
In the last five years, we’ve seen an immense influx of software engineers into the data space. Data was, and still is hot. My co-founder Tom, was one of those engineers. Attracted by complex, high-impact problems, many software engineers quickly realized that although some systems were incredibly sophisticated, others were non-existing. The best practices that software engineers adopted as common practice were not there yet in data, and that caused a lot of headaches for teams building and operationalizing data products - automations driven by data.
We’ve also seen the modern data stack – tools and technologies to meet the needs of data teams – explode. This demand is accompanied by a paradigm shift – yes, I’m talking about data mesh – in how we manage and organize ourselves at scale around data. With all of this innovation and development, I chuckle to think that we are nearing an era of the post-modern data stack.
It’s A New Dawn
Still today, there is a lot of fundamental work to be done. Do you remember a few years ago when the headline statistics were about how much time data scientists were spending scrubbing and preparing data to train their models? Eighty percent. 80%! That left just twenty percent of their working hours to do real data wizardry. It didn’t take long for the industry to realize that more fundamental work was needed to alleviate those pains. Work that only data engineers could do.
In most teams, data engineers are responsible for building systems and pipelines to ingest, model, and deliver data products to the business. Data products have become instrumental in creating competitive advantage, allowing an organization to deliver delightful customer experiences, or explore new market avenues.
But building and maintaining data products is no easy feat. Once in production, data products need constant attention to address changes to data schemas and structures, broken transformation logic, and concept drift, all of which impact reliability, quality, and, ultimately, trust in the data.
And The Survey Says…
The role of a data engineer, in my opinion, is one of the most crucial roles on a data team. It often involves the relentless task of manually fixing data issues that have already had a downstream impact on the business. When reports or machine learning models break, the future revenue and success of an organization can be wholly dependent on data engineers firefighting the data quality issues that are causing the problems. When that alarm bell rings, they need to madly scramble to find out what has broken and what has been impacted.
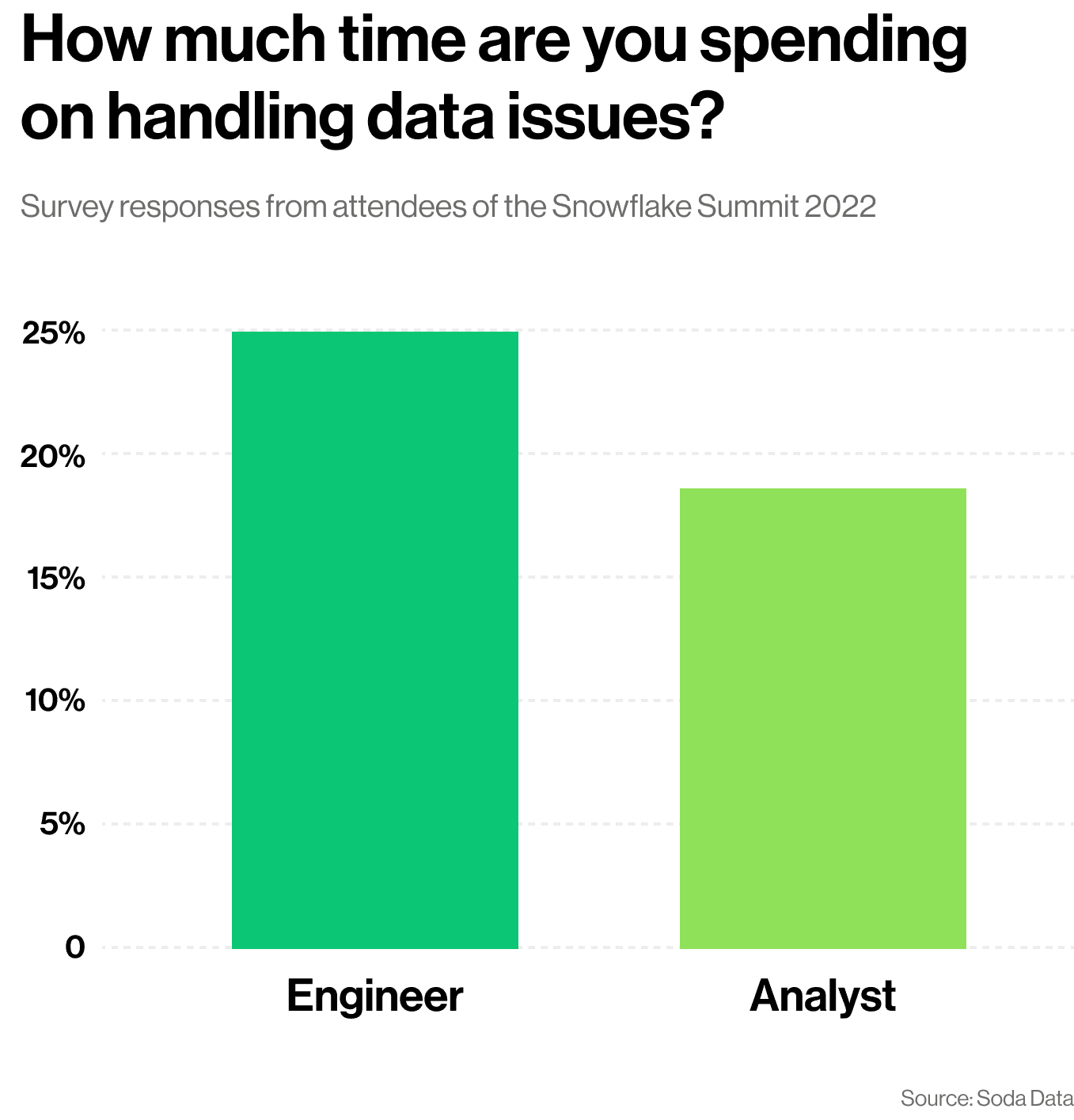
A recent survey conducted by Soda at Snowflake Summit 2022, showed that data engineers spend, on average, approximately twenty-five percent of their time handling data issues. For data analysts, this was approximately twenty percent of their time.
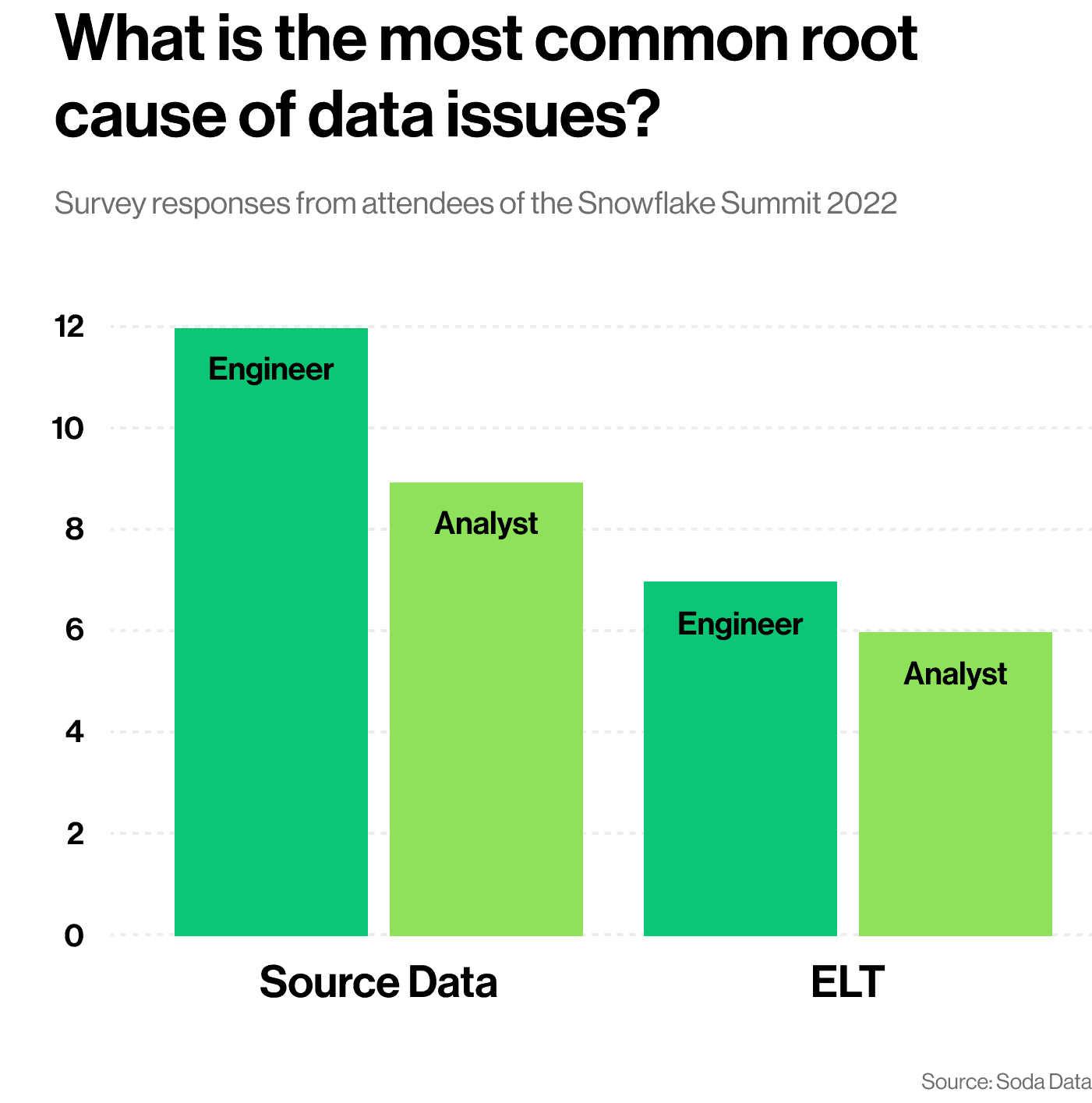
When a data issue is detected, in sixty-two percent of the cases the root cause is at the source of the data.
As the number of sources and types of data that businesses accumulate continues to expand in volume and complexity – first-party data generated in-house, second-party data produced from collaborations, third-party data acquired externally – it becomes easy to see why we need a better way to manage changes to data.
One of the questions we asked in our survey at the Snowflake Summit 2022 was
“What is the bottleneck when it comes to analyzing and resolving data issues?”
The overwhelming amount of responses we received pointed at the lack of tools, processes, and expertise to create more reliable and high-quality datasets.
The cost and impact of data downtime means disruption to the business, loss of revenue, productivity loss, regulatory or compliance issues, decreases in customer retention, and dips in employee satisfaction. Most importantly, data downtime means an increased skepticism of the data itself.
This blog was created with previous versions of Soda Core, so there might be minor code syntax differences. If you have any questions, refer to https://docs.soda.io/ |
|---|
Bringing Reliability Engineering to Data
In 2021, we released Soda SQL to help data engineers maintain reliable data pipelines in production using an open-source framework. Earlier this year, we announced our continued commitment to better serve teams with the release of a new Domain-Specific Language for data reliability, and an improved open-source framework. The newest framework enables data teams to check data as-code, across every data workload, from ingestion to transformation to consumption.
Tom wrote a blog post that dives into the details of the Soda Checks Language.
To introduce a new domain-specific language to power our open-source framework is a bold move! But as we listened to our community and surveyed the landscape, we knew this would be the key to enabling data teams to deliver on the promise of good-quality data.
And so, drum roll please, allow me to introduce the general availability of Soda Core, the framework for data quality and reliability!
Data Engineering Just Got A Whole Lot Easier
Now generally available, Soda Core is an open-source framework for data engineers to get started and scale with reliability engineering and data quality management. Powered by Soda Checks Language (SodaCL), it unblocks the cumbersome tasks of detecting and resolving data issues, and automatically alerting the right people at the right time.
SodaCL is powerful, human-readable and -writable, and easy to configure. We know it will change the way data engineers deliver reliable data products.
Let me dive into the components that can be built into your existing data stack, and why they’re important.
The Important Components
Profiling and data classification
Use dataset metadata to understand the shape of the data - examine and analyze characteristics including, but not limited to, mean, minimum, maximum, percentile, and frequency. Capture the historical information about the health of data to form a baseline, and support the intelligent testing of data across every workload.
Metrics and checks
Use built-in metrics and checks to validate a great number of data quality parameters. Checks test your data, typically as part of the data delivery process, after a data transformation, or within a data sharing agreement.
Create a broad check coverage to surface the widest range of data quality issues. And, because every business is different, you can use user-defined checks to address more complex, domain-specific checks for data quality.
Fixed and dynamic thresholds
Access historic measurements and write tests that use these in just one line of SodaCL. Test and validate data with dynamic threshold systems like change-over-time and anomaly detection, as part of a comprehensive end-to-end workflow that helps detect and resolve issues, and automatically alert the right people at the right time.
Alerts and notifications
Send alerts to your favorite ticketing or on-call systems. Not all data issues are engineering related so at some point, data producers and consumers need to get involved as well.
Extending Soda Core with a Soda Cloud account, you can route notifications to the right people, and allow less technical users to get involved by adjusting thresholds or adding new checks altogether. Because there is one language - writable and readable by (almost) everyone - everyone can define the thresholds of what good data looks like.
Let's look at some real world examples:
Check One, Check Two
Check data during development and in-production
When data flows from operational systems into analytical ones, test every stage of the journey to catch unforeseen problems. Testing data is essential, as essential as software engineers test code before releasing into production. We’ve learned that testing in production at critical handover points - when data is ingested - as well as when new analytics code is released into production, are key.
Take a look at these examples:

Compare the CUSTOMERS dataset with RAW_CUSTOMERS in another data source.

Check for the freshness in your dataset using the row_added_ts timestamp column.
Monitor or circuit-break
Once bad quality data has entered the analytical system, it becomes a nightmare to clean up. Typically, you have to perform corrections on the historical data (backfilling). This is manual, time-consuming, and error prone.
Circuit breakers can prevent this. Circuit breakers are checks that, when they fail, stop the pipeline, and quarantine bad data for the data producer or consumer to review. Configure a programmatic scan to add a circuit-breaker to your orchestrator, or, add monitor checks to all your datasets as mocked up below:
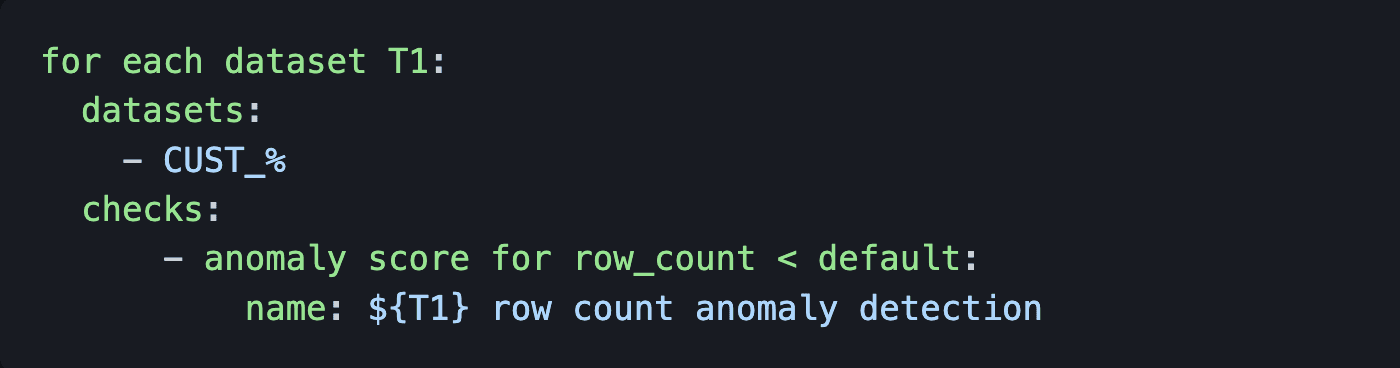
Check for anomalies in the row count of all datasets that start with “CUST_”.
Define good, reliable, and quality levels of data
As painful as it may be to hear it, data teams should almost never strive for one hundred percent data quality because it's hard to achieve, and it often results in small marginal gains for a lot of extra effort. In almost all cases, the user impact beyond a certain percentage is negligible.
Soda’s new human-readable DSL, makes it easier for data producers or consumers to tackle data quality issues on their own. As a more accessible DSL, SodaCL empowers a far broader range of team members in the continuous and ever-evolving quest for good-quality data.
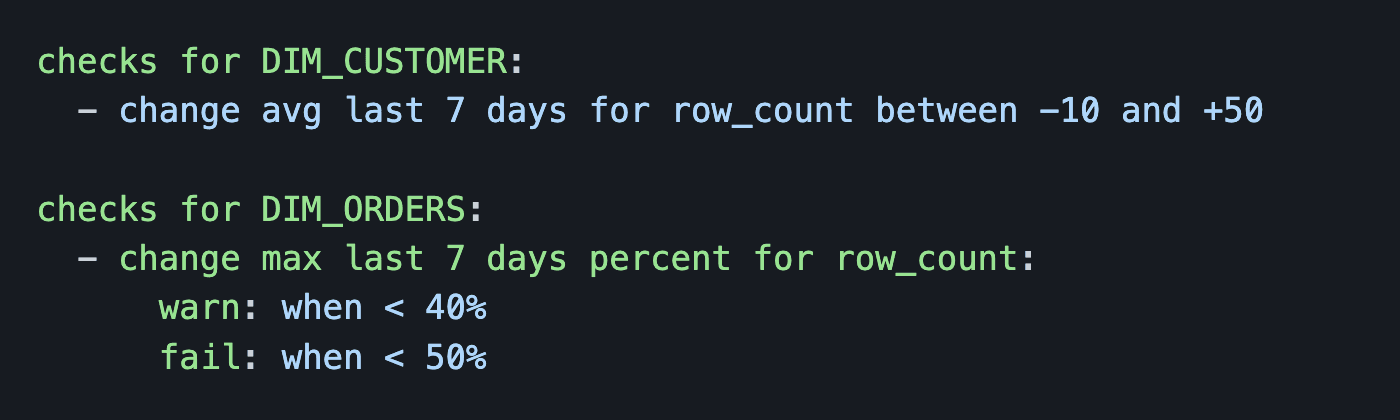
Check the 7-day trailing average of your row count. And check the relative percentage difference between max of the last 7 days with the current value and with a warning and failure level.
Principled By Design
Easy to use, with minimal dependencies
When designing Soda Core, we obsessed over ease-of-use. This has resulted in hundreds of small decisions, like making two different modes available: a command-line interface, and a Python library to create programmatic scans; and keeping the list of dependencies to install as minimal as possible.
Human-readable and writable check configurations
Delivering on high-quality, reliable data products that your users love cannot be done in isolation. To achieve this, different stakeholders and teams need to work together. That’s why having human- readable and -writable check configuration is key, as it enables everyone to get involved.
Able to run everywhere to create end-to-end observability
Many of the teams we’ve worked with wanted to be able to test data as early as possible in their upstream. Soda started by analyzing SQL-accessible data, but quickly included Spark DataFrames and Streaming as well.
Into the Wild
The community feedback in the last year has been amazing. Thousands of data teams have started using our open-source Soda software. We owe thanks to the original incarnations of Soda OSS software, Soda SQL, and Soda Spark.
The preview and beta programs that we ran for SodaCL and Soda Core, in addition to the contributions from companies like HelloFresh, Disney, Udemy, have significantly contributed to make our open-source software ever better.
What’s Next?
First things first, the team and I will be eagerly watching the first uses of Soda Core on GA day, Tuesday June 28, and those GitHub stars and downloads rise up!
We are thrilled and very excited to make Soda Core available to all the data engineers around the world, knowing that this will make their lives a lot easier.
Next, we’re turning our attention to Soda Cloud and improving the self-serve capabilities for the data consumers, as we continue to simplify the process to detect, triage, diagnose, and resolve data issues - for everyone - across the entire data product lifecycle.
Now it’s over to you, to go and explore Soda Core. We’d love to hear your feedback.
Join the conversation in our Slack Community.











