
We have significantly improved the capability of SodaCL and now there is Soda Contract Language. Go here for more information: Introducing Soda 4.0
Last year, we released Soda SQL to help data engineers maintain reliable data pipelines in production using an open-source framework. It was built to do three things really well with SQL-accessible data: profile, test, and monitor data.
This was our first open-source project that aimed at enabling Data Engineers to monitor their critical decision workflows, without the struggle of maintaining unwieldy, homegrown data-testing solutions.
Soda SQL used a combination of YAML input and SQL queries that focused on data reliability. We went all-in on SQL for three main reasons:
it allowed you to leave your data exactly where it wasit offered a lot of flexibilitySQL is a popular programming language
it allowed you to leave your data exactly where it was
it offered a lot of flexibility
SQL is a popular programming language
You can read more in my blog post that announced last year’s launch of Soda SQL into the community.
We watched the uptake of Soda SQL increase and proudly saw the Soda community grow and evolve into an engaging channel. My previous work in building open-source projects at Activiti and jBPM taught me the value of community and how fun it is to build something together.
It also taught me the importance of listening and learning from users. With open-source, of course we don’t know every single engineer or organization that tallies up the thousands of daily downloads, however, we are able to count Disney, HelloFresh, and Udemy as major contributors to have deployed Soda’s data reliability tools and supported the development of our projects.
What was true then is even truer now: data quality is a team sport, and everyone who has a stake in data (i.e. everyone in the business) needs to understand it, trust it, and stay on top of it.
Almost every company is automating processes and creating innovative new products and services using data, but the key challenge for teams across an organization is having data that is reliable enough to meet these complex and evolving needs. By providing highly-configurable, open-source, SQL data testing capabilities, we took the first step towards empowering Data Engineers with the right tools to meet these challenges and establish a solid foundation of reliable data quality.
But we knew there was more that we could do to better serve the Data Engineering and Analysts of the world, who often find themselves firefighting data issues when reports, dashboards, or machine learning models break.
As our Data Engineering team engaged with our community and we watched the use and evolution of Soda SQL (and its siblings Soda Spark and Soda Streaming) in production, it became clear that we needed to take it to the next level. Our users confirmed that what we had was good – or great, in comparison with incumbent solutions – but their greatest challenge was enabling their businesses to maintain ownership and be accountable for their data.
And that’s why Milan Lukac, Vijay Kiran, and I, spent the next few months building a new domain-specific language for data reliability-as-code.
Not Another DSL
I know, “why does the world need another domain-specific language?” The question hints at the perceived burden of learning another language and, horror of horrors, vendor lock-in. We know, we get it – those are the same worries we would have, too, if we were thinking about using a new tool. Hear me out.
With a domain-specific language, you typically have to deal with the difficulties of integrating a new DSL into existing systems and working with a relatively low supply of support materials and practitioners. And this DSL would not magically avoid those challenges, but data reliability needs its own language. It needs a language that is specific enough to address the problems that data teams face, accessible enough for non-engineers to use, and flexible enough to dig into lots of different kinds of data to find, analyze, and resolve issues fast. In the long run, it will be worth the short-term capital outlay of time and effort.
Besides the very real need for a data reliability language, a new DSL could be what unlocks the cumbersome tasks of detecting and resolving data issues, and automatically alerting the right people at the right time. This opensource.com article titled What developers need to know about domain-specific languages bolstered our enthusiasm when we were initially considering the idea, daring ourselves to imagine A Better Way of Doing Things. It’s a bold move, but we think it’s about time that data teams and the tools they use get some bold and invigorating attention.
And that is how a new open-source Soda DSL was born: a human-readable language that will revolutionize the way teams set up and maintain reliable, high-quality data products.
We know that there are thousands of data team members who are looking for a simplified method for detecting, triaging, diagnosing, and resolving data quality issues across the entire data product lifecycle. As data teams seek to operationalize data products, this could be a total game-changer.
The Rise of Data Mesh
I think we’re seeing a revolution in the way that data, and data teams, operate within organizations. From our own observations, we’ve seen data teams change the way they organize themselves: in a data mesh, teams are built by domain.
It’s an interesting construct, one about which a thought-provoking book is being written (see Zhamak Dehghani’s Data Mesh: Delivering Data-Driven Value at Scale), and in my opinion, data mesh aligns well with today’s modern data stack. Few people in the data management space aren’t exploring, adopting, interpreting, or talking about data mesh.
Here’s how Zhamak describes it in our Data Dream Team Podcast with Jesse Anderson:
"...data mesh is really an approach that affects both organizational structure and architecture in managing and sharing data for analytical use cases. [...] at its heart it is a decentralized approach [...] that believes in making sure our domains - take the line of business domains - have the accountability and support to share data, use data for analytical purposes. [...] So, the core of it is the idea of decentralization of data sharing to the domains."
The idea of “decentralization of data sharing” strikes a chord with me. It makes sense that data ownership is shared amongst data domain teams – teams made up of Data Engineers, Data Product Owners, and Data Scientists and Analysts – and that those teams take ownership of their data quality.
In this kind of environment, we’ve seen data domain teams establish Service Level Objections or Service Level Agreements with the consumers of the data products. These agreements set expectations between the domains, so that everyone who wants to use the data to create a dashboard or feed an ML algorithm has a clear understanding of the data they’re working with and can trust that the data is timely, valid, accurate, and complete. That the data is trustworthy.
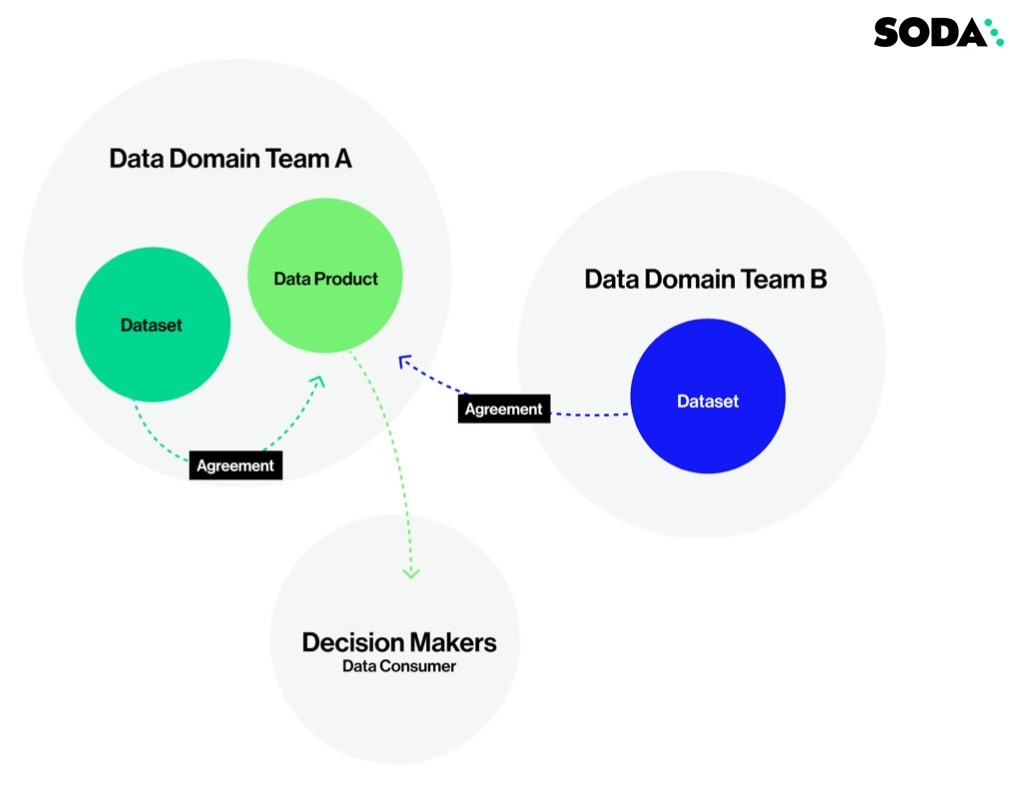
Agreements allow data producers and consumers to align on data quality expectations.
As Zhamak explains: “Data mesh’s promise of scale can only be fulfilled if the life cycle of a data product can be managed autonomously, when a data product can be built, tested, deployed, and run without friction and with limited impact on other data products. This promise must remain true while there is interconnectivity between data products — through their input and output data ports, sharing data, or schemas.”[1]
SodaCL: A Data Reliability Language for Data Mesh
After listening to our users and being inspired by our observations of organizations evolving into a data mesh, we were even more encouraged to go ahead and build a DSL that data reliability needs: SodaCL. Our collective dream is that the Soda Checks Language will become the open-source standard for data reliability.

In the image above Leslie and Will are creating an agreement that ensures that the data for Leslie’s enterprise customer churn model is fresh and timely and that anomalous records are scrutinized before the data is delivered.
I can’t help but say that I’m really proud of what our team achieved with our first iteration of our purpose-built language.
Test and monitor data checks-as-code. You can set up dynamic checks, manage data checks-as-code from ingestion through transformation, and you can manage check files using Git.
Take advantage of over 30 built-in check types. Get value immediately by using the metrics that we’ve built into the language. When things get more complicated, you can still revert to SQL metrics to get the job done.
Enable your colleagues to self-serve. Not all data issues are engineering-related. With one, intuitive, human-readable language, everyone can define what qualifies as good data, which frees up valuable engineering time.
And this is just the beginning!
As French is the Language of Love, SodaCL is the Language of Data Reliability
Our data reliability and observability tools are built by Data Engineers and product owners, all of whom have first-hand experience with building reliable systems that produce high-quality data.
We know that data teams need a data reliability language that is accessible via the command-line and flexible enough to be embedded into a technical environment, such as Airflow or Prefect. Most importantly, we know that Engineers need an extensible solution that offers transparency and full control.
Yet, as Maarten Masschelein, Soda’s CEO and my fellow co-founder, has always reminded me and the entire team, our ultimate benefactor is the Data Analyst, the consumer of the data. We need to enable Analysts to fully self-serve because when an Analyst can write their own checks for data quality, a business can really begin to scale its data reliability coverage.
Where Data Analysts are heavily reliant on Data Engineers to implement data checks, it is impossible to scale without running into the bottlenecks that can cripple the business. For every organization that relies on data to drive revenue through confident decision-making, every minute of data availability matters.
Using SodaCL, Analysts who are equipped with the data domain knowledge can simply author their own checks, analyze incidents, and fix issues so that data quality remains trustworthy and available at all times.
Need to check for duplicates? Easy:
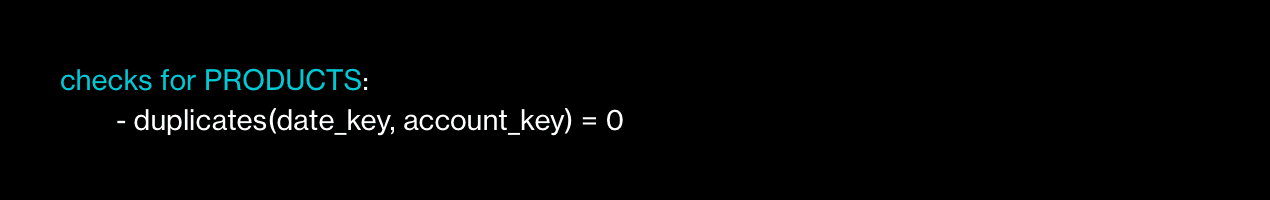
Compare row counts between data sources? Got it:

Get a warning when a dataset’s schema changes? No problem:
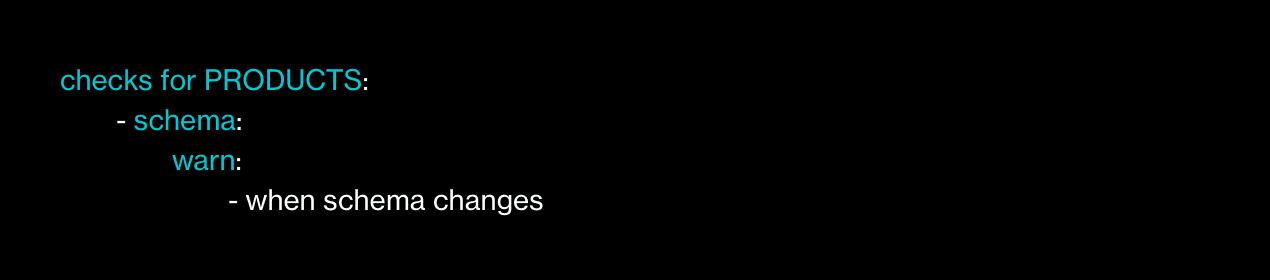
These built-in metrics make it far easier for a broader range of people to participate in the work of establishing and maintaining data quality. And where the going gets tough, where the built-in metrics can’t reach far enough into the complexity of the data to check what needs to be checked, a Data Engineer or other SQL expert can step in and add their own SQL queries using the same language framework.
Data teams, hear us loud and clear: SodaCL was built to make your life easier and your data reliable.
I’d Like to Teach the World to Code in Perfect Harmony
As mentioned above, SodaCL’s out-of-the-box, built-in metrics aim to save time and resources. Your whole team can use these metrics to write checks that are easy for Data Engineers to implement and which reduce the time-to-value by avoiding the need to write a ton of SQL.
Here is a sample of 30+ metrics we’ve included in SodaCL, based on the most common and frequent data issues hurting data teams today.
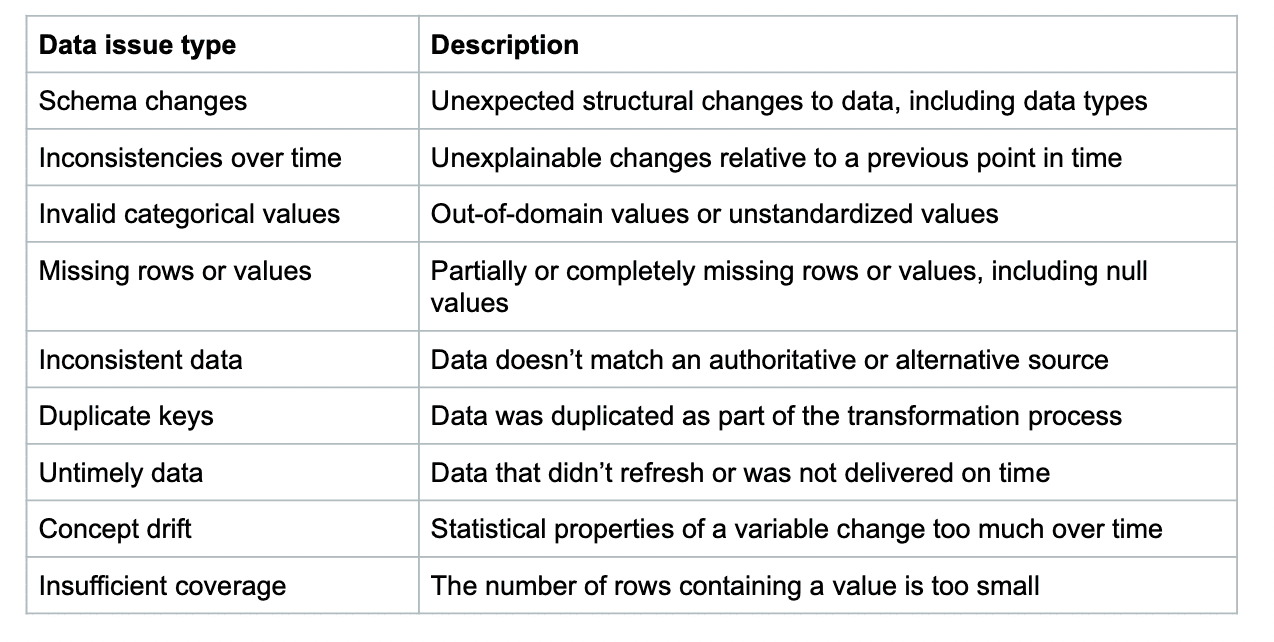
The metrics we chose to include in SodaCL are distilled from a list of 80+ metrics that we gathered from our users in the Soda community. We also referenced standard data issue types from data associations such as DAMA the original definer of data governance principles.
Further, we studied leading organizations such as Airbnb, Netflix, and Uber to adopt some of their best practices and wisdom when it comes to data management. As we continue to study real-life examples and gather more input from users, we’ll continue to expand SodaCL’s library of built-in metrics.
Developing XaC (Everything As Code)
A data reliability language can help unify data teams across the entire data product lifecycle and empower them to specify what good data looks like, irrespective of roles, skills, or subject matter expertise.
But a data reliability language as-code?
I’m not sure I can put it any better than Adrian Bridgewater, a technology journalist who tracks developers and data at Computer Weekly, Forbes, and IDG Connect, when he writes:
“[...] ‘Of course, code will drive everything; that’s why we’re building applications, establishing database procedures, and looking to the future when artificial intelligence (AI) finally graduates out of the movies,’ said any given software developer in the 1980s and probably most of them in the 1990s, too.”
Everything-as-code is driving today’s software practices and we were able to validate our SodaCL approach with a few of our integration partners, such as dbt. They, too, believe in making data teams more effective with code and their ethos favors code over GUI.
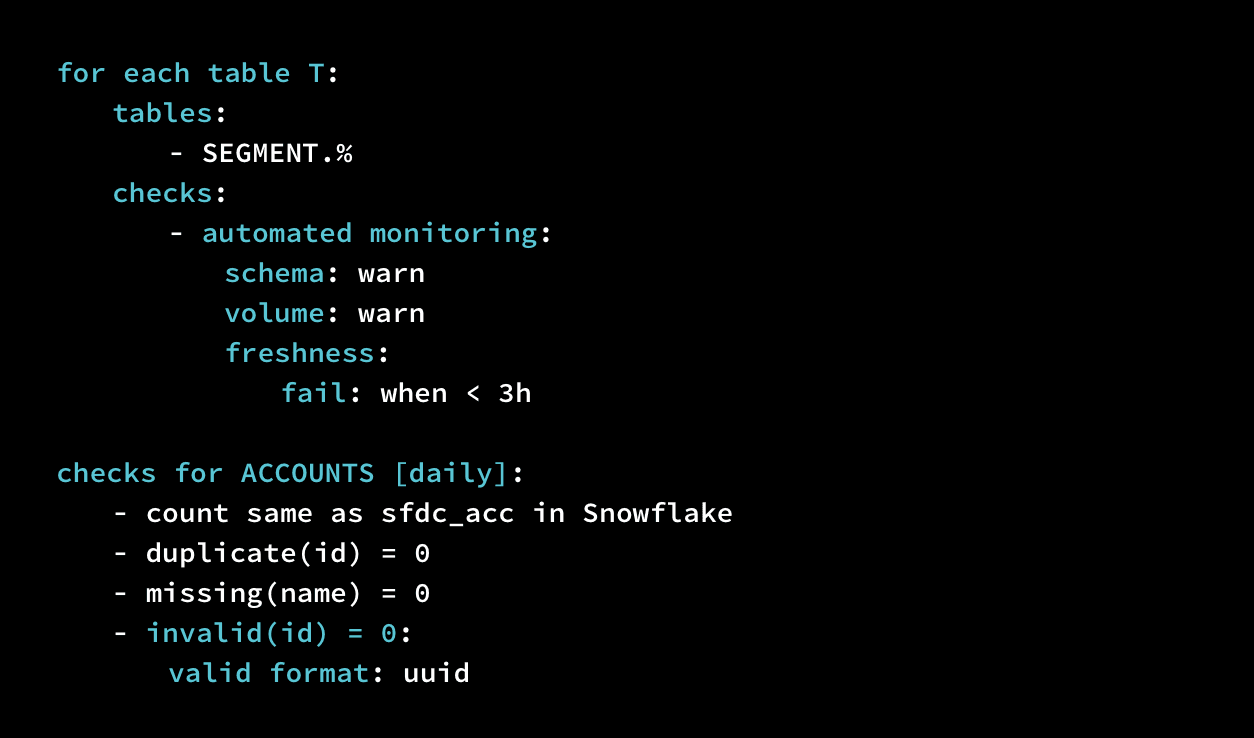
Use SodaCL to run the same checks for each dataset in a data source.
Of course, so much autonomy and self-serve functionality requires guardrails and governance that enable everyone to safely and comfortably work with code. To that end, SodaCL adopted the principles of computational governance [2], baking in the standards and global policies to which all data domains must adhere. This frees the SodaCL user to focus on defining good-quality data, building trusted data products, and bringing everyone closer to their data.
In one of Adrian’s articles he concludes that:
“Our world is now cloud-first, code-first, and data-first. With everything-as-code pushing data solutions forward, it will be important to keep an eye out on the future of data innovation.”
And So it Begins
To start getting feedback into our early working version of SodaCL, we’ve launched a preview program which will ensure that we take the responsible steps to make sure we’re getting it right for Data Engineers. It’s been hard to contain our excitement about releasing this new, innovative approach for collaborating on data reliability, and so we’re happy to find a way to share it with the community in the spirit of open-source!
Here’s a recording of Vijay Kiran, our Lead Data Engineer, offering preview program participants a walkthrough of SodaCL in action.
If you’re already a user of Soda and want more info, please contact our Customer Success Team.
If you’re new to Soda and interested in joining the preview program, please sign up below and we’ll get back to you within 48 hours.
In the meantime, we’ll be busy applying the finishing touches so we can make SodaCL generally available in just a few weeks time. The excitement is palpable! Join the Soda Community on Slack to be among the first to know when SodaCL drops!











