Introducing Incident Management for dbt, Powered by Soda
Introducing Incident Management for dbt, Powered by Soda
Introducing Incident Management for dbt, Powered by Soda

Bastien Boutonnet
Bastien Boutonnet
AI Team Lead & Product Management at Soda
AI Team Lead & Product Management at Soda
Table of Contents
Long Live dbt!
Let’s begin on a bold note: dbt is the de facto tool for analytical data transformations and we – like hundreds of thousands of others – love it.
As a data scientist, avid user, fan, and contributor (both dbt-core but also dbt-sugar), I can confidently testify to our bold statement. I’ve used dbt in all of my past data science roles, and in my last role at TripActions, I was involved in making the data analysts and data scientists super efficient using dbt, supercharging the data team, and getting everyone to work like a data engineer (without them realizing it, of course!). I’ve also got two Coalesce speaker badges, a keyring, a hat, and a supersoft sweater.
Powering the Modern Data Stack
When we spoke to the Soda community about which tools they use the most to get insights from raw data, dbt was certainly at the top of the list. Its transformation workflow helps build robust data pipelines and enforces the execution of data validation tests at the point the transformations are coded. dbt gets the data flowing.
Build or Buy
I’ve said it twice, and I’ll say it again, dbt is the best tool to write transformations. Because the data doesn’t stop flowing and organizations need end-to-end data observability, there’s a demand for additional tools that work across the entire data product lifecycle, to help teams better manage their data products.
It’s common for organizations to build a solution that parses failures at the end of a test run and creates an alert in Slack to trigger incident resolution. I know, because that's exactly what my team and I did at TripActions - we built a self-serve, low-code workflow so that anyone in the organization could access all the insights they need to make a decision. Our goal was to enable any team member to do more with data.
I learned though, that if an existing solution can free up your time and allow you to focus on what you enjoy doing, then you should buy the tool that does most of the work.
And that’s why, at Soda, we’re integrating the transformational power of dbt with the observability and incident management of Soda.
Free the Analytics Engineer
At Soda, we’re building data reliability tools and an observability platform to help data teams discover, prioritize, and resolve data quality issues. We've simplified a cumbersome process with a comprehensive, end-to-end workflow to detect and resolve issues, and automatically alert the right people at the right time.
We want to set the Analytics Engineers free! To this end, I’m delighted to announce our integration with dbt.
First Things First
Yes, Soda has out-of-the-box rules-based testing, anomaly detection, and distribution checks. Our ethos with respect to testing is the same as dbt – our tools are Open Source and use YAML, too – but we would be insane to encourage you to abandon the hundreds of tests that run in dbt and expect that you rewrite them in Soda. We strongly believe that you should leverage the tools that you know and love, which is why we prioritized this integration.
We know that there's massive benefit in ingesting your dbt test results into Soda Cloud. That’s the beauty of the modern data stack: it’s extensible and flexible enough that you can use the tools that are best-suited for the job at hand. Data observability is a key part of the modern data stack and, at Soda, we believe that we’re building the most robust platform for data teams.
This blog was created with previous versions of Soda Cloud, so there might be minor UI path differences. If you have any questions refer to https://docs.soda.io/ |
|---|
dbt + Soda
With dbt + Soda Cloud, data teams can augment the tests that they run in dbt. Watch the video to see dbt + Soda in action, ingesting dbt test results into Soda and using Soda Incidents.
We love it so much, we made two videos! Choose your flavor based on what you use: dbt core, or dbt Cloud.
dbt-core + Soda in Action
dbt Cloud + Soda in Action
Here are the highlights of each video
Add more testing capabilities to your dbt test results, including automated anomaly detection and schema evolution monitoring.
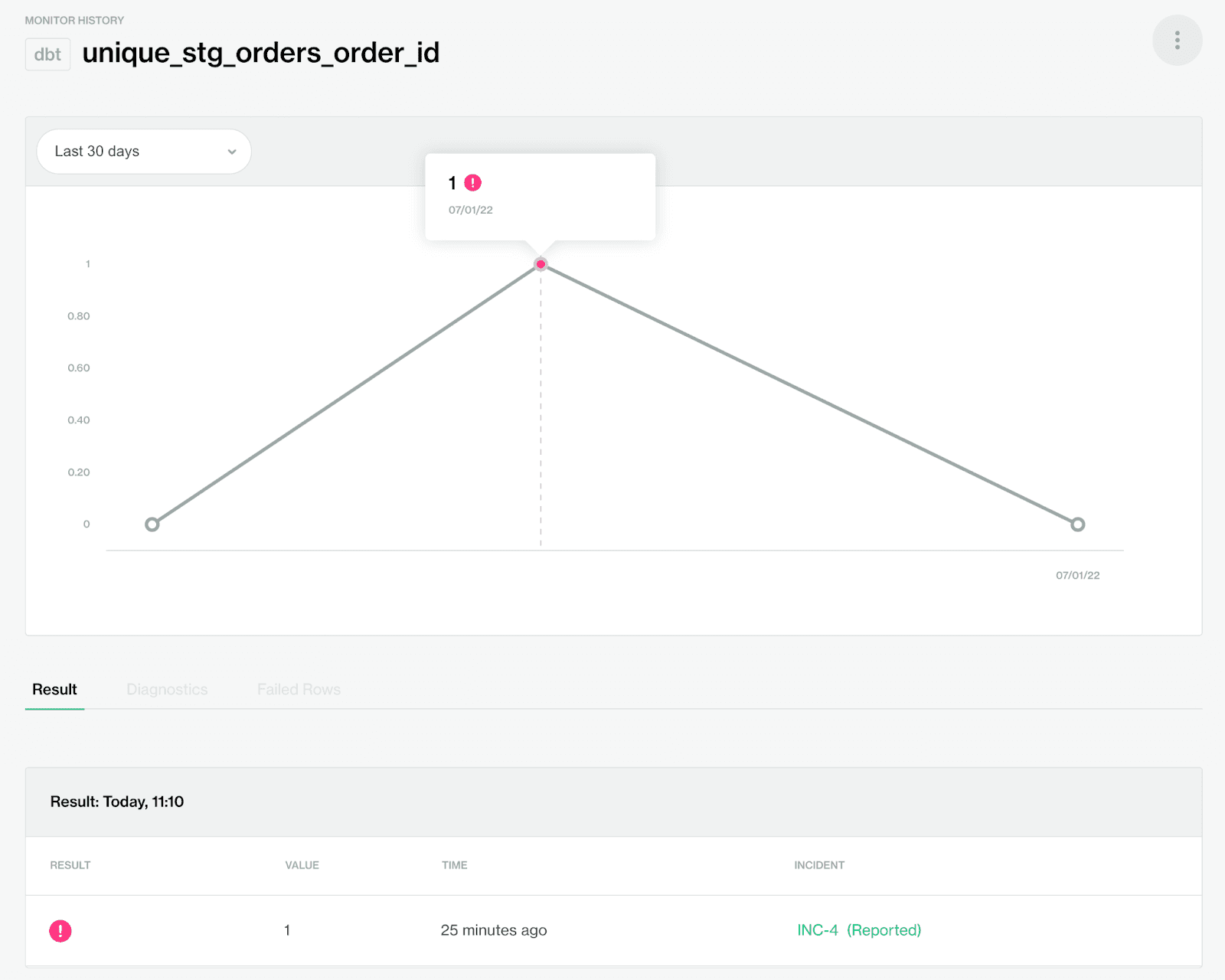
This image shows a dbt test result ingested into Soda Cloud, showing it’s status-over-time. Alerts and incident management can now be applied to the dbt test result.
Store dbt test results over time in Soda Cloud Metrics Store to test and validate data in a YAML file based on previously-observed values stored in the cloud. This testing-as-code allows you to leverage a baseline of what good data looks like when you write new tests.
Alert necessary stakeholders of test failures. Set up an integration between Soda Cloud and Slack so that your data teams are the first to know when data quality issues arise, and can fix the problem before there is downstream damage.
Manage data reliability and quality incidents, whether at the dataset or record level. Soda Incidents simplifies the process to detect, triage, diagnose, and resolve data issues across the entire data product lifecycle.

This gif shows how you can create an incident on an ingested dbt test failure.
Piecing It All Together
Data management in the modern data architecture is computationally tied into every step of the data flow and product lifecycle. Most data teams today are organized by domain and are composed of people in different roles such as an analytics engineer, an analyst, and a data product manager. Given the cross-functional nature of data, teams are dependent on each other to provide reliable high-quality data, every day.
We’re so proud to be able to bring all of the goodness of dbt to Soda Cloud, making it possible to support the entire workflow, end-to-end, for data management, data reliability, and data quality. Our integration helps dbt users connect to their data sources, conduct root cause analysis, and manage bad data quickly before it has a downstream impact.
Get Started with 24/7 Data Availability
We’re fortunate to count Disney, HelloFresh, Servier, and Udemy among those who have deployed Soda’s data reliability tools in production. And we love their contributions! Now it’s time for you to put Soda to the (dbt) test.
You can read our comprehensive docs on integrating dbt with Soda, or quickly get started with the following three steps.
Run some tests using dbt's
[test](<https://docs.getdbt.com/docs/building-a-dbt-project/tests>)or[build](<https://docs.getdbt.com/reference/commands/build>)commands, to capture test results. If you’re using dbt Cloud to schedule your jobs, make sure you run thesoda ingestcommand somewhere near the end of that job. (Currently dbt Cloud cannot trigger actions in other tools, but as soon as a more integrated option appears on the scene, we’ll be on it!)Call
soda ingest. First, make sure you have configure Soda SQL to connect to Soda Cloud. Then,pip install soda-sql-dbtand ingest dbt test results using the following command:
soda ingest dbt --warehouse-yml-file <path to warehouse.yml> --dbt-artifacts <path to dbt artifact jsons>
If you use dbt Cloud, we’ve got you covered! Check out our docs on how to set it up.
View, collaborate, and manage data quality incidents in Soda Cloud. Once ingested, Soda Cloud displays your dbt test results. You can immediately start setting up alerts or creating incidents.
If you’re new to Soda, you can quickly (and easily!) get started for free. You need to install Soda Tools, available as Open Source, and connect it to Soda Cloud, a free account available as a trial version. If you need help, contact the Soda Team in our Soda Community on Slack.
What’s Next?
The entire team and I are excited by the possibilities that dbt + Soda offers dbt users, establishing a true end-to-end data quality workflow, from detection right through to resolution.
Give it a try and let us know what you would like to see as a deeper integration with dbt. Here’s what we are working on:
Closer integration, where a run of dbt test may be able to trigger a run of
soda ingest.dbt allows users to
[store failures](<https://docs.getdbt.com/reference/resource-configs/store_failures>). Very soon,soda ingestwill be able to also get that information from dbt and show it to you. If you do not usestore_failures, then we’ll show you the compiled SQL so that you can get to the failing records in a jiffy!Ingest table-level lineage to help you see how datasets that are modeled using dbt connect together to help you with root cause analysis.
And just in case you use Great Expectations for testing, we're looking at providing a similar ingestion approach.
We’re also working on a really-cool-name-to-be-announced data reliability language, built to be included in a data pipeline. It will be freely available as Open Source and promises to change how we test and validate data, as-code… but more on that soon!
Long Live dbt!
Let’s begin on a bold note: dbt is the de facto tool for analytical data transformations and we – like hundreds of thousands of others – love it.
As a data scientist, avid user, fan, and contributor (both dbt-core but also dbt-sugar), I can confidently testify to our bold statement. I’ve used dbt in all of my past data science roles, and in my last role at TripActions, I was involved in making the data analysts and data scientists super efficient using dbt, supercharging the data team, and getting everyone to work like a data engineer (without them realizing it, of course!). I’ve also got two Coalesce speaker badges, a keyring, a hat, and a supersoft sweater.
Powering the Modern Data Stack
When we spoke to the Soda community about which tools they use the most to get insights from raw data, dbt was certainly at the top of the list. Its transformation workflow helps build robust data pipelines and enforces the execution of data validation tests at the point the transformations are coded. dbt gets the data flowing.
Build or Buy
I’ve said it twice, and I’ll say it again, dbt is the best tool to write transformations. Because the data doesn’t stop flowing and organizations need end-to-end data observability, there’s a demand for additional tools that work across the entire data product lifecycle, to help teams better manage their data products.
It’s common for organizations to build a solution that parses failures at the end of a test run and creates an alert in Slack to trigger incident resolution. I know, because that's exactly what my team and I did at TripActions - we built a self-serve, low-code workflow so that anyone in the organization could access all the insights they need to make a decision. Our goal was to enable any team member to do more with data.
I learned though, that if an existing solution can free up your time and allow you to focus on what you enjoy doing, then you should buy the tool that does most of the work.
And that’s why, at Soda, we’re integrating the transformational power of dbt with the observability and incident management of Soda.
Free the Analytics Engineer
At Soda, we’re building data reliability tools and an observability platform to help data teams discover, prioritize, and resolve data quality issues. We've simplified a cumbersome process with a comprehensive, end-to-end workflow to detect and resolve issues, and automatically alert the right people at the right time.
We want to set the Analytics Engineers free! To this end, I’m delighted to announce our integration with dbt.
First Things First
Yes, Soda has out-of-the-box rules-based testing, anomaly detection, and distribution checks. Our ethos with respect to testing is the same as dbt – our tools are Open Source and use YAML, too – but we would be insane to encourage you to abandon the hundreds of tests that run in dbt and expect that you rewrite them in Soda. We strongly believe that you should leverage the tools that you know and love, which is why we prioritized this integration.
We know that there's massive benefit in ingesting your dbt test results into Soda Cloud. That’s the beauty of the modern data stack: it’s extensible and flexible enough that you can use the tools that are best-suited for the job at hand. Data observability is a key part of the modern data stack and, at Soda, we believe that we’re building the most robust platform for data teams.
This blog was created with previous versions of Soda Cloud, so there might be minor UI path differences. If you have any questions refer to https://docs.soda.io/ |
|---|
dbt + Soda
With dbt + Soda Cloud, data teams can augment the tests that they run in dbt. Watch the video to see dbt + Soda in action, ingesting dbt test results into Soda and using Soda Incidents.
We love it so much, we made two videos! Choose your flavor based on what you use: dbt core, or dbt Cloud.
dbt-core + Soda in Action
dbt Cloud + Soda in Action
Here are the highlights of each video
Add more testing capabilities to your dbt test results, including automated anomaly detection and schema evolution monitoring.
This image shows a dbt test result ingested into Soda Cloud, showing it’s status-over-time. Alerts and incident management can now be applied to the dbt test result.
Store dbt test results over time in Soda Cloud Metrics Store to test and validate data in a YAML file based on previously-observed values stored in the cloud. This testing-as-code allows you to leverage a baseline of what good data looks like when you write new tests.
Alert necessary stakeholders of test failures. Set up an integration between Soda Cloud and Slack so that your data teams are the first to know when data quality issues arise, and can fix the problem before there is downstream damage.
Manage data reliability and quality incidents, whether at the dataset or record level. Soda Incidents simplifies the process to detect, triage, diagnose, and resolve data issues across the entire data product lifecycle.
This gif shows how you can create an incident on an ingested dbt test failure.
Piecing It All Together
Data management in the modern data architecture is computationally tied into every step of the data flow and product lifecycle. Most data teams today are organized by domain and are composed of people in different roles such as an analytics engineer, an analyst, and a data product manager. Given the cross-functional nature of data, teams are dependent on each other to provide reliable high-quality data, every day.
We’re so proud to be able to bring all of the goodness of dbt to Soda Cloud, making it possible to support the entire workflow, end-to-end, for data management, data reliability, and data quality. Our integration helps dbt users connect to their data sources, conduct root cause analysis, and manage bad data quickly before it has a downstream impact.
Get Started with 24/7 Data Availability
We’re fortunate to count Disney, HelloFresh, Servier, and Udemy among those who have deployed Soda’s data reliability tools in production. And we love their contributions! Now it’s time for you to put Soda to the (dbt) test.
You can read our comprehensive docs on integrating dbt with Soda, or quickly get started with the following three steps.
Run some tests using dbt's
[test](<https://docs.getdbt.com/docs/building-a-dbt-project/tests>)or[build](<https://docs.getdbt.com/reference/commands/build>)commands, to capture test results. If you’re using dbt Cloud to schedule your jobs, make sure you run thesoda ingestcommand somewhere near the end of that job. (Currently dbt Cloud cannot trigger actions in other tools, but as soon as a more integrated option appears on the scene, we’ll be on it!)Call
soda ingest. First, make sure you have configure Soda SQL to connect to Soda Cloud. Then,pip install soda-sql-dbtand ingest dbt test results using the following command:
soda ingest dbt --warehouse-yml-file <path to warehouse.yml> --dbt-artifacts <path to dbt artifact jsons>
If you use dbt Cloud, we’ve got you covered! Check out our docs on how to set it up.
View, collaborate, and manage data quality incidents in Soda Cloud. Once ingested, Soda Cloud displays your dbt test results. You can immediately start setting up alerts or creating incidents.
If you’re new to Soda, you can quickly (and easily!) get started for free. You need to install Soda Tools, available as Open Source, and connect it to Soda Cloud, a free account available as a trial version. If you need help, contact the Soda Team in our Soda Community on Slack.
What’s Next?
The entire team and I are excited by the possibilities that dbt + Soda offers dbt users, establishing a true end-to-end data quality workflow, from detection right through to resolution.
Give it a try and let us know what you would like to see as a deeper integration with dbt. Here’s what we are working on:
Closer integration, where a run of dbt test may be able to trigger a run of
soda ingest.dbt allows users to
[store failures](<https://docs.getdbt.com/reference/resource-configs/store_failures>). Very soon,soda ingestwill be able to also get that information from dbt and show it to you. If you do not usestore_failures, then we’ll show you the compiled SQL so that you can get to the failing records in a jiffy!Ingest table-level lineage to help you see how datasets that are modeled using dbt connect together to help you with root cause analysis.
And just in case you use Great Expectations for testing, we're looking at providing a similar ingestion approach.
We’re also working on a really-cool-name-to-be-announced data reliability language, built to be included in a data pipeline. It will be freely available as Open Source and promises to change how we test and validate data, as-code… but more on that soon!
Long Live dbt!
Let’s begin on a bold note: dbt is the de facto tool for analytical data transformations and we – like hundreds of thousands of others – love it.
As a data scientist, avid user, fan, and contributor (both dbt-core but also dbt-sugar), I can confidently testify to our bold statement. I’ve used dbt in all of my past data science roles, and in my last role at TripActions, I was involved in making the data analysts and data scientists super efficient using dbt, supercharging the data team, and getting everyone to work like a data engineer (without them realizing it, of course!). I’ve also got two Coalesce speaker badges, a keyring, a hat, and a supersoft sweater.
Powering the Modern Data Stack
When we spoke to the Soda community about which tools they use the most to get insights from raw data, dbt was certainly at the top of the list. Its transformation workflow helps build robust data pipelines and enforces the execution of data validation tests at the point the transformations are coded. dbt gets the data flowing.
Build or Buy
I’ve said it twice, and I’ll say it again, dbt is the best tool to write transformations. Because the data doesn’t stop flowing and organizations need end-to-end data observability, there’s a demand for additional tools that work across the entire data product lifecycle, to help teams better manage their data products.
It’s common for organizations to build a solution that parses failures at the end of a test run and creates an alert in Slack to trigger incident resolution. I know, because that's exactly what my team and I did at TripActions - we built a self-serve, low-code workflow so that anyone in the organization could access all the insights they need to make a decision. Our goal was to enable any team member to do more with data.
I learned though, that if an existing solution can free up your time and allow you to focus on what you enjoy doing, then you should buy the tool that does most of the work.
And that’s why, at Soda, we’re integrating the transformational power of dbt with the observability and incident management of Soda.
Free the Analytics Engineer
At Soda, we’re building data reliability tools and an observability platform to help data teams discover, prioritize, and resolve data quality issues. We've simplified a cumbersome process with a comprehensive, end-to-end workflow to detect and resolve issues, and automatically alert the right people at the right time.
We want to set the Analytics Engineers free! To this end, I’m delighted to announce our integration with dbt.
First Things First
Yes, Soda has out-of-the-box rules-based testing, anomaly detection, and distribution checks. Our ethos with respect to testing is the same as dbt – our tools are Open Source and use YAML, too – but we would be insane to encourage you to abandon the hundreds of tests that run in dbt and expect that you rewrite them in Soda. We strongly believe that you should leverage the tools that you know and love, which is why we prioritized this integration.
We know that there's massive benefit in ingesting your dbt test results into Soda Cloud. That’s the beauty of the modern data stack: it’s extensible and flexible enough that you can use the tools that are best-suited for the job at hand. Data observability is a key part of the modern data stack and, at Soda, we believe that we’re building the most robust platform for data teams.
This blog was created with previous versions of Soda Cloud, so there might be minor UI path differences. If you have any questions refer to https://docs.soda.io/ |
|---|
dbt + Soda
With dbt + Soda Cloud, data teams can augment the tests that they run in dbt. Watch the video to see dbt + Soda in action, ingesting dbt test results into Soda and using Soda Incidents.
We love it so much, we made two videos! Choose your flavor based on what you use: dbt core, or dbt Cloud.
dbt-core + Soda in Action
dbt Cloud + Soda in Action
Here are the highlights of each video
Add more testing capabilities to your dbt test results, including automated anomaly detection and schema evolution monitoring.
This image shows a dbt test result ingested into Soda Cloud, showing it’s status-over-time. Alerts and incident management can now be applied to the dbt test result.
Store dbt test results over time in Soda Cloud Metrics Store to test and validate data in a YAML file based on previously-observed values stored in the cloud. This testing-as-code allows you to leverage a baseline of what good data looks like when you write new tests.
Alert necessary stakeholders of test failures. Set up an integration between Soda Cloud and Slack so that your data teams are the first to know when data quality issues arise, and can fix the problem before there is downstream damage.
Manage data reliability and quality incidents, whether at the dataset or record level. Soda Incidents simplifies the process to detect, triage, diagnose, and resolve data issues across the entire data product lifecycle.
This gif shows how you can create an incident on an ingested dbt test failure.
Piecing It All Together
Data management in the modern data architecture is computationally tied into every step of the data flow and product lifecycle. Most data teams today are organized by domain and are composed of people in different roles such as an analytics engineer, an analyst, and a data product manager. Given the cross-functional nature of data, teams are dependent on each other to provide reliable high-quality data, every day.
We’re so proud to be able to bring all of the goodness of dbt to Soda Cloud, making it possible to support the entire workflow, end-to-end, for data management, data reliability, and data quality. Our integration helps dbt users connect to their data sources, conduct root cause analysis, and manage bad data quickly before it has a downstream impact.
Get Started with 24/7 Data Availability
We’re fortunate to count Disney, HelloFresh, Servier, and Udemy among those who have deployed Soda’s data reliability tools in production. And we love their contributions! Now it’s time for you to put Soda to the (dbt) test.
You can read our comprehensive docs on integrating dbt with Soda, or quickly get started with the following three steps.
Run some tests using dbt's
[test](<https://docs.getdbt.com/docs/building-a-dbt-project/tests>)or[build](<https://docs.getdbt.com/reference/commands/build>)commands, to capture test results. If you’re using dbt Cloud to schedule your jobs, make sure you run thesoda ingestcommand somewhere near the end of that job. (Currently dbt Cloud cannot trigger actions in other tools, but as soon as a more integrated option appears on the scene, we’ll be on it!)Call
soda ingest. First, make sure you have configure Soda SQL to connect to Soda Cloud. Then,pip install soda-sql-dbtand ingest dbt test results using the following command:
soda ingest dbt --warehouse-yml-file <path to warehouse.yml> --dbt-artifacts <path to dbt artifact jsons>
If you use dbt Cloud, we’ve got you covered! Check out our docs on how to set it up.
View, collaborate, and manage data quality incidents in Soda Cloud. Once ingested, Soda Cloud displays your dbt test results. You can immediately start setting up alerts or creating incidents.
If you’re new to Soda, you can quickly (and easily!) get started for free. You need to install Soda Tools, available as Open Source, and connect it to Soda Cloud, a free account available as a trial version. If you need help, contact the Soda Team in our Soda Community on Slack.
What’s Next?
The entire team and I are excited by the possibilities that dbt + Soda offers dbt users, establishing a true end-to-end data quality workflow, from detection right through to resolution.
Give it a try and let us know what you would like to see as a deeper integration with dbt. Here’s what we are working on:
Closer integration, where a run of dbt test may be able to trigger a run of
soda ingest.dbt allows users to
[store failures](<https://docs.getdbt.com/reference/resource-configs/store_failures>). Very soon,soda ingestwill be able to also get that information from dbt and show it to you. If you do not usestore_failures, then we’ll show you the compiled SQL so that you can get to the failing records in a jiffy!Ingest table-level lineage to help you see how datasets that are modeled using dbt connect together to help you with root cause analysis.
And just in case you use Great Expectations for testing, we're looking at providing a similar ingestion approach.
We’re also working on a really-cool-name-to-be-announced data reliability language, built to be included in a data pipeline. It will be freely available as Open Source and promises to change how we test and validate data, as-code… but more on that soon!
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions