks language to a Data Contracts–based syntax.
Data quality is no longer defined check by check, but contract by contract.
To make the transition easier, a conversion tool will be available to help migrate existing checks to the new Data Contracts format.
💡 Soda Cloud Users: If you are using Soda Cloud, a Customer Engineer will reach out to you to help schedule and support your migration to v4.
The initial release of Soda Core 4.0 does not yet support extracting failed records; support is planned for a future release.
Get started with Soda Core 4.0
Install Soda Core 4.0 and explore the documentation.
# generic install pip install soda-core>=4.0 # with the package that matches your data source e.g. postgres pip install soda-core-postgres>=4
Soda Cloud 4.0 — A unified, self-driving data quality platform
For too long, data quality has meant rules that lived in docs instead of production. Soda Cloud 4.0 changes that.
It unites AI-powered contract generation, feedback-driven anomaly detection, deep diagnostic capabilities, and a faster, cleaner interface into a single platform where quality rules write themselves, bad data gets isolated instantly, and teams spend less time configuring and more time leveraging their data.
Data Contracts in production, in one click
Soda Cloud 4.0 makes Data Contracts easy to create, collaborate on, and enforce in production. Contracts are no longer static definitions, but living assets that business and engineering teams can author together, evolve safely, and deploy with confidence.
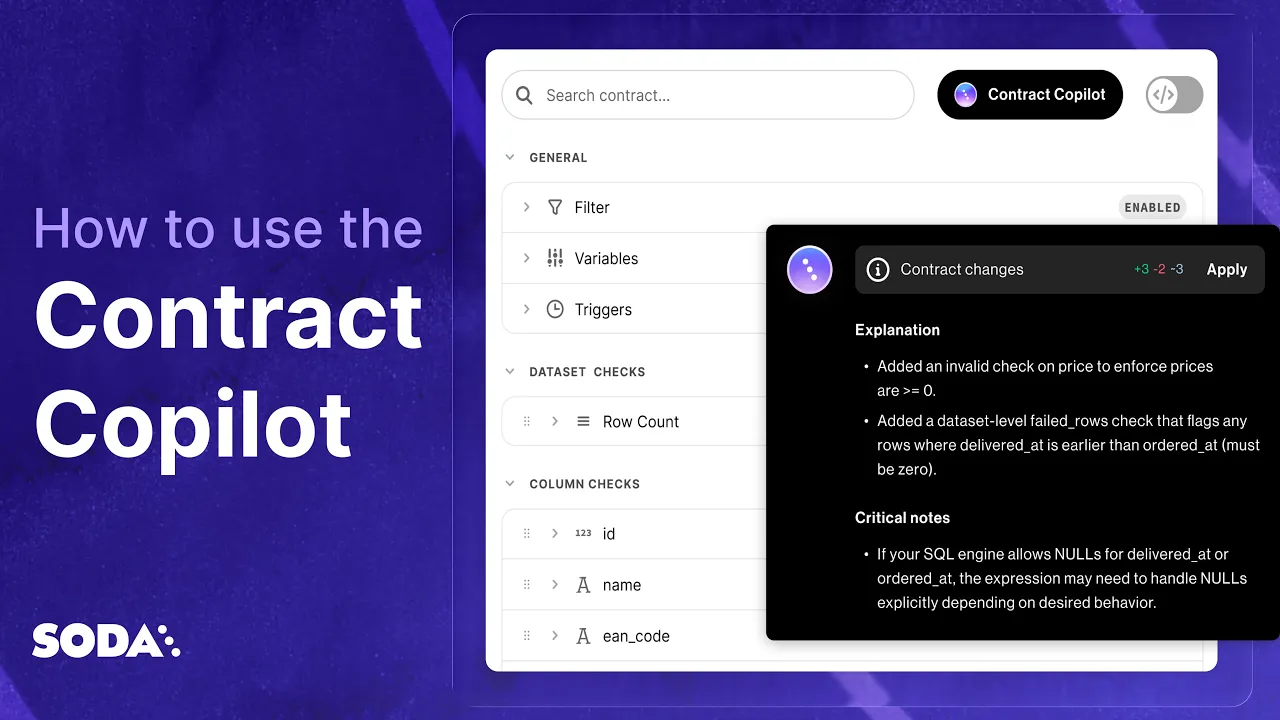
Contract Copilot
Contract Copilot makes it easy to get started with Data Contracts. It automatically generates contracts for existing datasets, and lets teams use plain English to create, refine rules and understand what is inside a data contract.
Collaborative Data Contracts
Data Contracts are designed to be shared. Soda Cloud lets business and technical users co-author contracts from their preferred tools, engineers as code and business users in the UI, removing handoffs and duplicated work. Everyone works on the same source of truth.
Data Contract Requests and Approvals
Any change to a Data Contract follow clear request and approval flows. Teams can review updates, get notified, and approve changes with full visibility.
Data Contract History
Every contract change is versioned and visible directly in the UI. Teams can review the full history of a contract and understand how quality expectations have changed over time.
Smarter anomaly detection, by default
It should be virtually impossible for an issue to slip through. Soda learns faster, reacts to feedback, and focuses on anomalies that actually matter.
Smarter Anomaly Treatment
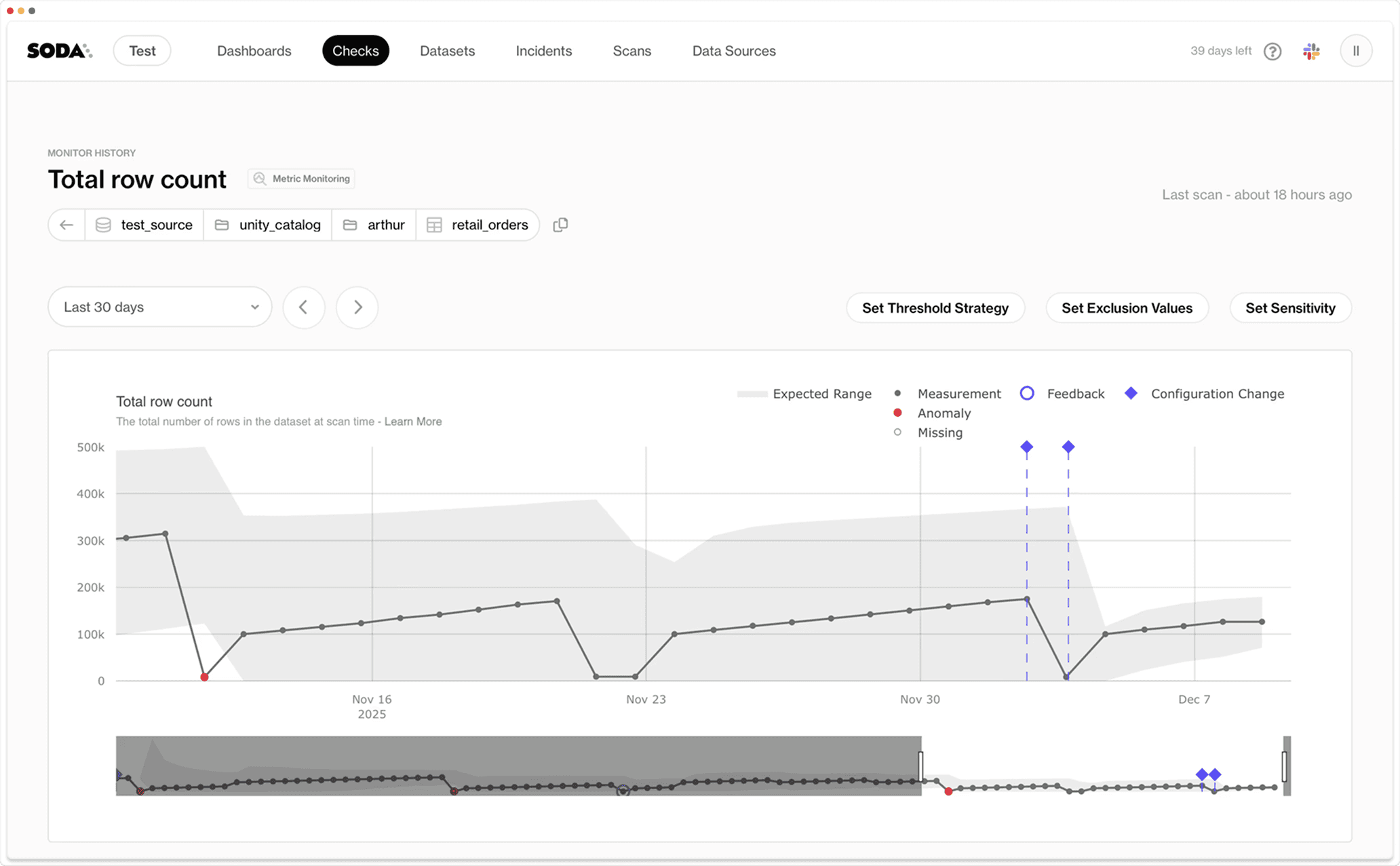
Smart Anomaly Treatment is a new, more adaptive detection approach. It automatically selects which historical data quality metrics to use when retraining its algorithms. It learns faster from data, adapts even when no human feedback is available, and reduces noise by prioritizing meaningful anomalies.
Historical Metrics
Teams can retroactively compute up to 365 days of historical quality metrics with a single click, making it easy to understand trends and seasonality.
Feedback-Driven Detection
Anomaly detection improves over time. Teams can flag false positives, helping the system focus on the issues that actually matter.
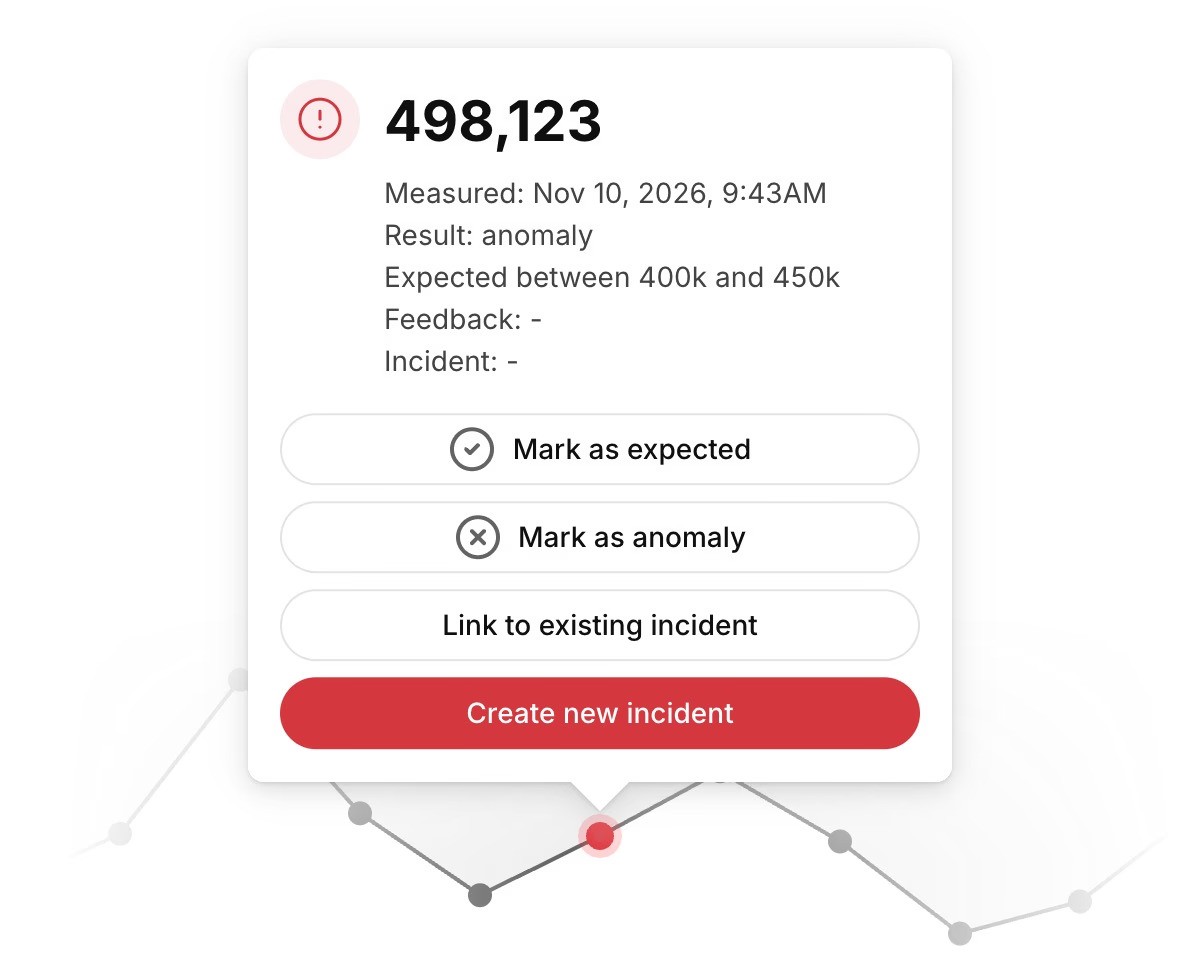
Record-level Anomaly Detection
Record-level anomaly detection provides instant coverage across all columns, rows, and segments, without configuration. It surfaces changes in missing values, duplicates, category distributions, proportions, correlations between columns, and segment-level behavior.
💡 Record-level Anomaly Detection is available only on Enterprise plans.
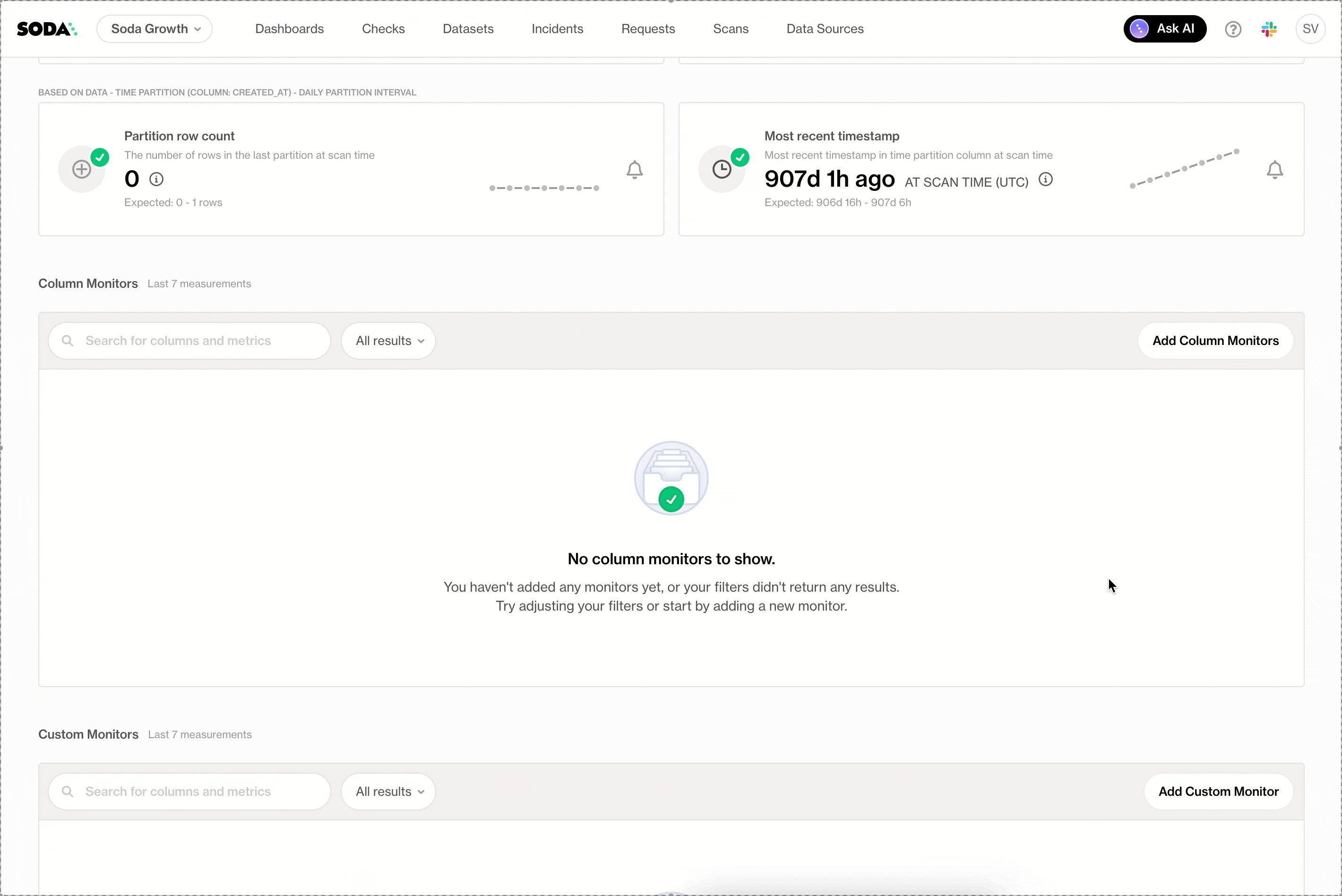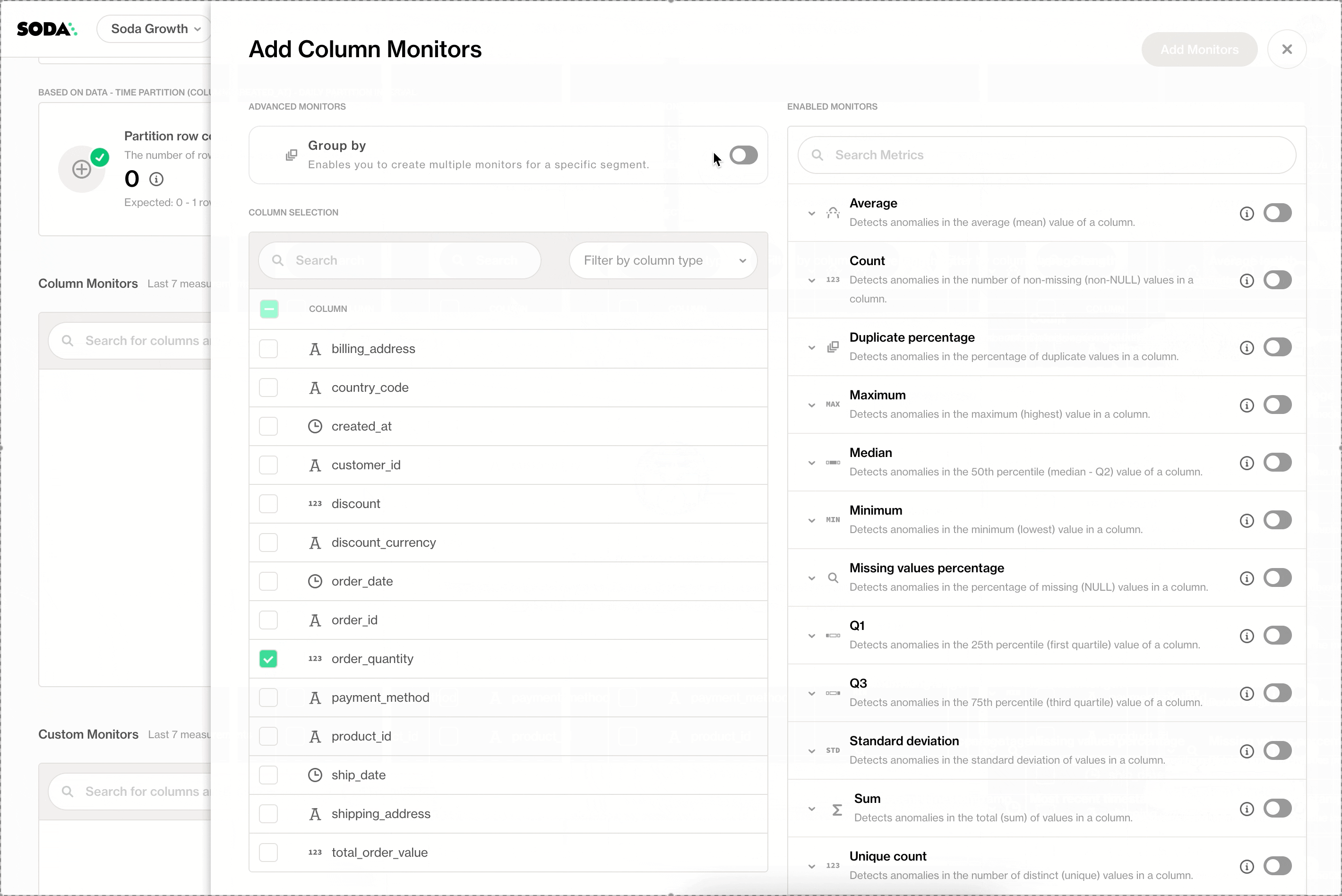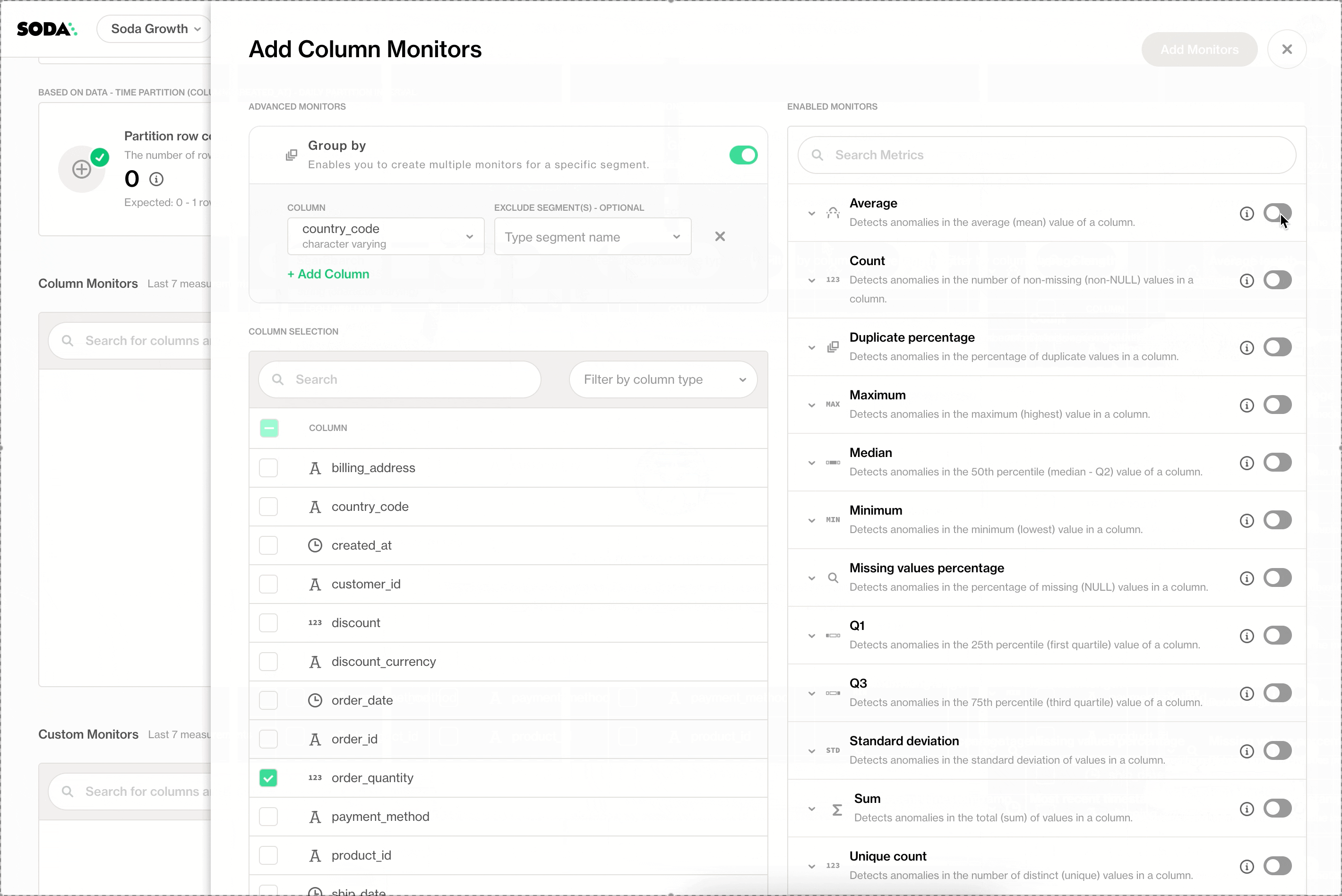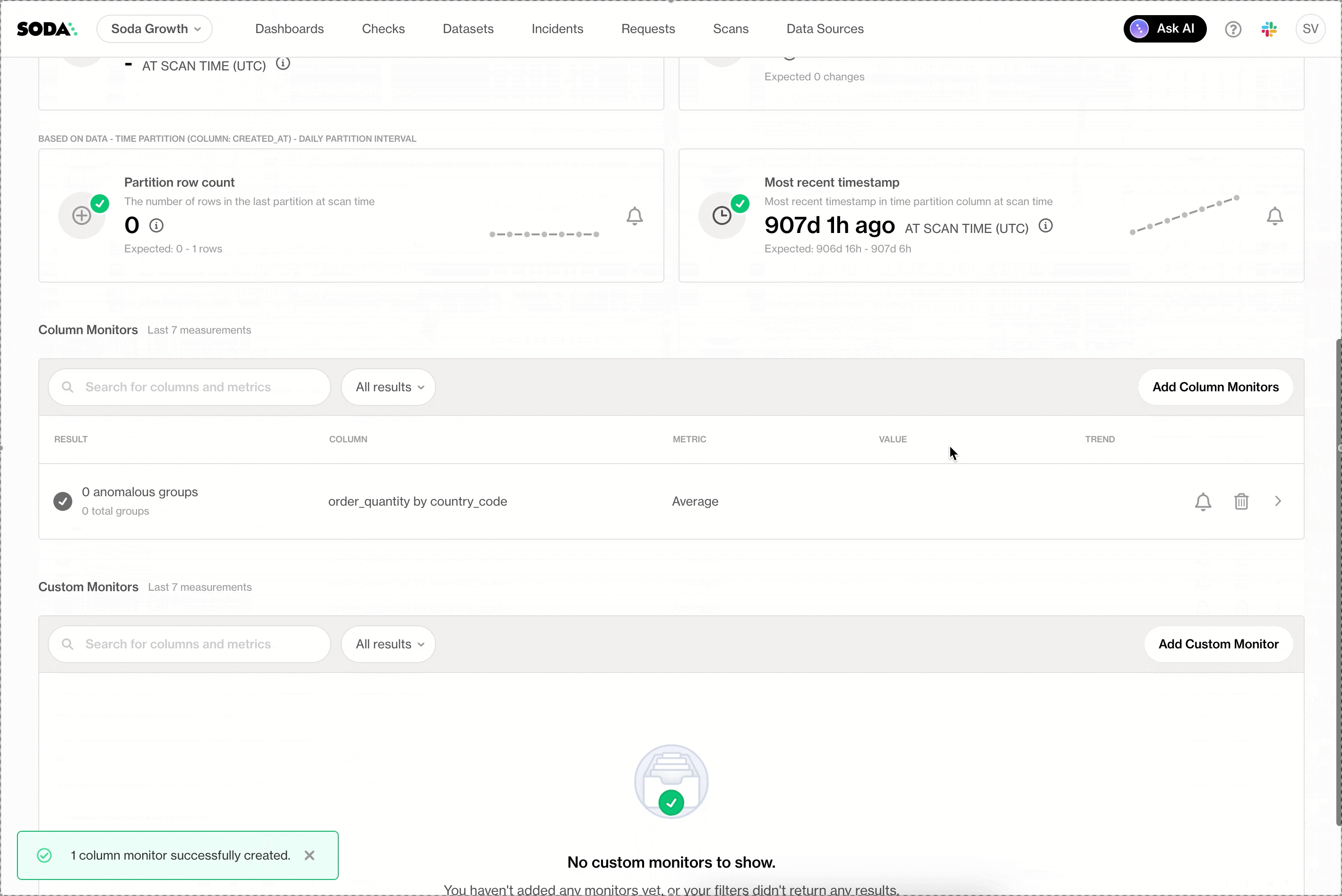
Group-by Monitors
Group-by monitors allow teams to track data quality metrics per segment instead of per column. For example, monitoring values by region, status, or time period reveals issues that would otherwise stay hidden.
Custom SQL Monitors
Custom SQL monitors let teams define their own monitoring logic using SQL, making it possible to express advanced or domain-specific quality rules.
Store failed records directly in your data warehouse
Store every scan result and every failed row directly in your data warehouse. From a single failed check, teams can jump straight to impacted rows, related columns, and historical trends.
Diagnostics Warehouse
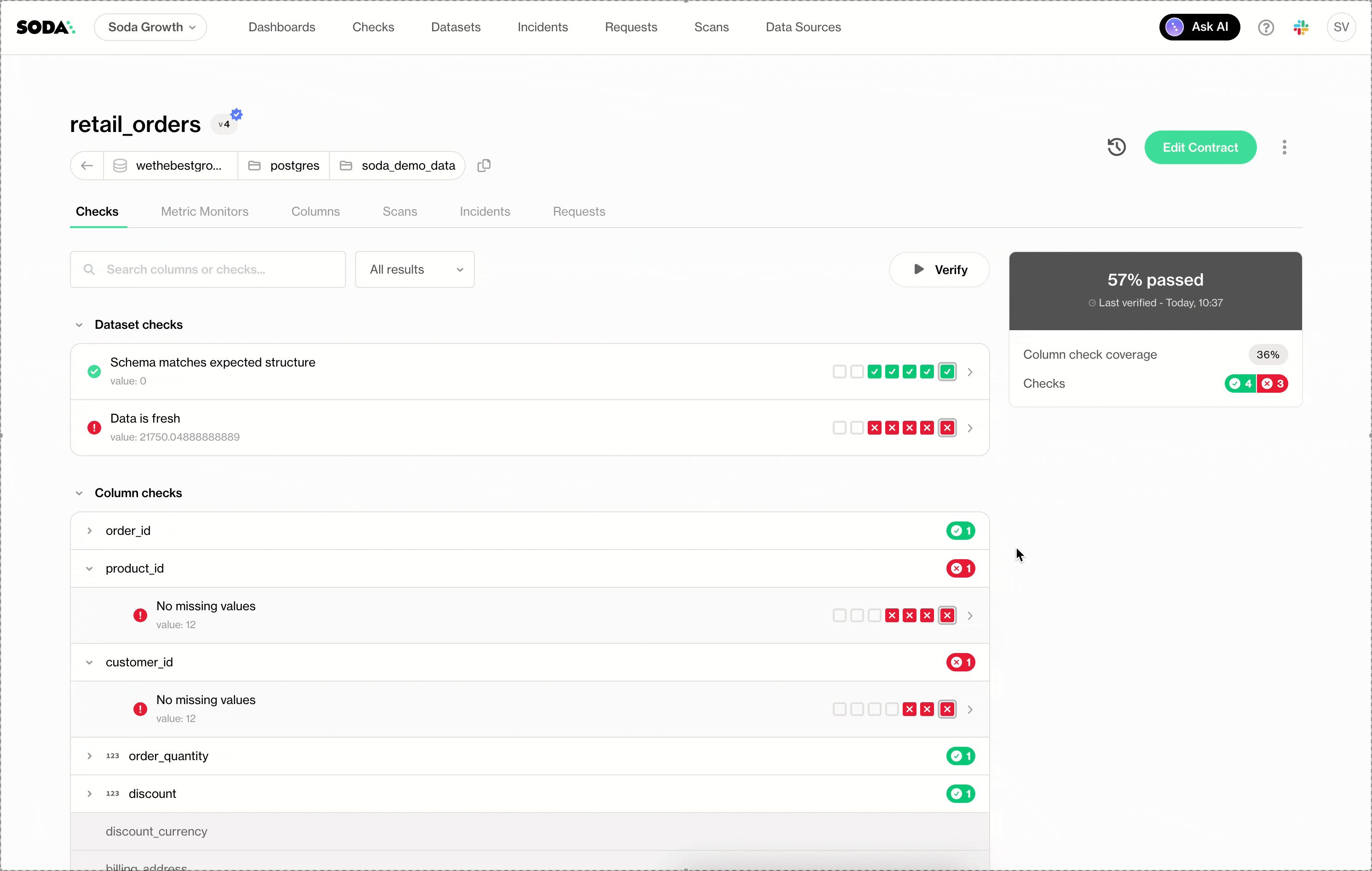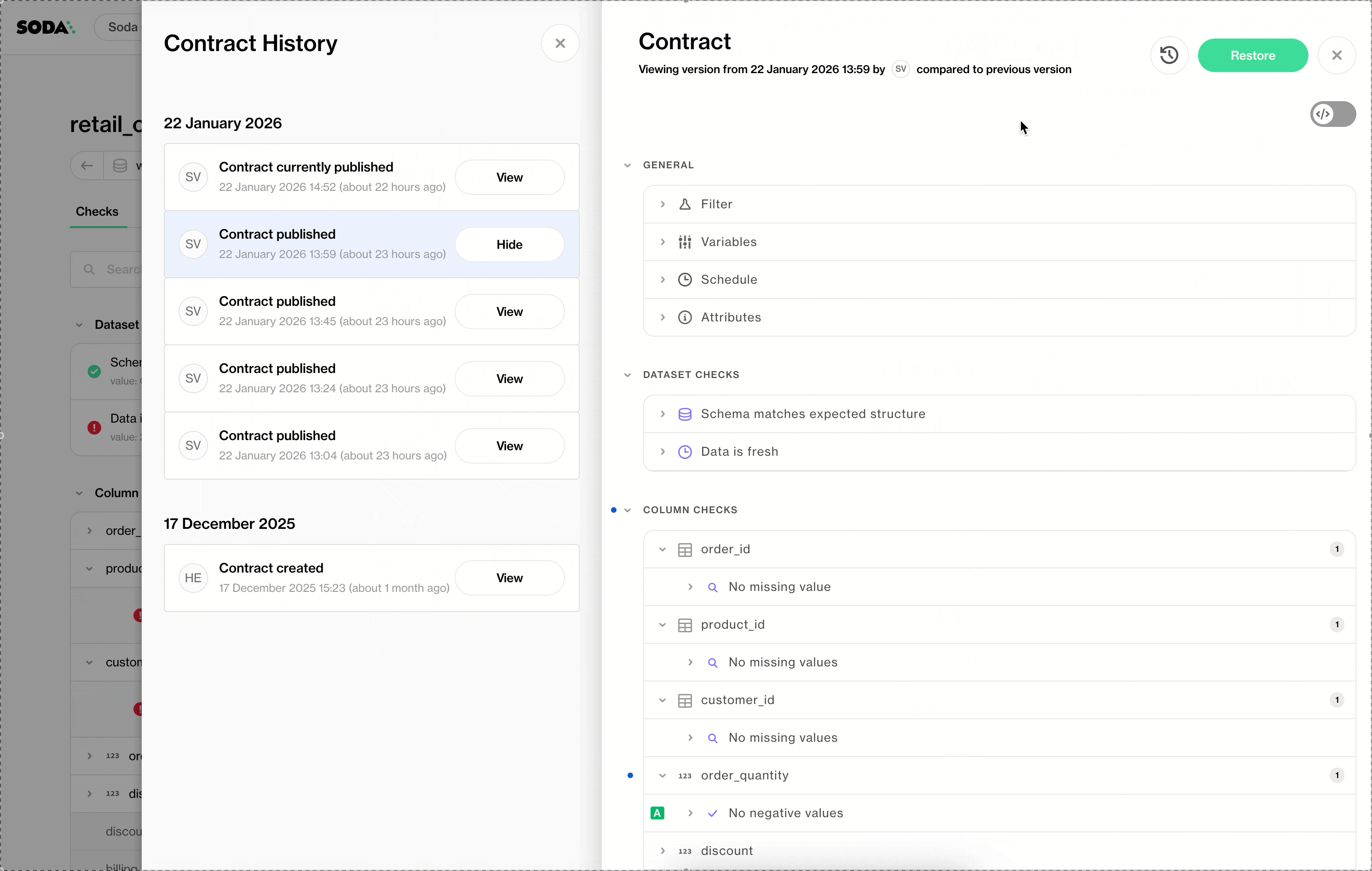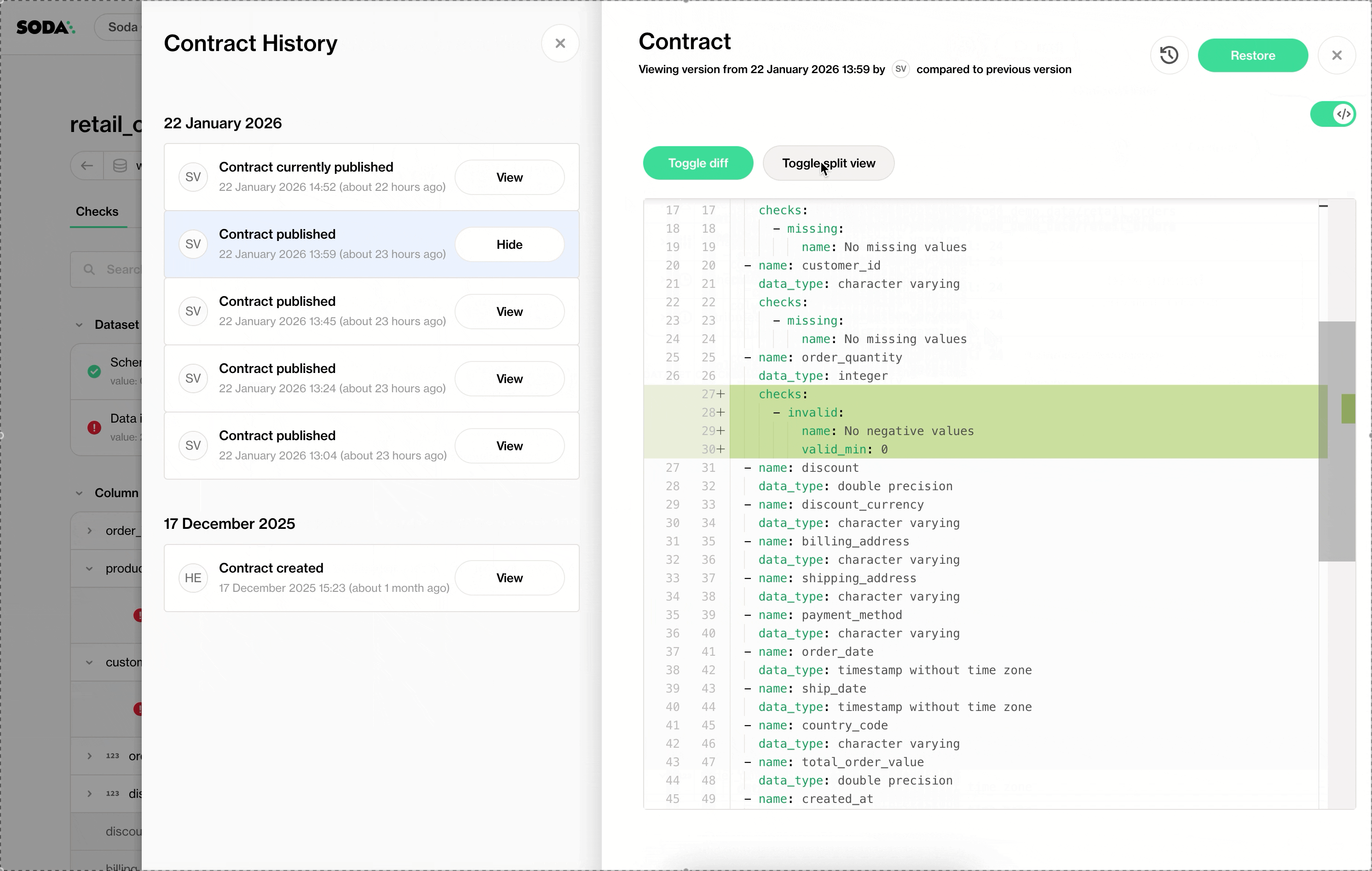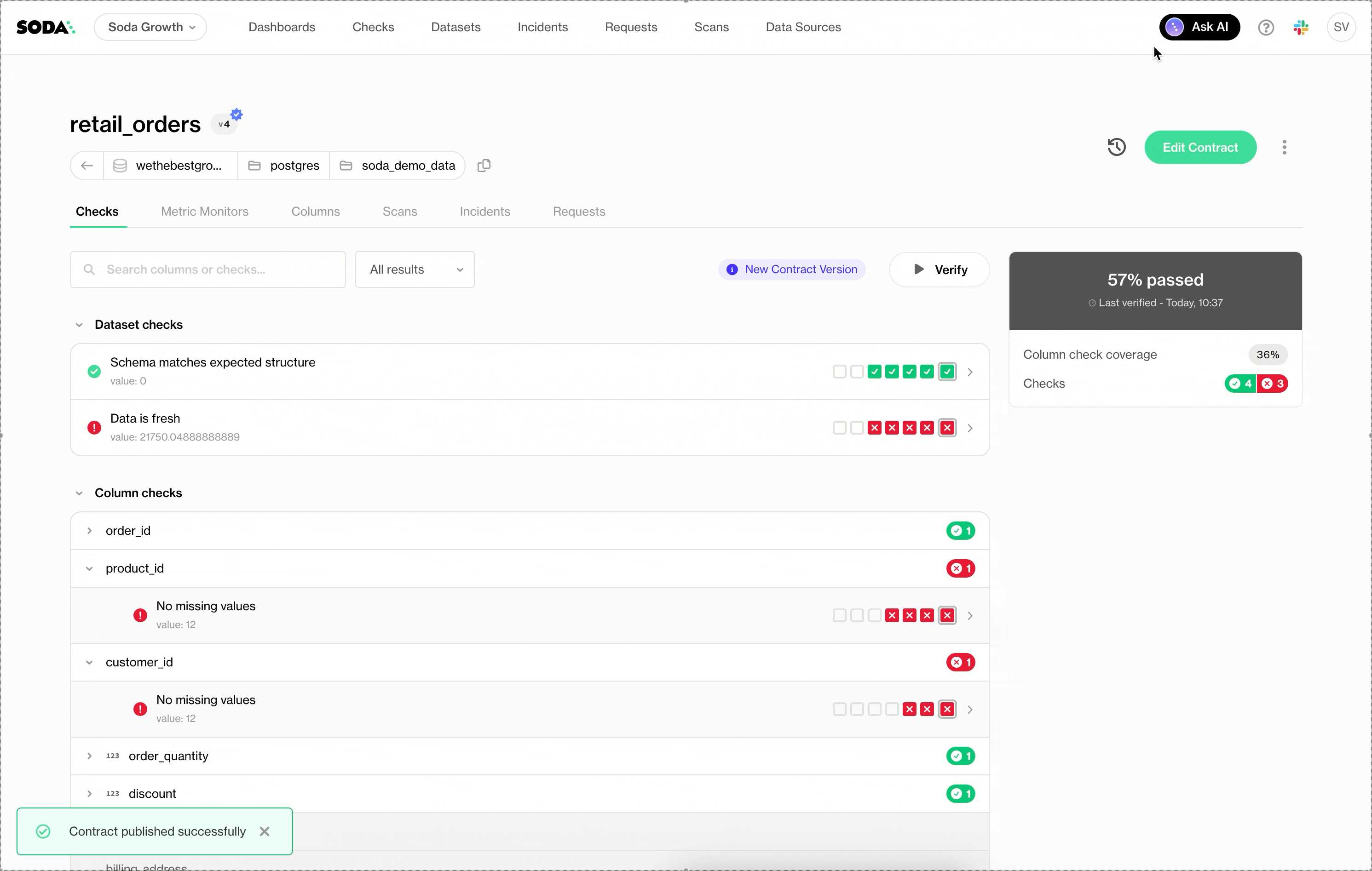
The Diagnostics Warehouse gives teams a clear, detailed view of scan results, checks, and failures. All results, including failed rows, are stored directly in your own data warehouse, with data and metadata already cleanly structured. This makes it easy to move from detection to root cause and to build custom reporting and dashboards in your BI tools using the full picture of your data quality.
💡Diagnostic Warehouse is available only on Enterprise plans.
A cleaner user experience
Soda Cloud 4.0 improves the day-to-day experience of working with data quality. Setup is faster, dashboards are easier to navigate, and filtering is more powerful.
Simplified Data Source Onboarding
Data source onboarding is faster and more straightforward, reducing setup time and getting teams to insights quicker.
Improved Dashboard Filtering
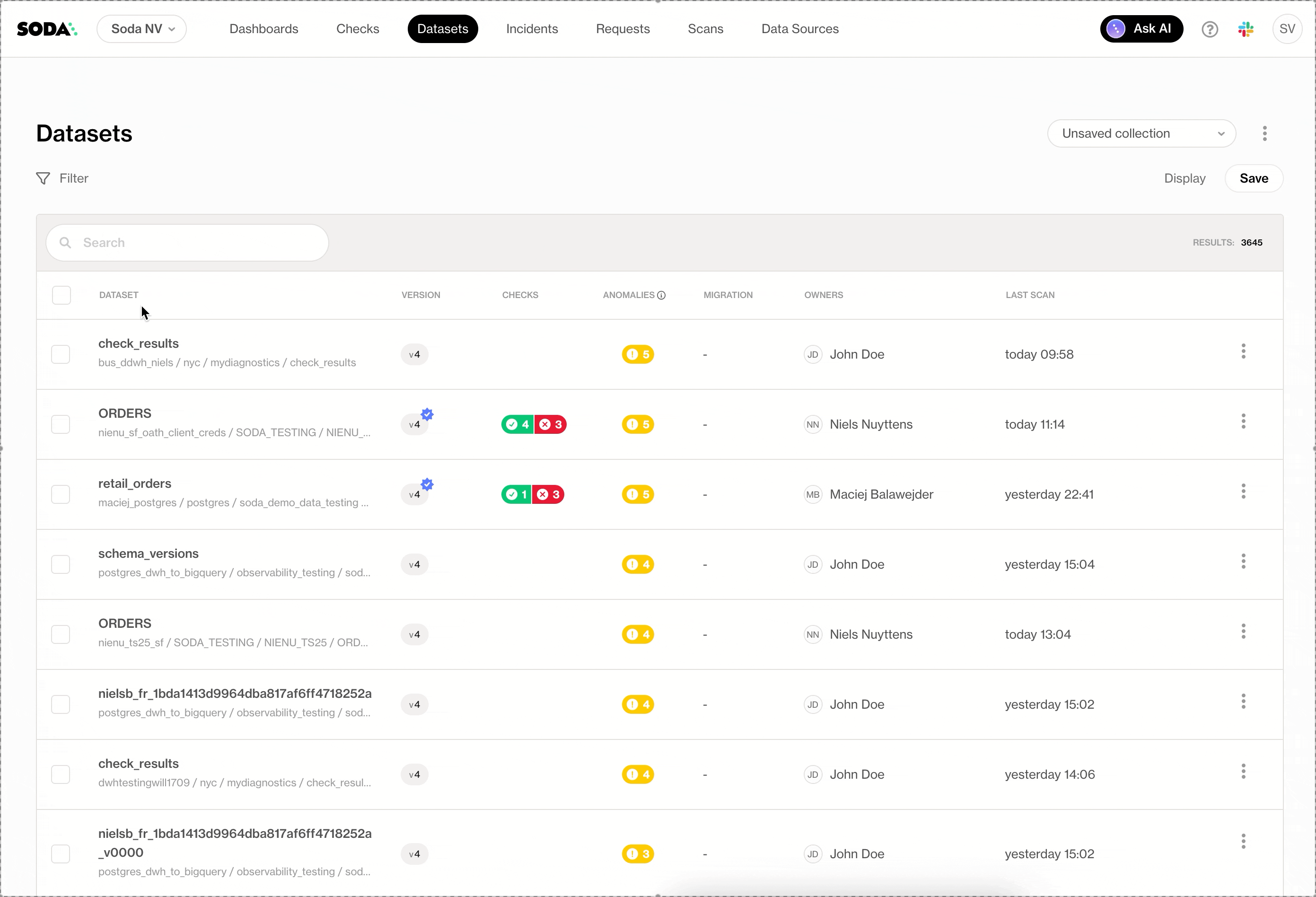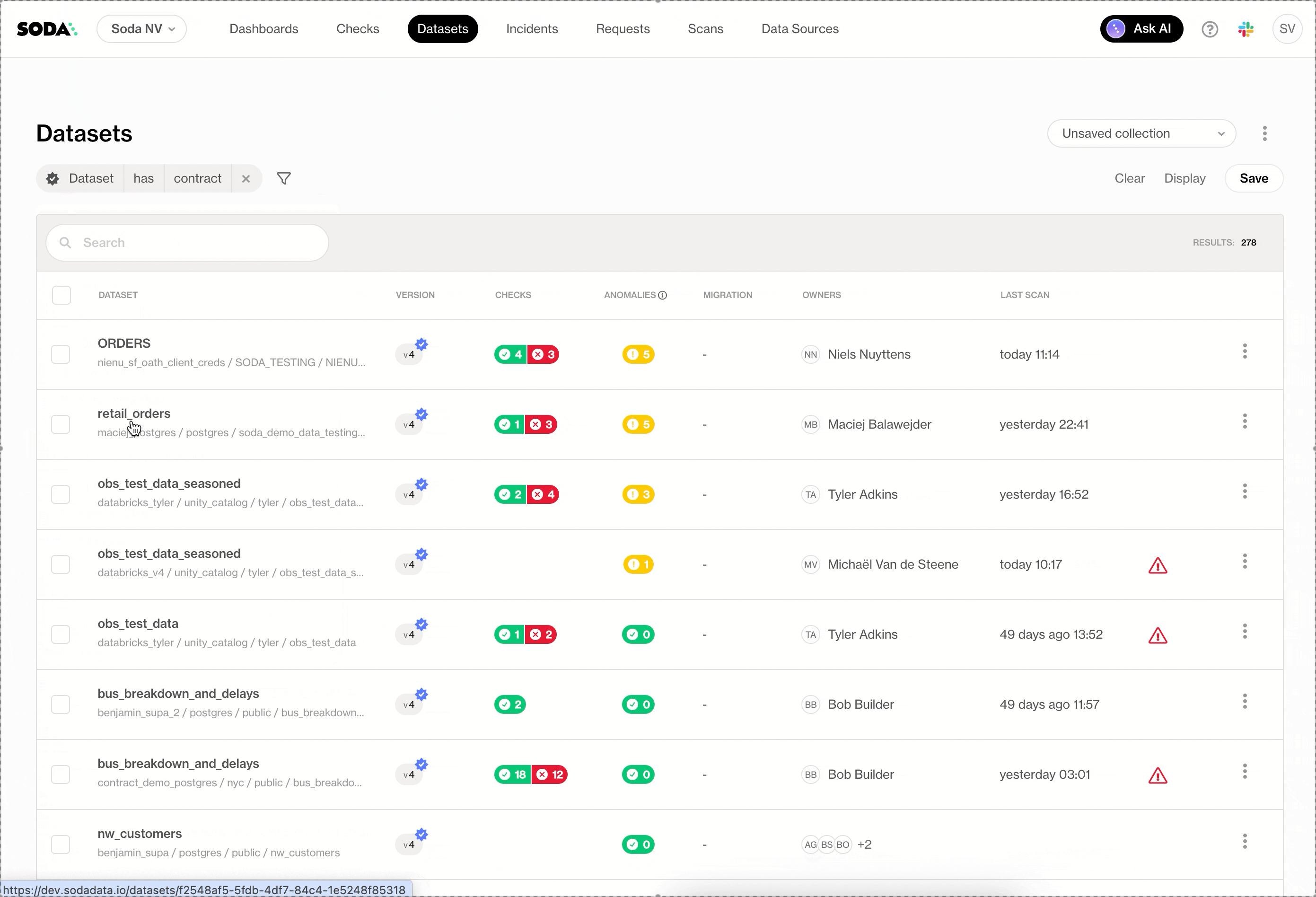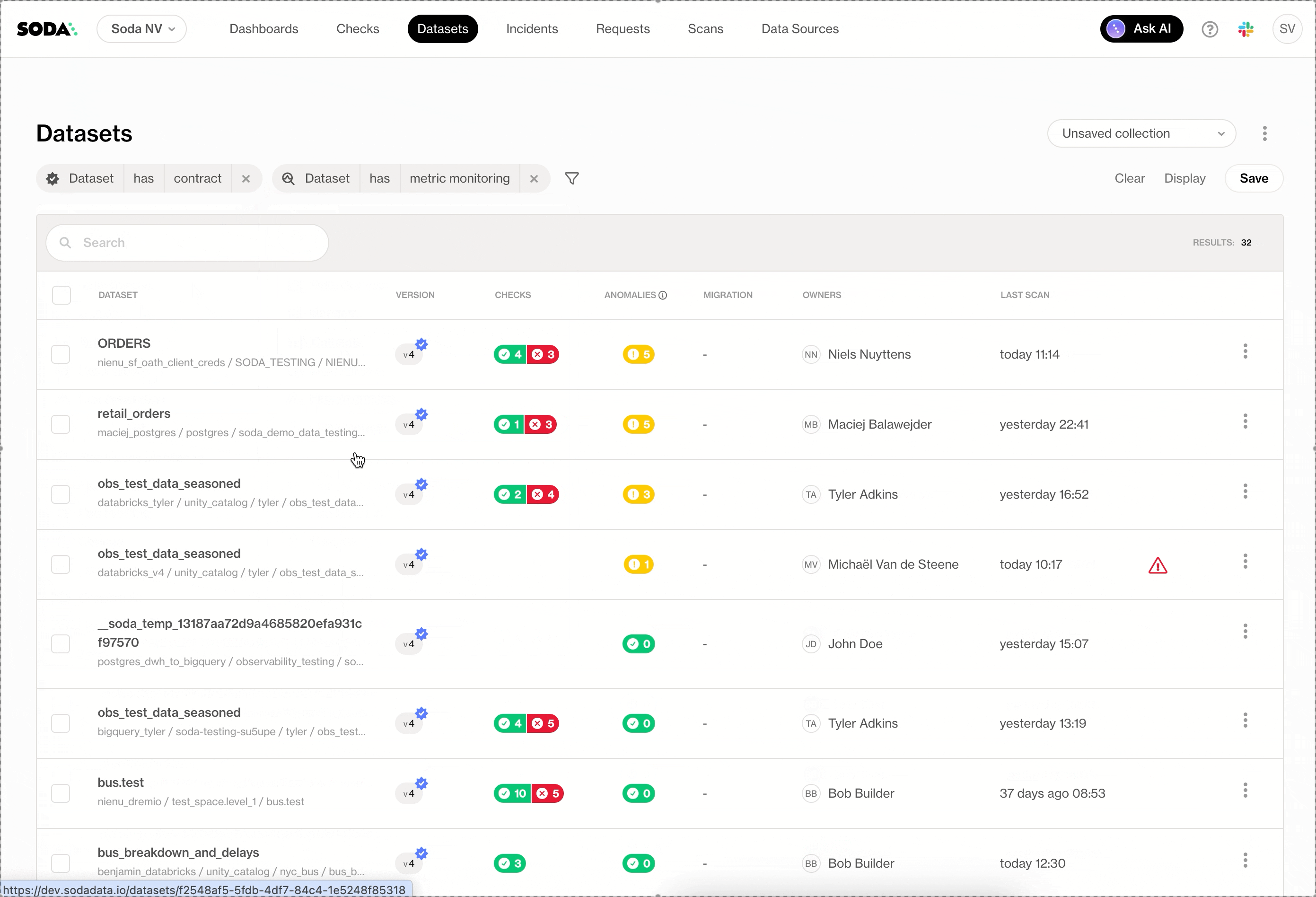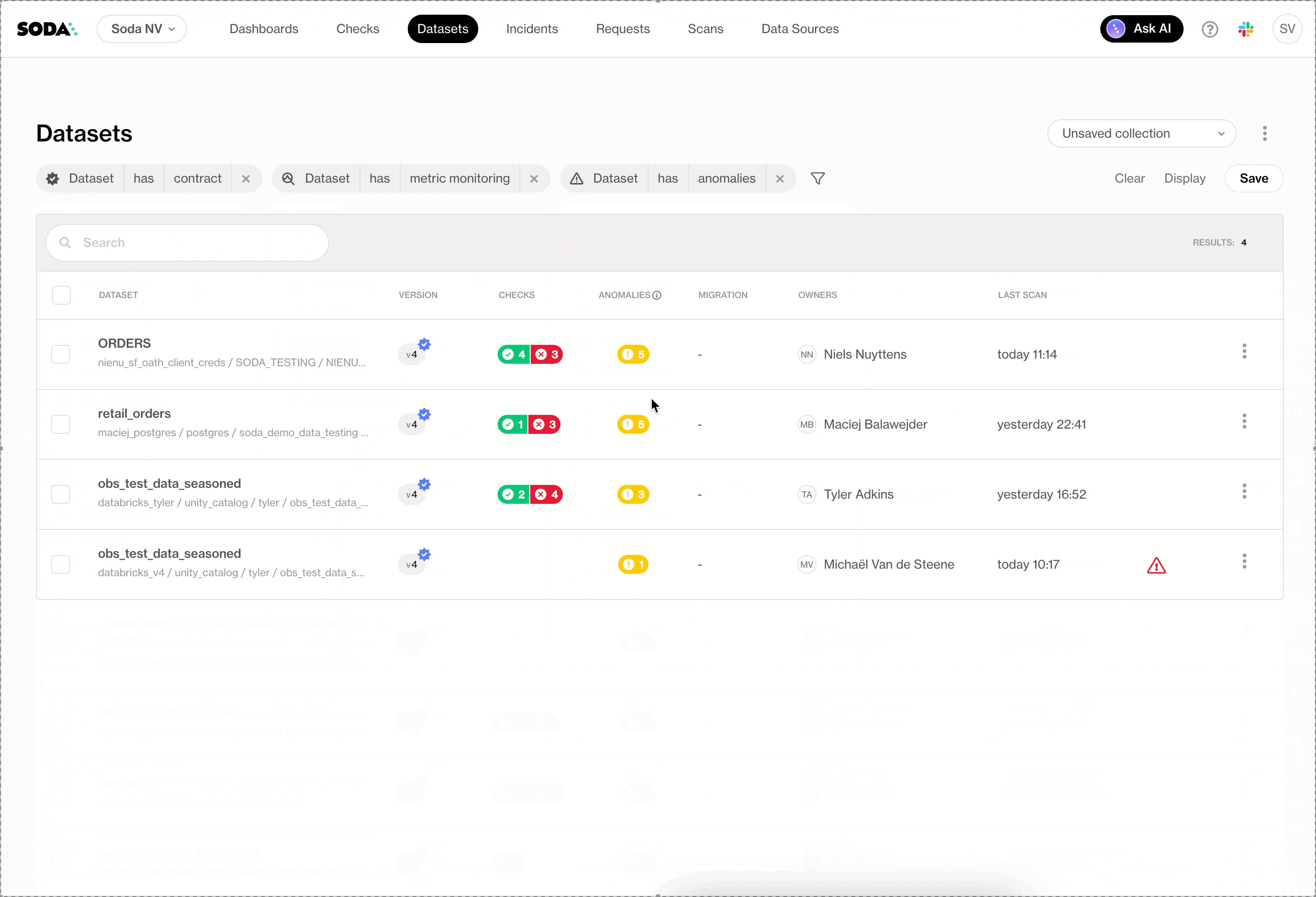
Dashboards now offer cleaner, more flexible filtering. Teams can filter using their own business dimensions, search within filters, use operators, and rely on fuzzy search for quick exploration, without cluttering the UI.
Towards a fully self-driving data quality platform
Soda 4.0 marks the beginning of self-driving data quality. Data quality moves from manual rules and reactive fixes to systems that define expectations, enforce them automatically, and continuously improve. This is the direction Soda is building towards.
Ready to see it in action?
Request a demo or start a free account today and check out all the new updates on Soda Cloud 4.0.
For a long time, data quality has lived as aspirational rules in documents humans could read, but machines could not execute.
Data teams have spent gazillions of hours in Zoom meetings, circle-backs, and "as per my last email" back-and-forths trying to agree on which business rules a field should comply with, only to then spend weeks waiting for engineers to turn those rules into code.
All of this is about to change. It no longer makes sense to separate rule definition from enforcement. Businesses should write rules in natural language, and AI should automatically translate them into code, so collaboration with engineers is simple and fast.
It should be virtually impossible for a table to go untested. Every table should start with a baseline Data Contract, created from dataset context, metadata, and catalog information. Contracts that can later be refined through business and engineering workflows. AI-powered data observability should run automatically, so even if we forget to add a descriptive check, anomaly detection is always running in the background, alerting us to anything unusual.
Today, we introduce Soda 4.0: a unified data quality platform that does all of that. And more. It helps teams validate and continuously improve the quality of their data.
This is the beginning of a self-driving data quality platform.
Everything new in Soda 4.0
We are introducing a new data contracts engine and a unified cloud platform that brings observability, AI, and data quality enforcement together.
Soda Core 4.0 — Data Contracts Engine: An open-source engine that formalizes the standard for defining and executing data contracts. A clean, data-quality–first syntax supporting 50+ built-in check types.
Soda Cloud 4.0 — Unified, self-driving data quality platform: It unites AI-powered contract generation, feedback-driven anomaly detection, deep diagnostic capabilities, and a faster, cleaner interface into a single platform where quality rules write themselves, bad data gets isolated instantly.
Soda Core 4.0 — The Data Contracts Engine
Soda Core 4.0 introduces Data Contracts as the default way to define data quality for tables.
Instead of scattered checks and ad hoc rules, data quality is now defined by a clear, structured contract. This approach is easier to understand, easier to maintain, and reflects how teams actually work in production.
Why data contracts
Data Contracts are the best way to manage data quality because they bring everything together in one place. They explicitly define what a dataset is and what it guarantees, in a form that machines can execute.
Contract enforcement
Soda Core 4.0 provides scalable contract enforcement that validates both schema and data quality. Contracts run automatically as part of your pipelines and orchestration tools, making enforcement easy to integrate into your existing ecosystem.
You configure your data quality infrastructure as code, and Soda executes it. Out of the box, Soda Core supports 50+ built-in data quality checks, covering common and advanced validation patterns.
Data Contract syntax — What’s inside a data contract
A data contract can contain any metadata you want to manage as code, including:
Schema definitions
Data quality checks from the dataset to the column level
Everything that defines “what good data looks like” lives in one executable contract.
Broad data source support
Soda Core 4.0 works across a wide range of data sources, including Databricks, Snowflake, BigQuery, Postgres, DuckDB, Spark, SQL Server, Synapse, Athena, Fabric, and Redshift.
What’s changing from Soda Core v3
Soda Core is moving from the checks language to a Data Contracts–based syntax.
Data quality is no longer defined check by check, but contract by contract.
To make the transition easier, a conversion tool will be available to help migrate existing checks to the new Data Contracts format.
💡 Soda Cloud Users: If you are using Soda Cloud, a Customer Engineer will reach out to you to help schedule and support your migration to v4.
The initial release of Soda Core 4.0 does not yet support extracting failed records; support is planned for a future release.
Get started with Soda Core 4.0
Install Soda Core 4.0 and explore the documentation.
# generic install pip install soda-core>=4.0 # with the package that matches your data source e.g. postgres pip install soda-core-postgres>=4
Soda Cloud 4.0 — A unified, self-driving data quality platform
For too long, data quality has meant rules that lived in docs instead of production. Soda Cloud 4.0 changes that.
It unites AI-powered contract generation, feedback-driven anomaly detection, deep diagnostic capabilities, and a faster, cleaner interface into a single platform where quality rules write themselves, bad data gets isolated instantly, and teams spend less time configuring and more time leveraging their data.
Data Contracts in production, in one click
Soda Cloud 4.0 makes Data Contracts easy to create, collaborate on, and enforce in production. Contracts are no longer static definitions, but living assets that business and engineering teams can author together, evolve safely, and deploy with confidence.
Contract Copilot
Contract Copilot makes it easy to get started with Data Contracts. It automatically generates contracts for existing datasets, and lets teams use plain English to create, refine rules and understand what is inside a data contract.
Collaborative Data Contracts
Data Contracts are designed to be shared. Soda Cloud lets business and technical users co-author contracts from their preferred tools, engineers as code and business users in the UI, removing handoffs and duplicated work. Everyone works on the same source of truth.
Data Contract Requests and Approvals
Any change to a Data Contract follow clear request and approval flows. Teams can review updates, get notified, and approve changes with full visibility.
Data Contract History
Every contract change is versioned and visible directly in the UI. Teams can review the full history of a contract and understand how quality expectations have changed over time.
Smarter anomaly detection, by default
It should be virtually impossible for an issue to slip through. Soda learns faster, reacts to feedback, and focuses on anomalies that actually matter.
Smarter Anomaly Treatment
Smart Anomaly Treatment is a new, more adaptive detection approach. It automatically selects which historical data quality metrics to use when retraining its algorithms. It learns faster from data, adapts even when no human feedback is available, and reduces noise by prioritizing meaningful anomalies.
Historical Metrics
Teams can retroactively compute up to 365 days of historical quality metrics with a single click, making it easy to understand trends and seasonality.
Feedback-Driven Detection
Anomaly detection improves over time. Teams can flag false positives, helping the system focus on the issues that actually matter.
Record-level Anomaly Detection
Record-level anomaly detection provides instant coverage across all columns, rows, and segments, without configuration. It surfaces changes in missing values, duplicates, category distributions, proportions, correlations between columns, and segment-level behavior.
💡 Record-level Anomaly Detection is available only on Enterprise plans.
Group-by Monitors
Group-by monitors allow teams to track data quality metrics per segment instead of per column. For example, monitoring values by region, status, or time period reveals issues that would otherwise stay hidden.
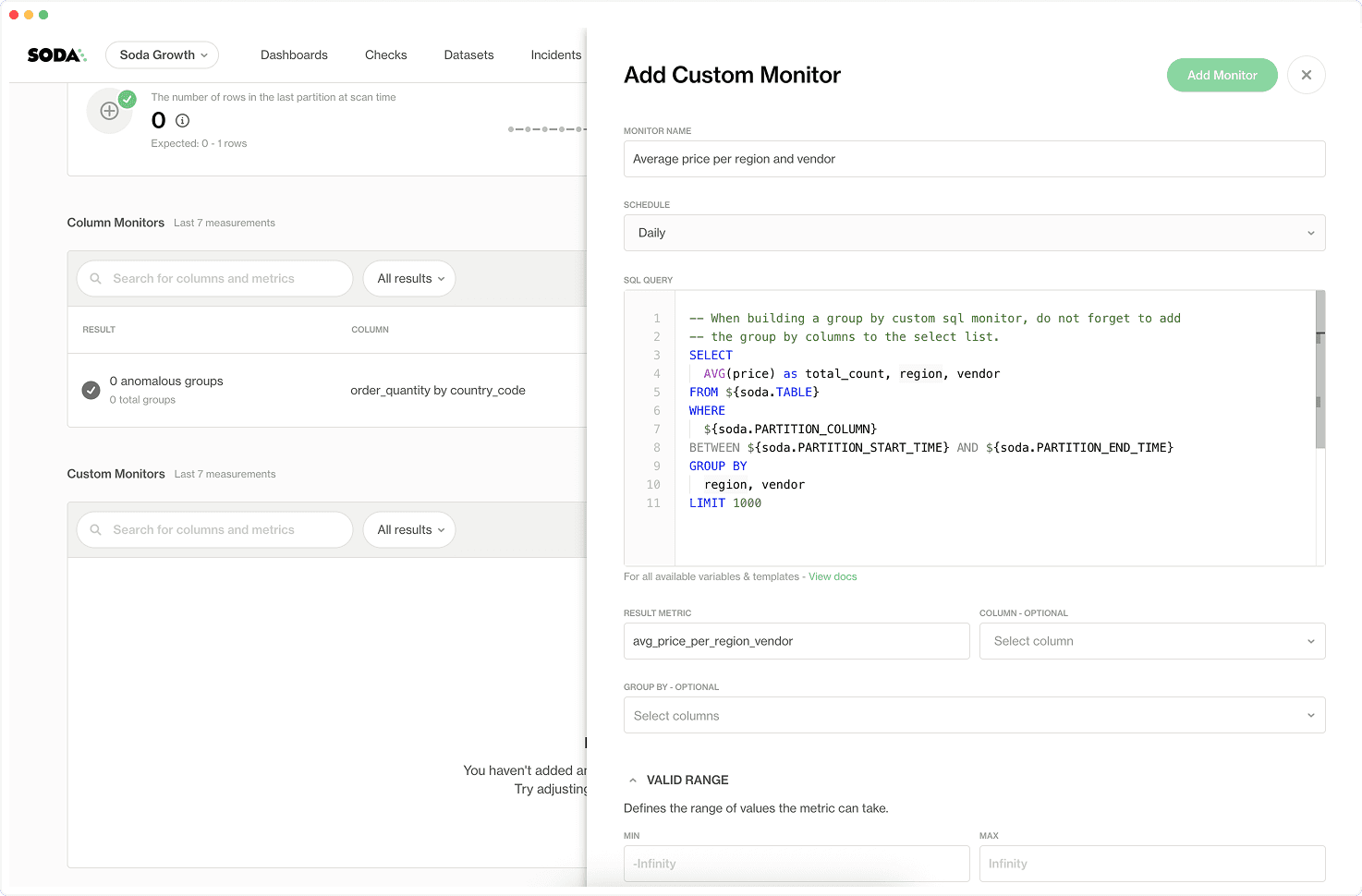
Custom SQL Monitors
Custom SQL monitors let teams define their own monitoring logic using SQL, making it possible to express advanced or domain-specific quality rules.
Store failed records directly in your data warehouse
Store every scan result and every failed row directly in your data warehouse. From a single failed check, teams can jump straight to impacted rows, related columns, and historical trends.
Diagnostics Warehouse
The Diagnostics Warehouse gives teams a clear, detailed view of scan results, checks, and failures. All results, including failed rows, are stored directly in your own data warehouse, with data and metadata already cleanly structured. This makes it easy to move from detection to root cause and to build custom reporting and dashboards in your BI tools using the full picture of your data quality.
💡Diagnostic Warehouse is available only on Enterprise plans.
A cleaner user experience
Soda Cloud 4.0 improves the day-to-day experience of working with data quality. Setup is faster, dashboards are easier to navigate, and filtering is more powerful.
Simplified Data Source Onboarding
Data source onboarding is faster and more straightforward, reducing setup time and getting teams to insights quicker.
Improved Dashboard Filtering
Dashboards now offer cleaner, more flexible filtering. Teams can filter using their own business dimensions, search within filters, use operators, and rely on fuzzy search for quick exploration, without cluttering the UI.
Towards a fully self-driving data quality platform
Soda 4.0 marks the beginning of self-driving data quality. Data quality moves from manual rules and reactive fixes to systems that define expectations, enforce them automatically, and continuously improve. This is the direction Soda is building towards.
Ready to see it in action?
Request a demo or start a free account today and check out all the new updates on Soda Cloud 4.0.
For a long time, data quality has lived as aspirational rules in documents humans could read, but machines could not execute.
Data teams have spent gazillions of hours in Zoom meetings, circle-backs, and "as per my last email" back-and-forths trying to agree on which business rules a field should comply with, only to then spend weeks waiting for engineers to turn those rules into code.
All of this is about to change. It no longer makes sense to separate rule definition from enforcement. Businesses should write rules in natural language, and AI should automatically translate them into code, so collaboration with engineers is simple and fast.
It should be virtually impossible for a table to go untested. Every table should start with a baseline Data Contract, created from dataset context, metadata, and catalog information. Contracts that can later be refined through business and engineering workflows. AI-powered data observability should run automatically, so even if we forget to add a descriptive check, anomaly detection is always running in the background, alerting us to anything unusual.
Today, we introduce Soda 4.0: a unified data quality platform that does all of that. And more. It helps teams validate and continuously improve the quality of their data.
This is the beginning of a self-driving data quality platform.
Everything new in Soda 4.0
We are introducing a new data contracts engine and a unified cloud platform that brings observability, AI, and data quality enforcement together.
Soda Core 4.0 — Data Contracts Engine: An open-source engine that formalizes the standard for defining and executing data contracts. A clean, data-quality–first syntax supporting 50+ built-in check types.
Soda Cloud 4.0 — Unified, self-driving data quality platform: It unites AI-powered contract generation, feedback-driven anomaly detection, deep diagnostic capabilities, and a faster, cleaner interface into a single platform where quality rules write themselves, bad data gets isolated instantly.
Soda Core 4.0 — The Data Contracts Engine
Soda Core 4.0 introduces Data Contracts as the default way to define data quality for tables.
Instead of scattered checks and ad hoc rules, data quality is now defined by a clear, structured contract. This approach is easier to understand, easier to maintain, and reflects how teams actually work in production.
Why data contracts
Data Contracts are the best way to manage data quality because they bring everything together in one place. They explicitly define what a dataset is and what it guarantees, in a form that machines can execute.
Contract enforcement
Soda Core 4.0 provides scalable contract enforcement that validates both schema and data quality. Contracts run automatically as part of your pipelines and orchestration tools, making enforcement easy to integrate into your existing ecosystem.
You configure your data quality infrastructure as code, and Soda executes it. Out of the box, Soda Core supports 50+ built-in data quality checks, covering common and advanced validation patterns.
Data Contract syntax — What’s inside a data contract
A data contract can contain any metadata you want to manage as code, including:
Schema definitions
Data quality checks from the dataset to the column level
Everything that defines “what good data looks like” lives in one executable contract.
Broad data source support
Soda Core 4.0 works across a wide range of data sources, including Databricks, Snowflake, BigQuery, Postgres, DuckDB, Spark, SQL Server, Synapse, Athena, Fabric, and Redshift.
What’s changing from Soda Core v3
Soda Core is moving from the checks language to a Data Contracts–based syntax.
Data quality is no longer defined check by check, but contract by contract.
To make the transition easier, a conversion tool will be available to help migrate existing checks to the new Data Contracts format.
💡 Soda Cloud Users: If you are using Soda Cloud, a Customer Engineer will reach out to you to help schedule and support your migration to v4.
The initial release of Soda Core 4.0 does not yet support extracting failed records; support is planned for a future release.
Get started with Soda Core 4.0
Install Soda Core 4.0 and explore the documentation.
# generic install pip install soda-core>=4.0 # with the package that matches your data source e.g. postgres pip install soda-core-postgres>=4
Soda Cloud 4.0 — A unified, self-driving data quality platform
For too long, data quality has meant rules that lived in docs instead of production. Soda Cloud 4.0 changes that.
It unites AI-powered contract generation, feedback-driven anomaly detection, deep diagnostic capabilities, and a faster, cleaner interface into a single platform where quality rules write themselves, bad data gets isolated instantly, and teams spend less time configuring and more time leveraging their data.
Data Contracts in production, in one click
Soda Cloud 4.0 makes Data Contracts easy to create, collaborate on, and enforce in production. Contracts are no longer static definitions, but living assets that business and engineering teams can author together, evolve safely, and deploy with confidence.
Contract Copilot
Contract Copilot makes it easy to get started with Data Contracts. It automatically generates contracts for existing datasets, and lets teams use plain English to create, refine rules and understand what is inside a data contract.
Collaborative Data Contracts
Data Contracts are designed to be shared. Soda Cloud lets business and technical users co-author contracts from their preferred tools, engineers as code and business users in the UI, removing handoffs and duplicated work. Everyone works on the same source of truth.
Data Contract Requests and Approvals
Any change to a Data Contract follow clear request and approval flows. Teams can review updates, get notified, and approve changes with full visibility.
Data Contract History
Every contract change is versioned and visible directly in the UI. Teams can review the full history of a contract and understand how quality expectations have changed over time.
Smarter anomaly detection, by default
It should be virtually impossible for an issue to slip through. Soda learns faster, reacts to feedback, and focuses on anomalies that actually matter.
Smarter Anomaly Treatment
Smart Anomaly Treatment is a new, more adaptive detection approach. It automatically selects which historical data quality metrics to use when retraining its algorithms. It learns faster from data, adapts even when no human feedback is available, and reduces noise by prioritizing meaningful anomalies.
Historical Metrics
Teams can retroactively compute up to 365 days of historical quality metrics with a single click, making it easy to understand trends and seasonality.
Feedback-Driven Detection
Anomaly detection improves over time. Teams can flag false positives, helping the system focus on the issues that actually matter.
Record-level Anomaly Detection
Record-level anomaly detection provides instant coverage across all columns, rows, and segments, without configuration. It surfaces changes in missing values, duplicates, category distributions, proportions, correlations between columns, and segment-level behavior.
💡 Record-level Anomaly Detection is available only on Enterprise plans.
Group-by Monitors
Group-by monitors allow teams to track data quality metrics per segment instead of per column. For example, monitoring values by region, status, or time period reveals issues that would otherwise stay hidden.
Custom SQL Monitors
Custom SQL monitors let teams define their own monitoring logic using SQL, making it possible to express advanced or domain-specific quality rules.
Store failed records directly in your data warehouse
Store every scan result and every failed row directly in your data warehouse. From a single failed check, teams can jump straight to impacted rows, related columns, and historical trends.
Diagnostics Warehouse
The Diagnostics Warehouse gives teams a clear, detailed view of scan results, checks, and failures. All results, including failed rows, are stored directly in your own data warehouse, with data and metadata already cleanly structured. This makes it easy to move from detection to root cause and to build custom reporting and dashboards in your BI tools using the full picture of your data quality.
💡Diagnostic Warehouse is available only on Enterprise plans.
A cleaner user experience
Soda Cloud 4.0 improves the day-to-day experience of working with data quality. Setup is faster, dashboards are easier to navigate, and filtering is more powerful.
Simplified Data Source Onboarding
Data source onboarding is faster and more straightforward, reducing setup time and getting teams to insights quicker.
Improved Dashboard Filtering
Dashboards now offer cleaner, more flexible filtering. Teams can filter using their own business dimensions, search within filters, use operators, and rely on fuzzy search for quick exploration, without cluttering the UI.
Towards a fully self-driving data quality platform
Soda 4.0 marks the beginning of self-driving data quality. Data quality moves from manual rules and reactive fixes to systems that define expectations, enforce them automatically, and continuously improve. This is the direction Soda is building towards.
Ready to see it in action?
Request a demo or start a free account today and check out all the new updates on Soda Cloud 4.0.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Start trusting your data. Today.
Find, understand, and fix any data quality issue in seconds.
From table to record-level.
Trusted by







Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Start trusting your data. Today.
Find, understand, and fix any data quality issue in seconds.
From table to record-level.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Start trusting your data. Today.
Find, understand, and fix any data quality issue in seconds.
From table to record-level.
Trusted by
Solutions
Company