
What is a Data Contract?
A data contract is a formal agreement between data producers and consumers that defines what data will look like, how it should behave, and what guarantees each side can rely on.
It specifies structure, expected values, update frequency, and quality thresholds so teams know what to expect before data flows downstream. They define:
Schema and types – what columns or fields exist and their allowed formats.
Business meaning – what each attribute represents, including accepted ranges or categories.
Quality criteria – freshness, completeness, uniqueness, and other measurable standards.
Change management – who approves or communicates schema changes and how.
When these details are codified and version-controlled, data pipelines become more reliable, transparent, and testable—just like well-designed software systems.
Glossary
I'll be using the term 'dataset' for tabular data like a table.
A 'data component' refers to a software component in the data pipelines that has one or more datasets as output. Examples of data components are an extraction or a transformation.
'Data applications' are applications like reports or machine learning models that consume analytical data. While this deviates a bit from data mesh terminology, I think it helps to better align the vocabulary with general software engineering concepts.
Why Start with Data Contracts?
Data contracts are starting to make a splash on the data landscape, and for good reason! They’re long overdue. All too often data teams struggle to scale their work as data products break and data issues regularly occur.
Contracts are the API for data. It's the packaging that we've been missing in data engineering to achieve encapsulation in data pipelines. Lack of such an interface has put a cap on the scaling and productivity of data teams.
It's more than a technology. It's an architectural mindset to think in terms of interfaces. That thinking is mostly missing in data engineering and the trend towards data contracts is going to bring more scalable practices into data teams.
Let's look at the 5 most important benefits that can be achieved by adopting data contracts.
1. Clarify Ownership of Data
Analytical data is often a monolithic web of spaghetti pipelines, a situation that doesn't scale well. The symptoms of pipeline spaghetti include data quality issues and a lack of trust in data. When a potential data issue occurs and there are no clear owners defined, the first challenge is to dig through the spaghetti and find who is able to diagnose and address the problem.
Many organizations struggle to establish ownership for their analytical datasets. This is understandable because often, the team responsible for the data is small and both the team and its rules for governing data grew organically, and potentially a little haphazardly. But as teams start to build more data components and team members shift around, it can become hard to find the right people to deal with issues or new requirements when they arise.
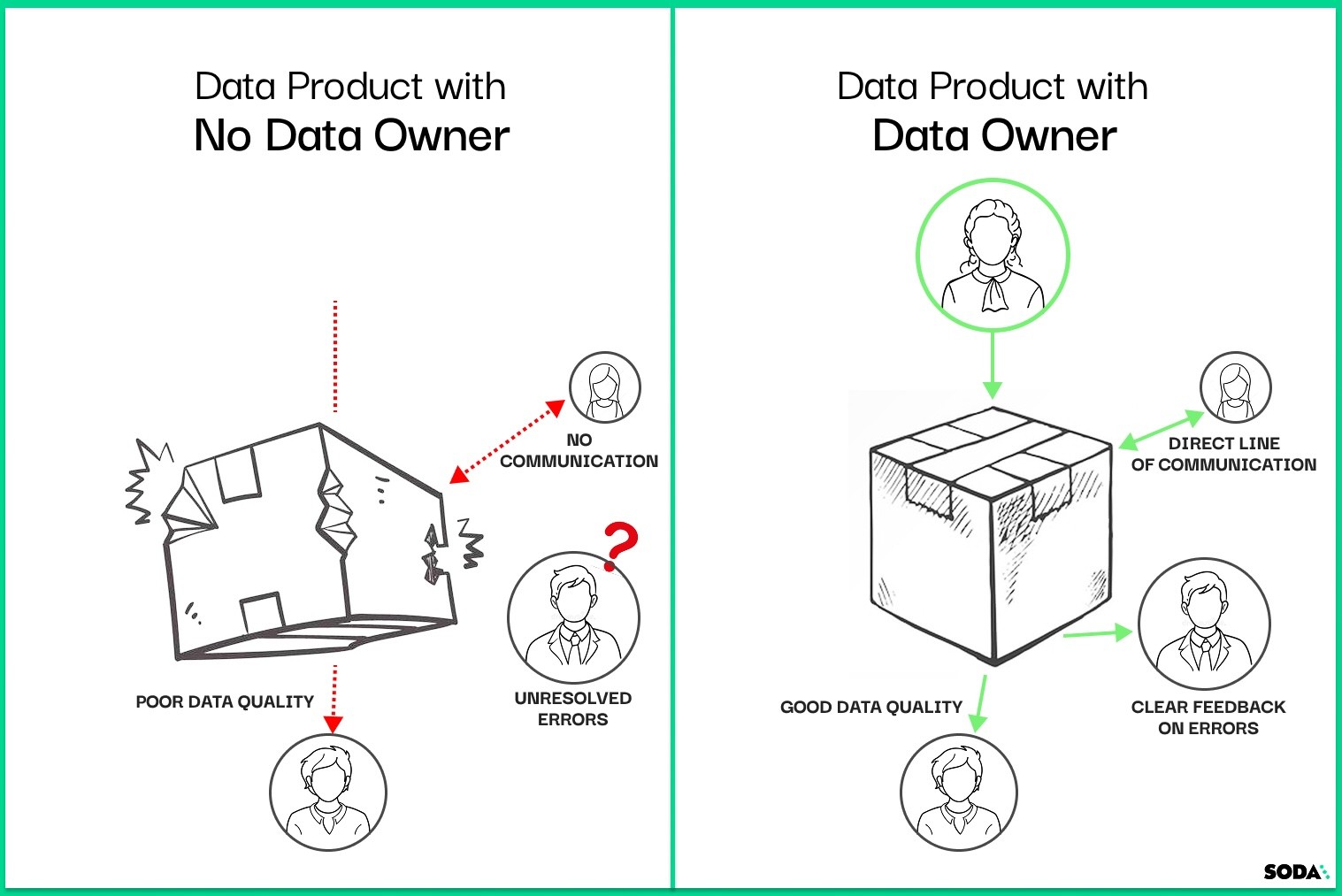
Datasets without an owner are unstable and destined to break downstream consumer assets. As a consumer, you ideally want to use only those datasets that have an owner, an actual human you can contact in case of issues or questions.
Data contracts create a separation between the implementation of continuously updating a dataset (read: the pipelines) and the resulting data that is made available as a dataset to all consumers. It's the team that is responsible for building and operating the pipelines that must take ownership of the resulting dataset. Because data contracts help to separate implementation from interface, they help to clarify what ownership of a dataset means.
The act of creating the contract is the starting point of taking ownership. It's a declaration saying this is the data we promise to deliver and will keep up to date, whatever happens upstream or however we want to build our implementation. Taking full ownership of a dataset includes:
Creating and publishing a data contract will enable consumers to start consuming your data as much as possible in a self-serve manner, without the need to ask questions
Be transparent on stability guarantees
Establish a channel for consumers to ask questions, change requests or new feature requests
Build, deploy, and monitor the production implementation
Set up testing for new releases of the implementation
Monitor data quality
In short, introducing data contracts will start with the question: Who should create and maintain the contract?
In that sense, data contracts help drive the notion of ownership and the architectural pattern of encapsulation.
2. Break Down Monolithic Data Pipelines
In the context of monolithic, spaghetti data pipelines, it's hard to take ownership of a dataset. That's because the input data for a particular transformation can be undocumented and there are no guarantees of stability. In that case, it's hard to promise anything on the data that you produce.
But if the inputs of your transformation all get a data contract, this changes. Adding clarity and guarantees on all the inputs in the form of a data contract makes it much easier to oversee the responsibility of taking ownership. An engineer building a single transformation is now able to provide the same clarity and guarantees on the output data. This divide-and-conquer strategy helps to break down the monolithic spaghetti pipelines.
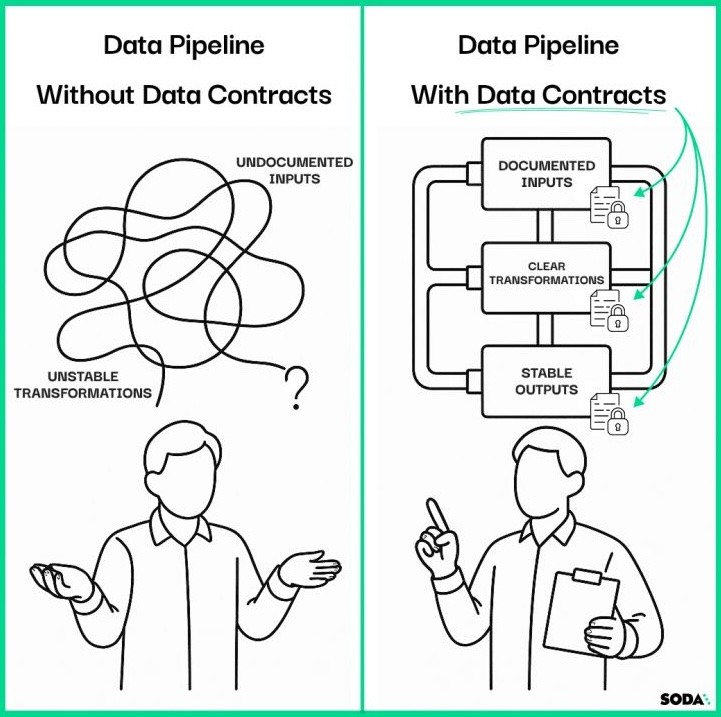
Data contracts provide clarity and guarantees for all inputs and outputs. They allow engineers to take ownership and improve predictability, scalability, and diagnostics.
Each step in the extraction and transformation of analytical data can, in fact, be considered an individual system or component. Having clear interfaces between all these components is simply good engineering practice, and it’s a great way to build a robust data architecture.
The data team will be more predictable in their output and more scalable in the amount of work they can handle, just like software engineering teams when they transitioned from spaghetti code to object-oriented programming.
The value of breaking down the monolith pipelines in manageable data components increases when considering the diagnosis of potential data issues. Without contracts, engineers have to traverse the pipeline upstream without a clear map of what the data should look like. They can also be wasting time on a number of internal datasets that are merely a distraction.
Data contracts separate internal datasets from the handovers between different data components. And for those datasets, the contract is a clear description of what the data should look like. In that sense, contracts help to speed up the diagnostic workflows for engineers significantly.
However coarse or fine-grained your data components are is not really a big factor. If you start from a single, huge monolithic spaghetti pipeline, it will already help to create contracts for the datasets made available to consumers, sometimes referred to as 'refined' or 'gold'. That way, consumers building data applications can see if their expectations match the promises made.
Next, as early as practically possible, at the source is also a good place to start introducing contracts. Afterwards, you can go finer and identify intermediate datasets for which to define contracts.
The right size for a data component is hard to tell, just like it's very hard to put the right size on a software component or service with a REST API.
Contracts allow for a gradual introduction of contracts as interfaces. In that sense, contracts are a lot easier to retrofit compared to API's on software components. That makes it possible to gradually move from bigger data components to smaller ones.
3. Monitor Data Quality
When analysts build new analytical data applications, it's not often easy for them to find a clear description of what the data looks like. This leads to the well-known approach: 'Let's try and if it works we assume it's all good'.
Contracts include a language to express any expectation that a consumer may have on data. That's data quality.
The basic data quality expectations are schema, missing data, and validity constraints. More advanced data quality assumptions are distribution, average, and other aggregations, referential integrity, etc.
Contracts provide a way to describe what the data looks like in more detail than the typical analytical warehouse storage system. Each time new data is produced, the new data can be validated against all the data quality assertions in the contract. This is also referred to as 'enforcement', but I consider verification to be a more suitable term.
Ideally, verification is done with circuit breakers so that no bad data will ever reach data applications. The result is that contracts offer a richer language to express assumptions on data quality that can be verified in production.
There are many people outside the team producing the data who have domain knowledge of what good data looks like. As part of an overall data quality strategy, they should be allowed to contribute to the picture of what good data looks like.
Dataset owners or data producer teams have to set up communication channels so that anyone in the organization can suggest new data quality checks or changes. The data producer teams have to translate them into the contract and ensure it's part of the monitoring process.
Contracts help with monitoring data quality because:
There is a rich language to describe data quality assertions
Data producer teams (read: owners) are responsible for contract verification, including the data quality assertions
Consumers can help by proposing data quality expectations as extra data quality checks to be added to the contract

4. Increase Data Transparency
These days, data discovery tools are typically connected to the metadata of a warehouse. This poses a couple of challenges:
All datasets are discovered, even the internal datasets that are not intended for use by other teams.
The warehouse metadata is not very detailed or uis navailable. For example, simple checks like "The average amount should be between 20 and 50" are not shared or verified.
We saw that a data contract includes a more detailed description of what the data looks like and that these details are also verified as new data gets produced.
As such, data contracts are the perfect source to feed data discovery tools like catalogs. Those tools are the place where people want to find and understand data. Contracts contain richer metadata of what the data looks like compared to the basic metadata found in analytical warehouses.
On top of that, the presence of a contract also separates the datasets intended for consumption from the internal, intermediate datasets. That is something that is not captured when data discovery tools just scrape the warehouse metadata. We foresee that data discovery tools will migrate away from ingesting the warehouse metadata directly towards ingesting the contracts.
Plus, data contracts are files that you can manage in git; you can install webhooks so that each change in a production branch of a contract gets pushed to a data discovery tool. That way, data discovery tools contain a more complete, up-to-date, and trustworthy picture of what the data looks like.
5. Build Immutable Data Infrastructure
Making available rich metadata to consumers and monitoring the data quality are 2 key ingredients of a data platform. Because data contracts are text files, they can be managed as code and versioned in git.
When using data contracts, the rich metadata in contracts and the data quality monitoring become part of the immutable data infrastructure. This makes it easy to duplicate environments for CI/CD and disaster recovery, ensuring that data contracts and data quality are seamlessly integrated as a part of engineering workflows.
Next to data quality monitoring and storing the metadata for discovery tools, more tools can use the contract as the authoring place for their configurations. Consider PII, access management or retention. Because the structure of data contracts is based on the schema, it's a natural extension to include those aspects as well.
Conclusion
Data contracts are an important tool to help organizations deal with ownership and break down monolithic spaghetti pipelines. They form the basis for improving and monitoring data quality. When connected to discovery tools, data contracts provide transparency on which data is intended for sharing, and they include a detailed picture of what good-quality data looks like. Data contracts fit within the engineering workflows because they help establish an immutable data infrastructure and they create better alignment between the analytical data teams and the rest of the business.
Learn more about how to set up data contracts with Soda in our documentation.
Take action!
Schedule a talk with our team of experts or request a free account to discover how Soda integrates with your existing stack to address current challenges.











