Avoid Data Migration Risks with Reconciliation Checks
Avoid Data Migration Risks with Reconciliation Checks
Avoid Data Migration Risks with Reconciliation Checks

Maarten Masschelein
Maarten Masschelein
CEO and Founder at Soda
CEO and Founder at Soda
Table of Contents
Data migration is the process of moving data from one system or storage environment to another. Data teams often tackle data migration projects when they need to permanently transfer data from one storage system to another. The benefits of these projects are typically reduced costs that come with consolidating systems and increased productivity, such as faster queries on unified data.
However, data migration projects come with risks. According to a 2007 report by Bloor Research, 84% of data migration projects overran time and budget; and on another report from 2011, the group’s survey found that poor data quality or lack of visibility into data quality issues was the main contributor to migration project overruns.
Without proper governance and quality checks, it often leads to data loss, corruption, and downtime. More often than not, the root cause of these failures is a lack of investment in systems and processes that ensure reliable, high-quality data.
When newly-migrated data appears to be inaccurate in a new storage system, end users are likely to distrust the data and go back to the old way of working. In an effort to mitigate that outcome, this article discusses several data migration best practices that use Soda to help address data migration risks.
Decide on your Approach
The first thing to think about is your approach.
Are you going with an incremental approach or a big bang?
Do you plan on running both systems in parallel for a while, and if so, for how long?
To decide on an approach, it’s best to create a stakeholder map that helps you understand who is using the system, for what purpose, and when each team can invest the time to migrate.
Plan your Data Migration
What follows are some of the steps to consider adding to your next data migration project planning.
Catalog data to be migrated
Document schemas and data types: Understand the variety of data in the system
Document volumes: Understand the volume of data processed daily
Define scope, priority, and stakeholders
Stack-rank datasets: What’s most important to do first?
Identify technical stakeholders: Which data and infrastructure engineers need to be involved?
Identify domain experts (SMEs): Which business SMEs can you leverage?
Identify key data consumers: Which consumers will do acceptance testing?
Document legacy data quality issues
Understand the problems of the past
Evaluate and pick tools
CI/CD: Which tool will you use to store and release code?
Ingestion: Which tool will move data from source to target?
Warehousing: Which SQL engine will you use?
Transformation: Which tool will build derived models and views?
Cataloging: Which tool will document data and stakeholders?
Quality: Which tool will evaluate data quality and debug issues?
Design first iteration
Select datasets: Take into account other projects
Profile and add baseline checks: Iterate on quality checks with the stakeholders
Map source to target types: Convert to more specific types, where possible
Migrate data transformation logic: Rewrite the transformation logic in the new tool
Write schema and reconciliation checks: Write checks that compare source to target
Share data quality results: Share the results of data quality checks with stakeholders
Test user acceptance
Ask SMEs and consumers to test
Decommission
Proceed team by team, or use-case by use-case
Report on TCO
Analyze and share the results of the project
Manage Data Quality Across Migration
If data quality is the most common root cause of data migration failure, then let’s unpack what can go wrong and why.
This blog was created with previous versions of Soda Core and Soda Cloud, so there might be minor code syntax and UI path differences. If you have any questions refer to https://docs.soda.io/ |
|---|
Data quality issue | Potential root causes | SodaCL Checks |
|---|---|---|
Incomplete, missing records | Some data was left out during ingestion and transformation | Row count anomaly Count per categorical Missing values Valid values Metric reconciliation Record reconciliation |
Incomplete, missing columns | A number of columns were excluded or were completely empty and automatically dropped | Schema |
Duplicate rows | Data was mistakenly duplicated because no key was added to the join | Duplicate |
Data teams can measure the success of a data migration project by aggregating the check results. SodaCL reconciliation checks provide the most important measure of accuracy as they compare the source and target tables to identify differences at a metric and record level.
These checks make sure that the state of data in one system exactly matches the state in the other system. Sharing the results of these metrics with everyone increases transparency and trust in the migrated data.
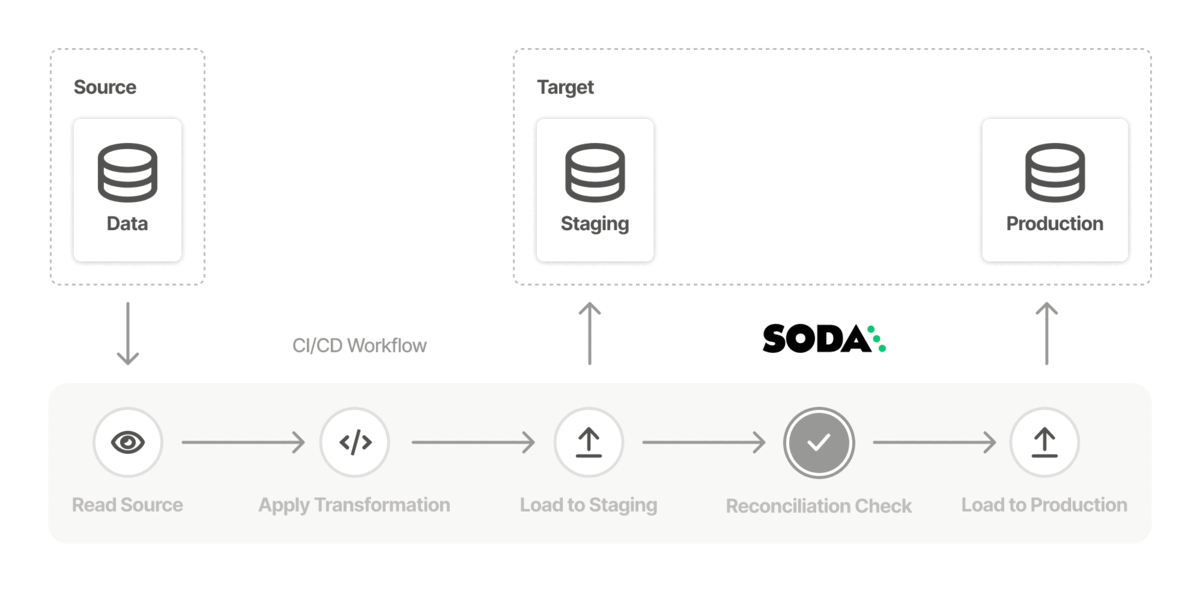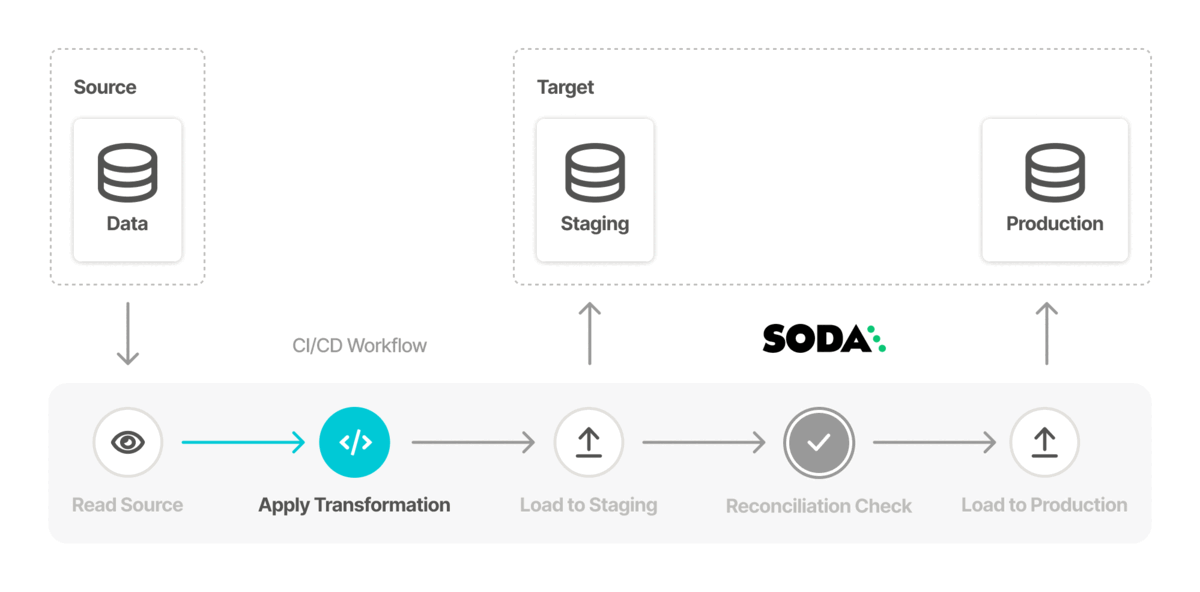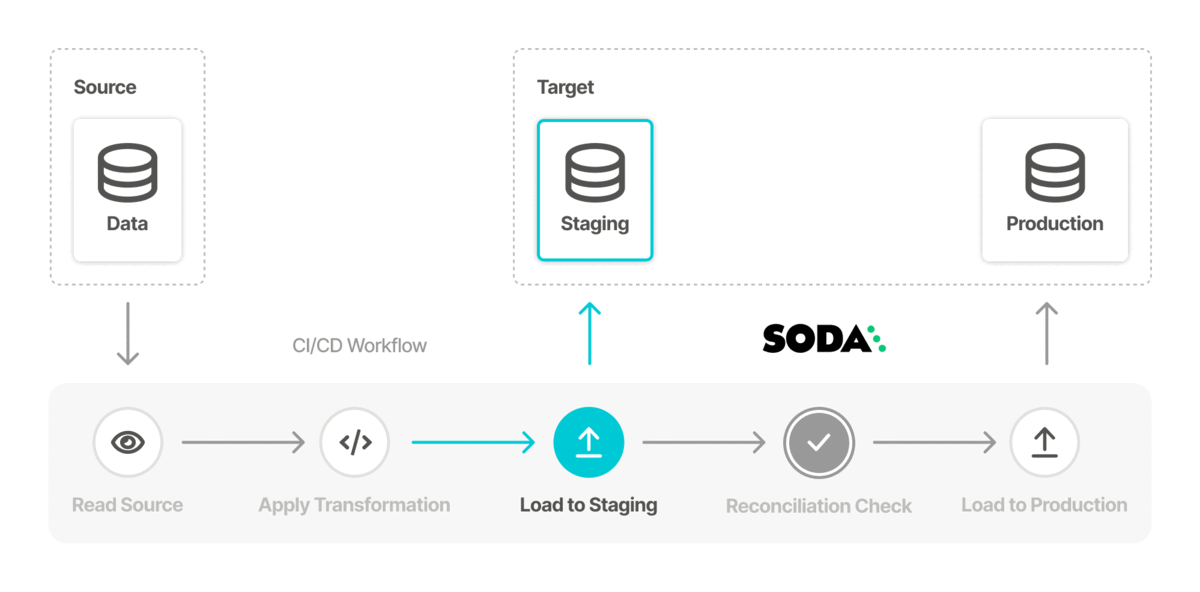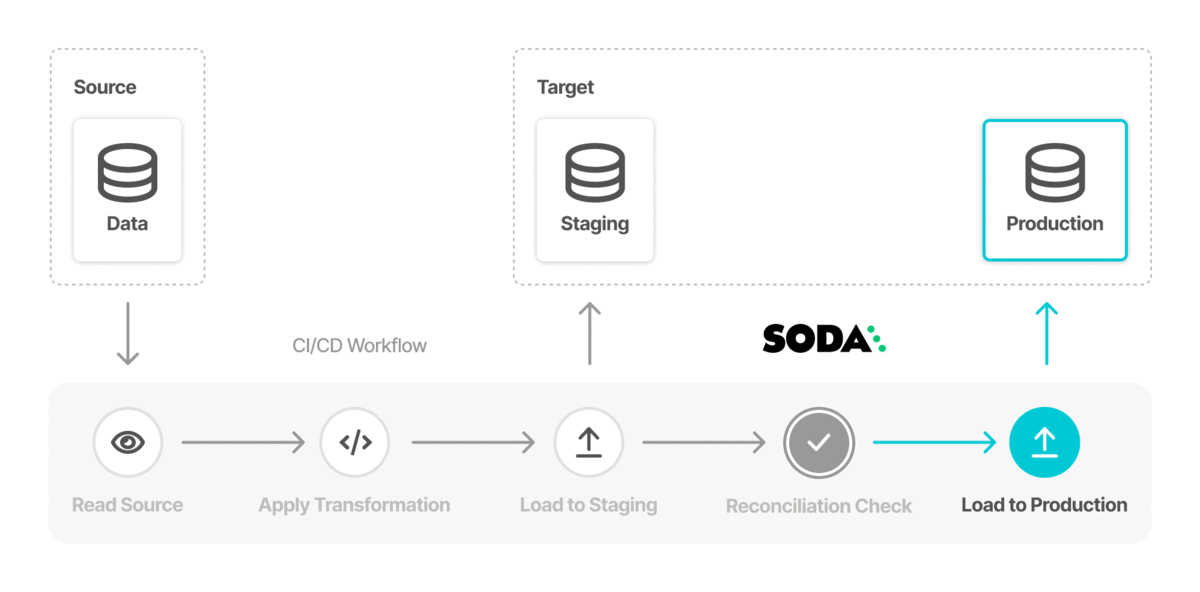
For example, use a metric reconciliation check to evaluate the percentage of missing values in a column, and a record reconciliation check to validate that the employee name is the same in both the source and target tables.
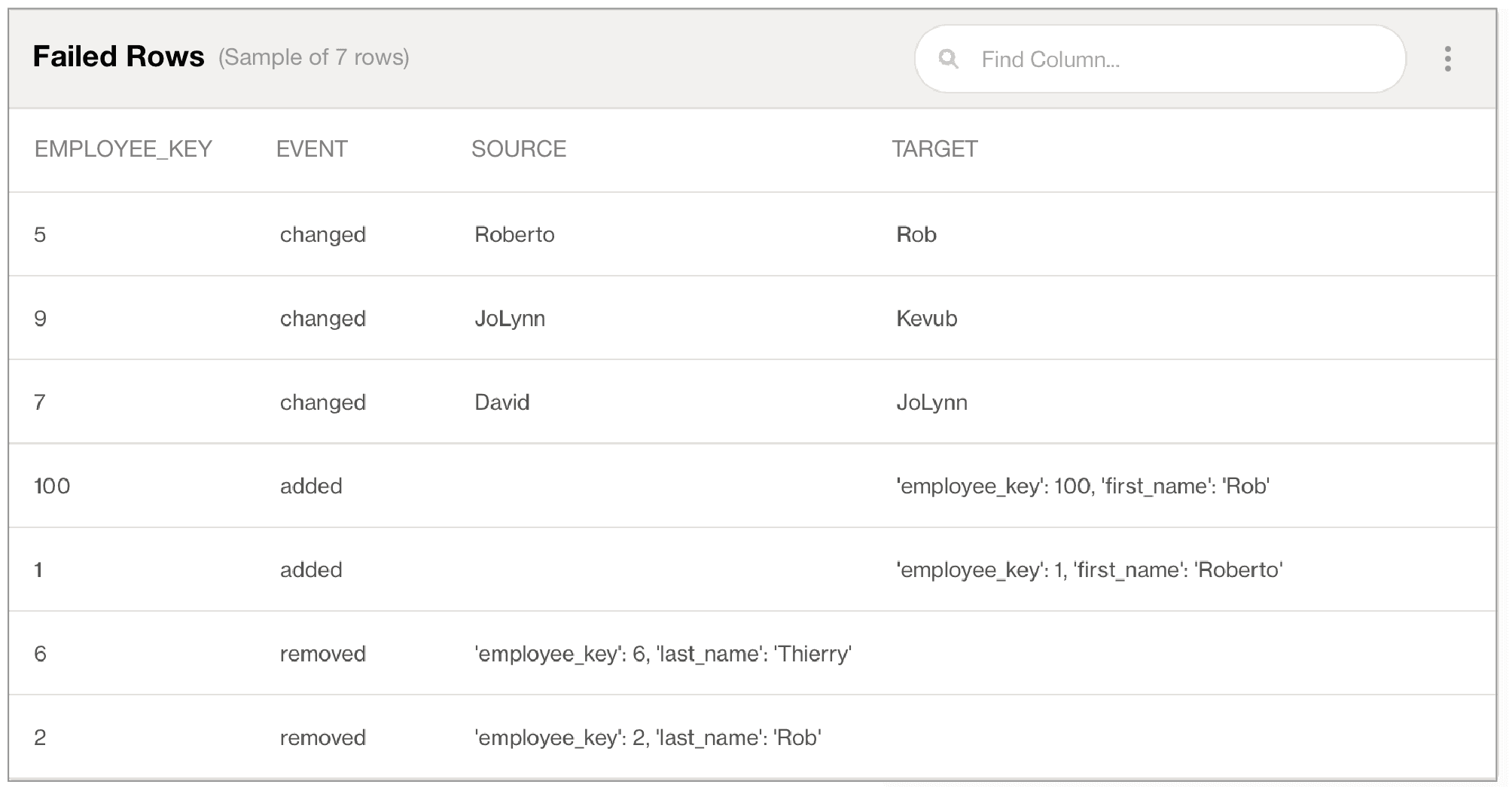
You can implement Soda reconciliation checks as in the following SodaCL example which compares only the data specified in the list of columns, mapped according to order in which they are listed. See below:

In the example above, with more than six inconsistencies between data in the columns, the data quality check fails. The check result output in Soda Cloud identifies data quality reconciliation issues that you can address problems early, ideally in a staging environment, so as to prevent migrating data quality issues into production as you migrate the data itself.
Transition to the New Source
Many teams are reluctant to change for a variety of reasons. Therefore, it’s very important to work closely with your stakeholders, like subject matter experts and consumers. Make sure they plan time to test and migrate their processes to the new data source. Check in with them as they progress, and when they are finished, decommission the datasets in the old data source.
Best practice dictates that you run both systems in parallel for a short while and work iteratively towards complete transition. “Big bang” transitions seldom work out well.
To further motivate data teams to make the transition, you can also introduce new data management capabilities that further drive the adoption of the new data source. You can, for example, embark on a project to improve data cataloging, quality, security, retention, or access management. The easier the tools and processes, the more likely users will migrate.
Measure Twice, Cut Once
This old adage holds up well in the digital world of data migration: measure data quality in Staging using SodaCL reconciliation checks before cutting over to Production. We could even add “An ounce of prevention is worth a pound of cure” or “Garbage in, garbage out”. These proverbs prove that we’re all addressing the same kinds of challenges, and those of us who make the effort to prevent data quality issues early in a data migration project will fare much better.
Sign up for a Soda Cloud account, or install the latest version of Soda Library today to set your team up for success with reconciliation checks.
See Soda documentation for more details.
Learn more
Watch this 45-minute session to see:
Data migration use cases and best practices
A product showcase to test, manage, and assure data quality
Guidance on how to automate the reconciliation process to save time and resources
Data migration is the process of moving data from one system or storage environment to another. Data teams often tackle data migration projects when they need to permanently transfer data from one storage system to another. The benefits of these projects are typically reduced costs that come with consolidating systems and increased productivity, such as faster queries on unified data.
However, data migration projects come with risks. According to a 2007 report by Bloor Research, 84% of data migration projects overran time and budget; and on another report from 2011, the group’s survey found that poor data quality or lack of visibility into data quality issues was the main contributor to migration project overruns.
Without proper governance and quality checks, it often leads to data loss, corruption, and downtime. More often than not, the root cause of these failures is a lack of investment in systems and processes that ensure reliable, high-quality data.
When newly-migrated data appears to be inaccurate in a new storage system, end users are likely to distrust the data and go back to the old way of working. In an effort to mitigate that outcome, this article discusses several data migration best practices that use Soda to help address data migration risks.
Decide on your Approach
The first thing to think about is your approach.
Are you going with an incremental approach or a big bang?
Do you plan on running both systems in parallel for a while, and if so, for how long?
To decide on an approach, it’s best to create a stakeholder map that helps you understand who is using the system, for what purpose, and when each team can invest the time to migrate.
Plan your Data Migration
What follows are some of the steps to consider adding to your next data migration project planning.
Catalog data to be migrated
Document schemas and data types: Understand the variety of data in the system
Document volumes: Understand the volume of data processed daily
Define scope, priority, and stakeholders
Stack-rank datasets: What’s most important to do first?
Identify technical stakeholders: Which data and infrastructure engineers need to be involved?
Identify domain experts (SMEs): Which business SMEs can you leverage?
Identify key data consumers: Which consumers will do acceptance testing?
Document legacy data quality issues
Understand the problems of the past
Evaluate and pick tools
CI/CD: Which tool will you use to store and release code?
Ingestion: Which tool will move data from source to target?
Warehousing: Which SQL engine will you use?
Transformation: Which tool will build derived models and views?
Cataloging: Which tool will document data and stakeholders?
Quality: Which tool will evaluate data quality and debug issues?
Design first iteration
Select datasets: Take into account other projects
Profile and add baseline checks: Iterate on quality checks with the stakeholders
Map source to target types: Convert to more specific types, where possible
Migrate data transformation logic: Rewrite the transformation logic in the new tool
Write schema and reconciliation checks: Write checks that compare source to target
Share data quality results: Share the results of data quality checks with stakeholders
Test user acceptance
Ask SMEs and consumers to test
Decommission
Proceed team by team, or use-case by use-case
Report on TCO
Analyze and share the results of the project
Manage Data Quality Across Migration
If data quality is the most common root cause of data migration failure, then let’s unpack what can go wrong and why.
This blog was created with previous versions of Soda Core and Soda Cloud, so there might be minor code syntax and UI path differences. If you have any questions refer to https://docs.soda.io/ |
|---|
Data quality issue | Potential root causes | SodaCL Checks |
|---|---|---|
Incomplete, missing records | Some data was left out during ingestion and transformation | Row count anomaly Count per categorical Missing values Valid values Metric reconciliation Record reconciliation |
Incomplete, missing columns | A number of columns were excluded or were completely empty and automatically dropped | Schema |
Duplicate rows | Data was mistakenly duplicated because no key was added to the join | Duplicate |
Data teams can measure the success of a data migration project by aggregating the check results. SodaCL reconciliation checks provide the most important measure of accuracy as they compare the source and target tables to identify differences at a metric and record level.
These checks make sure that the state of data in one system exactly matches the state in the other system. Sharing the results of these metrics with everyone increases transparency and trust in the migrated data.
For example, use a metric reconciliation check to evaluate the percentage of missing values in a column, and a record reconciliation check to validate that the employee name is the same in both the source and target tables.
You can implement Soda reconciliation checks as in the following SodaCL example which compares only the data specified in the list of columns, mapped according to order in which they are listed. See below:
In the example above, with more than six inconsistencies between data in the columns, the data quality check fails. The check result output in Soda Cloud identifies data quality reconciliation issues that you can address problems early, ideally in a staging environment, so as to prevent migrating data quality issues into production as you migrate the data itself.
Transition to the New Source
Many teams are reluctant to change for a variety of reasons. Therefore, it’s very important to work closely with your stakeholders, like subject matter experts and consumers. Make sure they plan time to test and migrate their processes to the new data source. Check in with them as they progress, and when they are finished, decommission the datasets in the old data source.
Best practice dictates that you run both systems in parallel for a short while and work iteratively towards complete transition. “Big bang” transitions seldom work out well.
To further motivate data teams to make the transition, you can also introduce new data management capabilities that further drive the adoption of the new data source. You can, for example, embark on a project to improve data cataloging, quality, security, retention, or access management. The easier the tools and processes, the more likely users will migrate.
Measure Twice, Cut Once
This old adage holds up well in the digital world of data migration: measure data quality in Staging using SodaCL reconciliation checks before cutting over to Production. We could even add “An ounce of prevention is worth a pound of cure” or “Garbage in, garbage out”. These proverbs prove that we’re all addressing the same kinds of challenges, and those of us who make the effort to prevent data quality issues early in a data migration project will fare much better.
Sign up for a Soda Cloud account, or install the latest version of Soda Library today to set your team up for success with reconciliation checks.
See Soda documentation for more details.
Learn more
Watch this 45-minute session to see:
Data migration use cases and best practices
A product showcase to test, manage, and assure data quality
Guidance on how to automate the reconciliation process to save time and resources
Data migration is the process of moving data from one system or storage environment to another. Data teams often tackle data migration projects when they need to permanently transfer data from one storage system to another. The benefits of these projects are typically reduced costs that come with consolidating systems and increased productivity, such as faster queries on unified data.
However, data migration projects come with risks. According to a 2007 report by Bloor Research, 84% of data migration projects overran time and budget; and on another report from 2011, the group’s survey found that poor data quality or lack of visibility into data quality issues was the main contributor to migration project overruns.
Without proper governance and quality checks, it often leads to data loss, corruption, and downtime. More often than not, the root cause of these failures is a lack of investment in systems and processes that ensure reliable, high-quality data.
When newly-migrated data appears to be inaccurate in a new storage system, end users are likely to distrust the data and go back to the old way of working. In an effort to mitigate that outcome, this article discusses several data migration best practices that use Soda to help address data migration risks.
Decide on your Approach
The first thing to think about is your approach.
Are you going with an incremental approach or a big bang?
Do you plan on running both systems in parallel for a while, and if so, for how long?
To decide on an approach, it’s best to create a stakeholder map that helps you understand who is using the system, for what purpose, and when each team can invest the time to migrate.
Plan your Data Migration
What follows are some of the steps to consider adding to your next data migration project planning.
Catalog data to be migrated
Document schemas and data types: Understand the variety of data in the system
Document volumes: Understand the volume of data processed daily
Define scope, priority, and stakeholders
Stack-rank datasets: What’s most important to do first?
Identify technical stakeholders: Which data and infrastructure engineers need to be involved?
Identify domain experts (SMEs): Which business SMEs can you leverage?
Identify key data consumers: Which consumers will do acceptance testing?
Document legacy data quality issues
Understand the problems of the past
Evaluate and pick tools
CI/CD: Which tool will you use to store and release code?
Ingestion: Which tool will move data from source to target?
Warehousing: Which SQL engine will you use?
Transformation: Which tool will build derived models and views?
Cataloging: Which tool will document data and stakeholders?
Quality: Which tool will evaluate data quality and debug issues?
Design first iteration
Select datasets: Take into account other projects
Profile and add baseline checks: Iterate on quality checks with the stakeholders
Map source to target types: Convert to more specific types, where possible
Migrate data transformation logic: Rewrite the transformation logic in the new tool
Write schema and reconciliation checks: Write checks that compare source to target
Share data quality results: Share the results of data quality checks with stakeholders
Test user acceptance
Ask SMEs and consumers to test
Decommission
Proceed team by team, or use-case by use-case
Report on TCO
Analyze and share the results of the project
Manage Data Quality Across Migration
If data quality is the most common root cause of data migration failure, then let’s unpack what can go wrong and why.
This blog was created with previous versions of Soda Core and Soda Cloud, so there might be minor code syntax and UI path differences. If you have any questions refer to https://docs.soda.io/ |
|---|
Data quality issue | Potential root causes | SodaCL Checks |
|---|---|---|
Incomplete, missing records | Some data was left out during ingestion and transformation | Row count anomaly Count per categorical Missing values Valid values Metric reconciliation Record reconciliation |
Incomplete, missing columns | A number of columns were excluded or were completely empty and automatically dropped | Schema |
Duplicate rows | Data was mistakenly duplicated because no key was added to the join | Duplicate |
Data teams can measure the success of a data migration project by aggregating the check results. SodaCL reconciliation checks provide the most important measure of accuracy as they compare the source and target tables to identify differences at a metric and record level.
These checks make sure that the state of data in one system exactly matches the state in the other system. Sharing the results of these metrics with everyone increases transparency and trust in the migrated data.
For example, use a metric reconciliation check to evaluate the percentage of missing values in a column, and a record reconciliation check to validate that the employee name is the same in both the source and target tables.
You can implement Soda reconciliation checks as in the following SodaCL example which compares only the data specified in the list of columns, mapped according to order in which they are listed. See below:
In the example above, with more than six inconsistencies between data in the columns, the data quality check fails. The check result output in Soda Cloud identifies data quality reconciliation issues that you can address problems early, ideally in a staging environment, so as to prevent migrating data quality issues into production as you migrate the data itself.
Transition to the New Source
Many teams are reluctant to change for a variety of reasons. Therefore, it’s very important to work closely with your stakeholders, like subject matter experts and consumers. Make sure they plan time to test and migrate their processes to the new data source. Check in with them as they progress, and when they are finished, decommission the datasets in the old data source.
Best practice dictates that you run both systems in parallel for a short while and work iteratively towards complete transition. “Big bang” transitions seldom work out well.
To further motivate data teams to make the transition, you can also introduce new data management capabilities that further drive the adoption of the new data source. You can, for example, embark on a project to improve data cataloging, quality, security, retention, or access management. The easier the tools and processes, the more likely users will migrate.
Measure Twice, Cut Once
This old adage holds up well in the digital world of data migration: measure data quality in Staging using SodaCL reconciliation checks before cutting over to Production. We could even add “An ounce of prevention is worth a pound of cure” or “Garbage in, garbage out”. These proverbs prove that we’re all addressing the same kinds of challenges, and those of us who make the effort to prevent data quality issues early in a data migration project will fare much better.
Sign up for a Soda Cloud account, or install the latest version of Soda Library today to set your team up for success with reconciliation checks.
See Soda documentation for more details.
Learn more
Watch this 45-minute session to see:
Data migration use cases and best practices
A product showcase to test, manage, and assure data quality
Guidance on how to automate the reconciliation process to save time and resources
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions