
What Is Data Lineage?
Everyone throws around the term data lineage, but few agree on what it precisely entails.
At a basic level, it's the end to end record of how data originates, moves, transforms, and gains meaning as it flows. But that definition quickly runs into ambiguity. Are we talking about SQL transformations? Dashboard metrics? Machine learning features? Semantics of the data? All of the above?
The term collapses multiple layers of abstraction into one word, and unless we’re clear about what kind of lineage we mean, most discussions stay vague.
At the centre of all this sits metadata, which is data about the data. Lineage doesn’t exist without it. But just having metadata isn’t enough to have a good data lineage; it needs to be structured, and managed across tools that aren't necessarily designed to do that.
Lineage at the table level might satisfy governance teams. But engineering teams debugging a broken dashboard need to trace lineage at the column level or even deeper, to specific lines in DAGs or codebases. Granularity is determined by your use-case and is another dimension to take into account when a discussion around data lineage comes up.
Outside of governance talks, automation tools are prevalent. Although no tool provides full coverage when it comes to a modern data stack. As a result, teams are often obliged to stitch together metadata. Defeating the very point it was being pushed in the first place.
Making a strong case for why it matters, outside of compliance-driven contexts, is a bigger problem.
This blog unpacks the concept of data lineage, why it matters, and how we at Soda like to categorize it.
Key Takeaways |
|---|
|
Why Bother with Data Lineage?
Data Lineage provides answers to key breakpoints in the data lifecycle:
If you rename a column, which downstream data products will break?
If a number in a report looks wrong, where did the error originate?
Who uses this dataset, and for what purpose?
Can you prove where sensitive or regulated data has flowed?
When data is incorrect, teams would have to waste hours tracing issues across pipelines and reporting tools. Lineage lets you zero in and contain the problem before it spreads.
For regulated domains (finance, healthcare, etc.), opting out of data lineage risks non-compliance. Lineage gives you the much-needed traceability. You can show exactly how data moved, transformed, and got used.
The greatest value is that it creates a shared understanding across teams. Engineering, analytics, governance, and leadership can all speak the same language. Lineage replaces guesswork with evidence.
Types of Data Lineage
Most lineage implementations stop at technical traceability and leave out the people who use the data i.e. analysts, domain owners, business stakeholders. The result is technically correct but contextually incomplete since the pipelines are mapped, but the meaning and consequences of change are not.
At Soda, our approach starts with change management. We believe every data transformation should prompt the question: Who needs to know, and what will be affected?
This reframing leads us to a more functional and stakeholder-aware categorisation of lineage: horizontal and vertical.
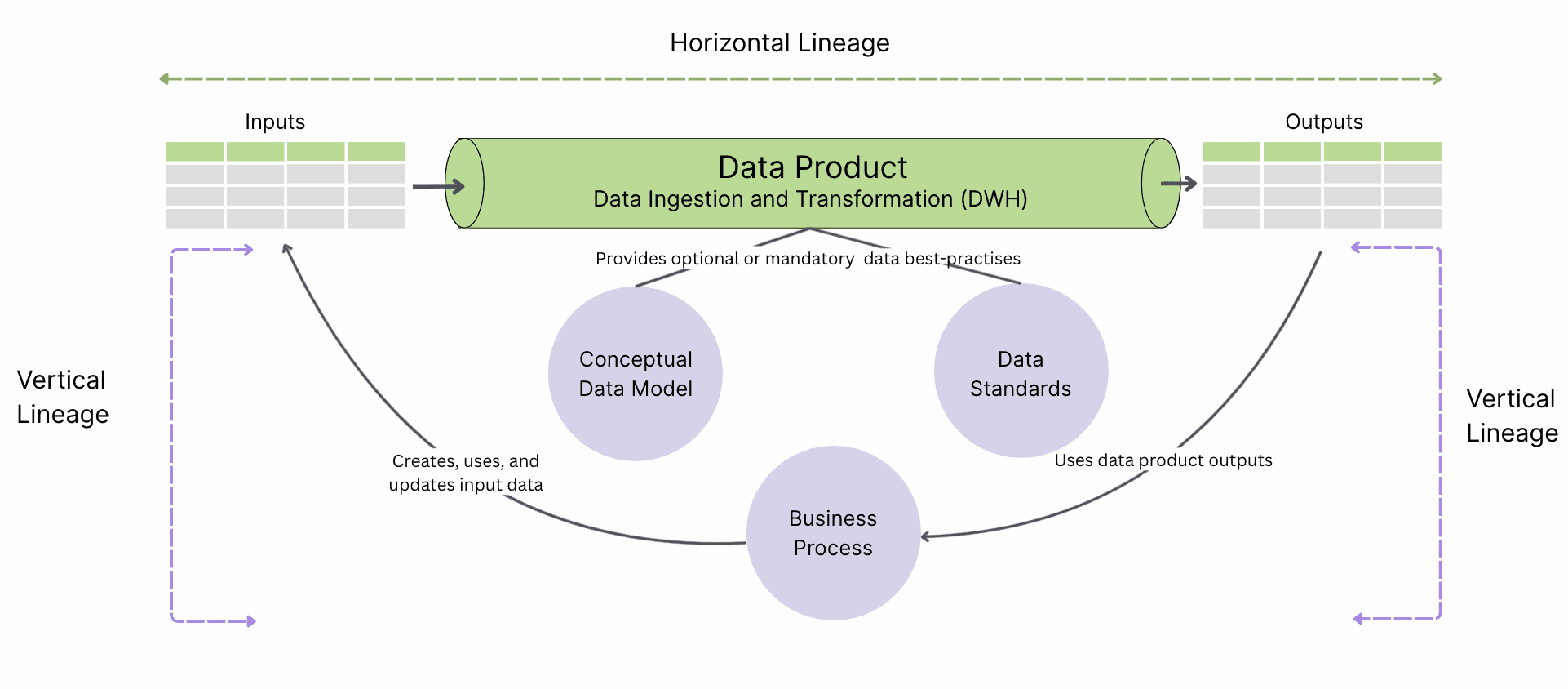
Horizontal Lineage for Technical Persons
Horizontal lineage follows the technical journey of data. How tables, columns, and code (SQL, ETL, dbt, etc.) produce and transform data as it flows through systems. It answers the "how" and "where" questions from a developer’s lens.
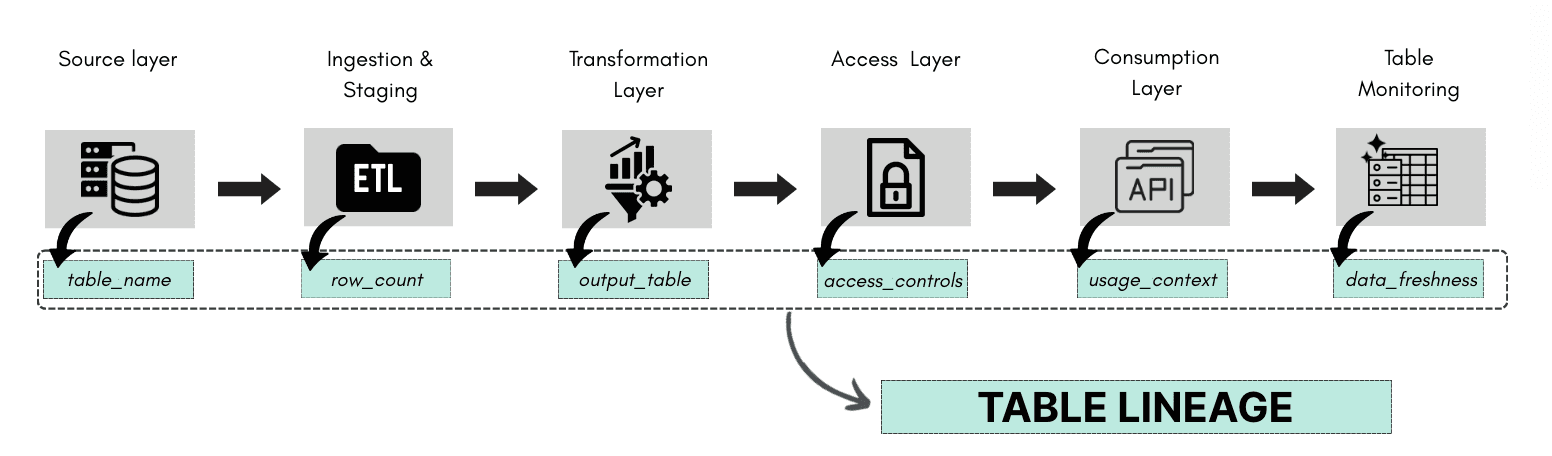
Table Lineage
Table lineage refers to the ability to trace how a particular database table was created, modified, or used by showing its upstream inputs (which tables or sources it was built from) and its downstream outputs (which other tables, reports, or systems use it).
It helps understand:
The source of the table’s data
The transformations or joins that were applied
The downstream processes that rely on this table
It’s a way to understand the role a table plays inside a larger data pipeline both what it consumes and what it powers.
In daily workflows, data engineers rely on table lineage to debug broken pipelines, assess the impact of schema changes, and ensure safe deployments. Analysts and analytics engineers use it to validate assumptions and understand how trusted a dataset is before using it.
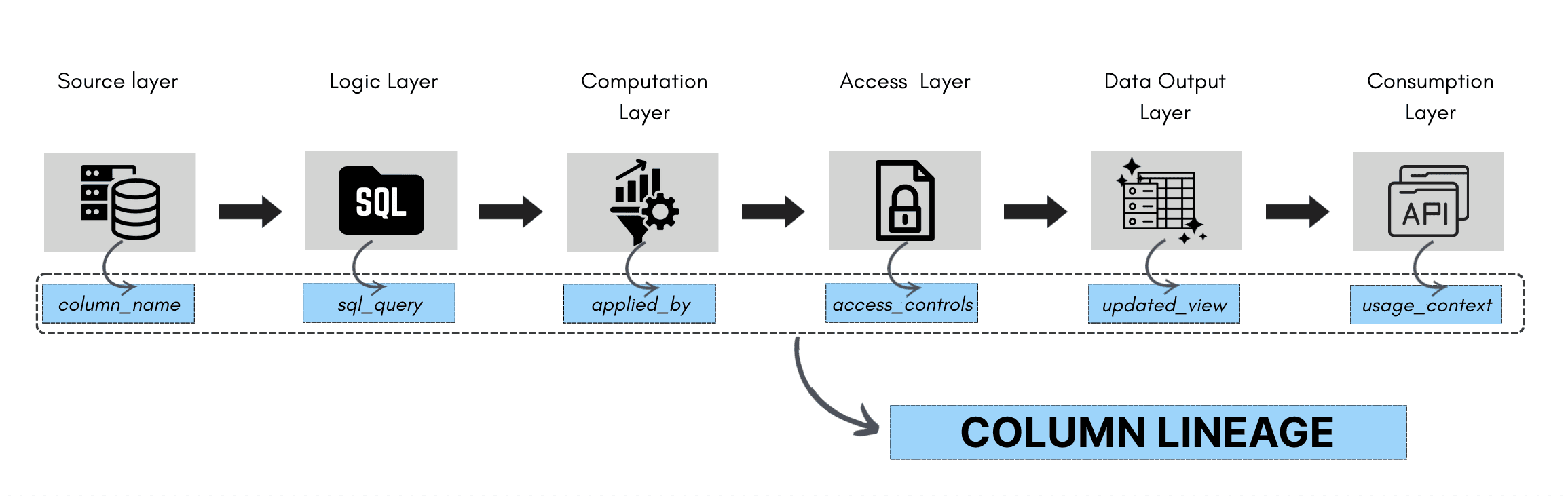
Column Lineage
Column lineage is a subcategory of and builds on table lineage by giving you a more detailed, column-level view of data movement and transformation. While table lineage shows how tables connect, column lineage tracks how individual fields are sourced, calculated, and passed downstream.
It shows you:
The input columns that contribute to a specific field
The transformations or expressions that shape it (e.g., aggregations, casts, conditional logic)
The downstream usage of the column, whether in other tables, dashboards, or machine learning features
Data engineers use column lineage to debug incorrect values, track the impact of schema changes, and understand the exact logic behind derived fields. Compliance teams depend on it to prove where sensitive fields (like PII or financial data) flow and how they’re transformed.
Column lineage matters most when precision is non-negotiable like in audit scenarios, financial reporting, or production-grade ML pipelines.
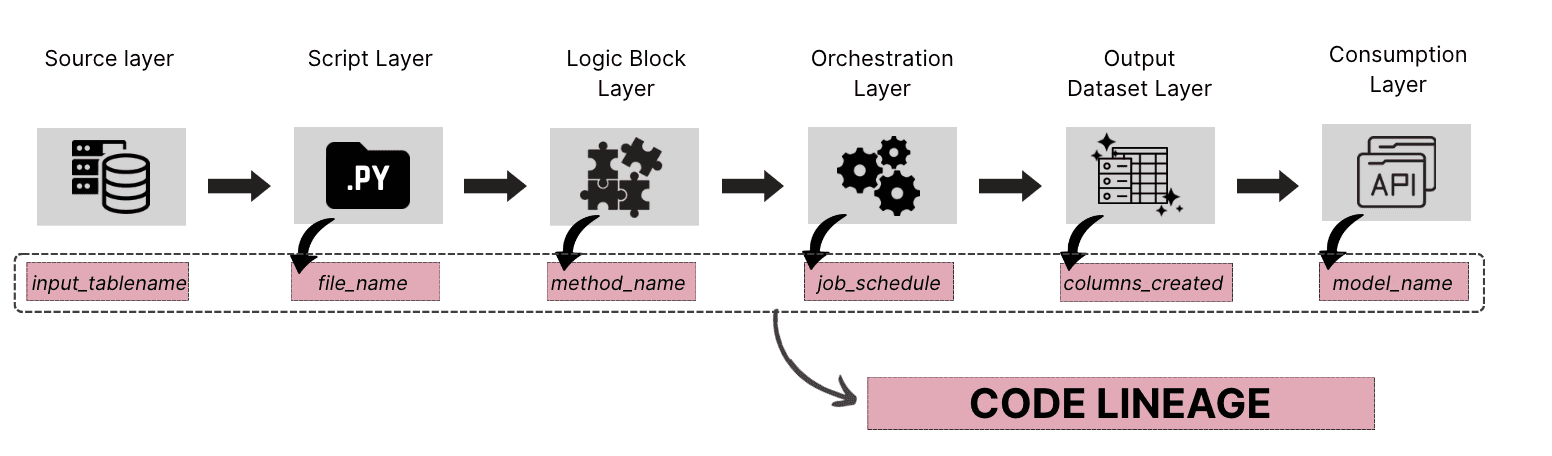
Code Lineage
Code lineage tracks how specific pieces of code produce, transform, or displace data and ties those actions to version history. It connects scripts, SQL queries, functions, or models to the datasets they modify and shows how these code components interact across the pipeline.
It helps discover:
The parts of the codebase that touch specific datasets
Where transformations are defined whether its in SQL files, Python scripts or dbt models
The downstream impact of a code change, such as a pull request or a version update
Code lineage links data behavior to implementation logic. It allows data engineers and analytics engineers to trace the origin of a transformation, assess the impact of a proposed code change, and debug issues introduced in recent deployments.
In version-controlled environments, it also helps reviewers understand the data implications of a pull or merge request before approving it.
Vertical Lineage for Business Persons
Vertical lineage traces the semantic and organizational context of data: how a particular metric aligns with business definitions, policies, regulations, or ownership. It answers the "what does it mean" and "who cares" questions typically for analysts, stewards, and compliance teams.
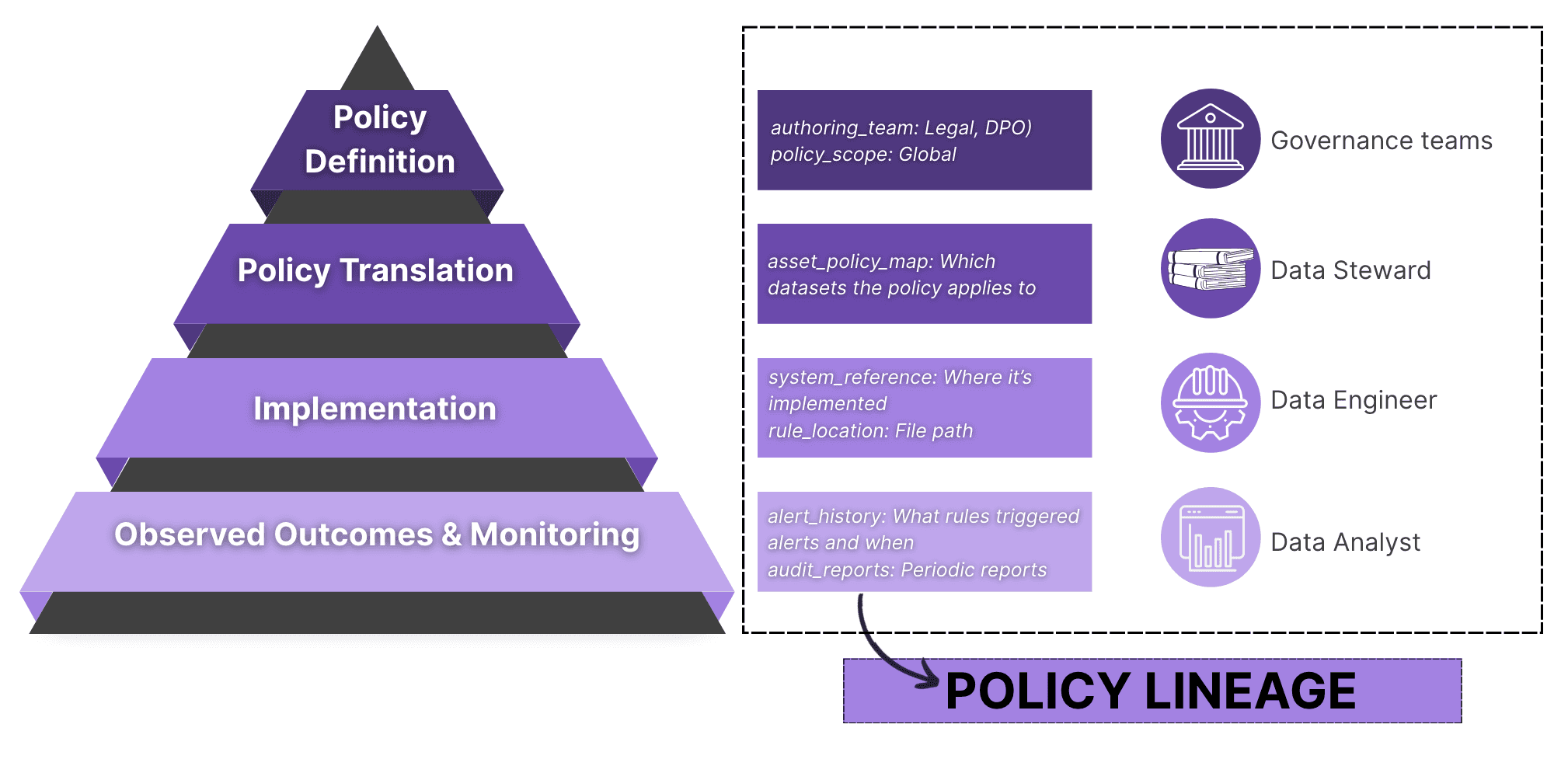
Policy Lineage
Policy lineage tracks how data policies are created, applied, and enforced across systems. It shows the connection between governance rules and the specific data assets or processes they affect.
It helps you answer:
Which policies apply to which datasets or fields?
Where in the pipeline are those policies enforced?
How changes to policies impact data access, quality, or compliance?
Policy lineage links governance decisions to operational reality. It helps ensure that policies are not just documented, but actively shape how data is handled.
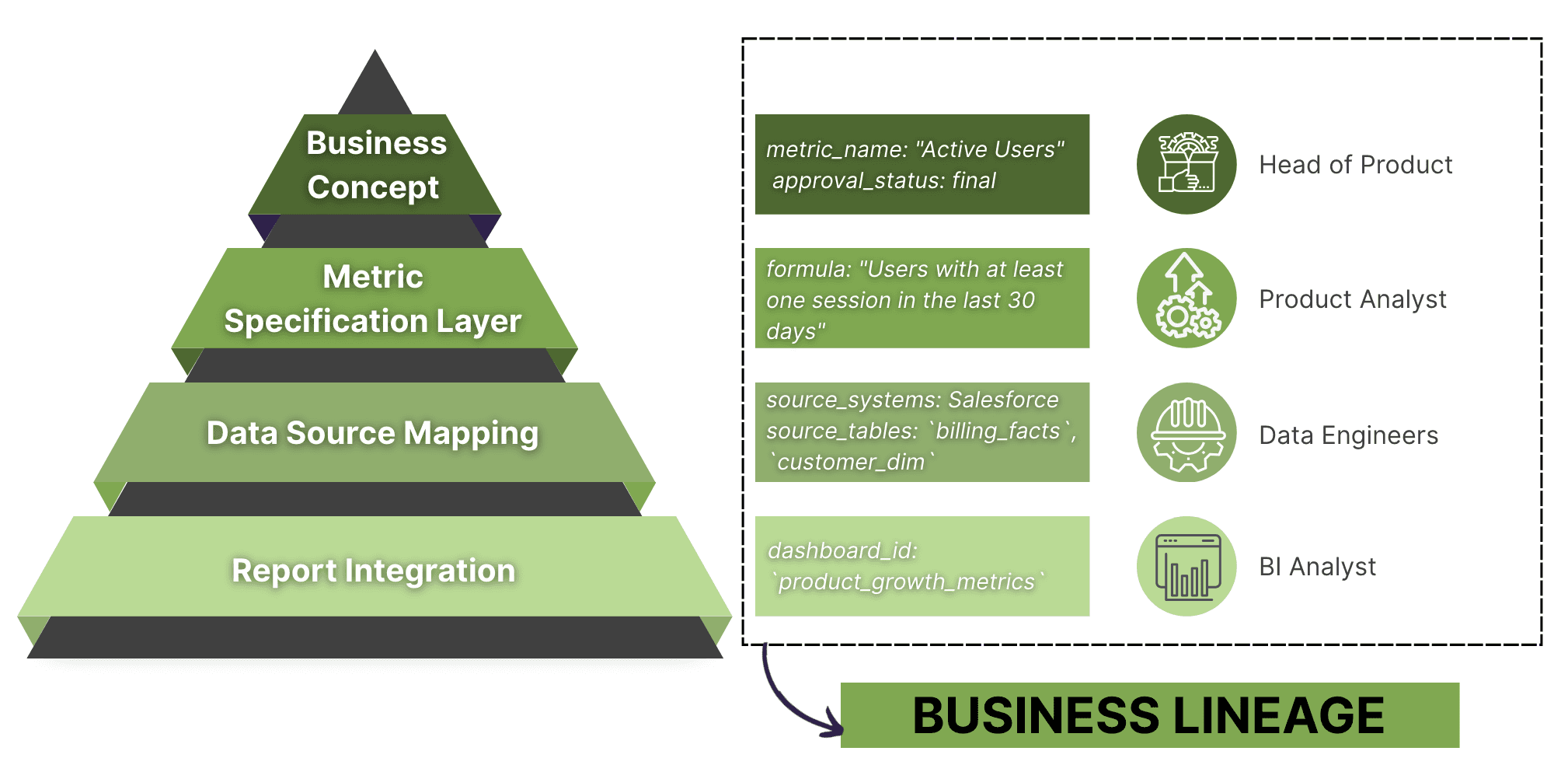
Business/KPI Lineage
Business lineage shows how data supports business concepts, metrics, and decisions. It connects data assets to the business definitions, reports, or KPIs they inform.
It helps you answer:
Which datasets feed into specific business metrics or dashboards?
How data aligns with business terms and definitions?
How changes in data sources or logic impact reporting and decision-making?
Business lineage bridges the gap between raw data and its meaning in a business context. It helps non-technical users understand where numbers come from and whether they can be trusted.
Best Practices
Data engineers can automate lineage capture from ETL pipelines, transformation code and BI tools to avoid manual shifting.
Product managers should review data lineage as part of every code change to catch downstream impact before deployment.
Data stewards should map lineage to business terms and metrics so analysts and stakeholders can understand the meaning behind the data.
Governance teams should regularly monitor which datasets have lineage coverage and check that the information is current and complete.
Customer Engineers should use lineage during debugging and planning to identify what breaks, who is affected, and how changes flow through the system.
Frequently Asked Questions
What is the difference between data lineage and data flow?
Data flow captures the movement of data between systems or processes. Data lineage goes further; it traces the origin, transformations, dependencies, and usage of data across its lifecycle. Lineage includes metadata, context, and impact. To understand where the data moved, look into the flow. To understand why and how data changes, look into data lineage.
Why do you need data lineage?
Lineage provides answers to key breakpoints in the data lifecycle. Its greatest value is that it creates a shared understanding across teams. Engineering, analytics, governance, and leadership can all speak the same language. Lineage replaces guesswork with evidence.
What happens if you don't establish the lineage of data you are using?
When data is incorrect, teams would have to waste hours tracing issues across pipelines and reporting tools. For regulated domains (finance, healthcare, etc.), opting out of data lineage risks non-compliance. Lineage gives you the much-needed traceability. You can show exactly how data moved, transformed, and got used.
What is the difference between data lineage and data audit?
Data lineage maps the flow and transformation of data over time; it answers how and where data moved or changed. Data auditing focuses on verifying whether data complies with rules or policies. Lineage provides the context; auditing checks whether behavior aligns with expectations or regulations.











