Published
Nov 16, 2023
Soda Releases OSS Data Contract Engine

Why Data Contracts?
Data contracts are a foundation for data producers to take responsibility over the datasets they own. In a data contract, they communicate the "API for data". Using the contract, data consumers can find out what data is available and how it can be used.
The focus on this "API for data" was triggered by the Data Mesh movement started by Zhamak Dehghani. Data Mesh is a great strategy for architecting data products at scale. It applies software engineering principles such as Domain-driven Design (DDD) and micro services to data.
Without the ideas of Data Mesh and a concrete implementation of data contracts, there is a tendency towards building spaghetti pipelines that no one can take ownership of, and no one dares to touch. Introducing data contracts is an implicit enabler to establish ownership. If data producers can rely on their input (because of trustworthy contracts), they can, in turn, product reliable contracts for all of the data products they produce.
For contracts to be effective and not drift away from reality, they must be enforced. Enforcing a contract means continuously verifying that new data matches the data contract each time new data is produced. That's where Soda comes in. Consider Soda as the enforcement engine for data contracts. Soda will continuously verify that your contract is up-to-date and correct.
Using a YAML language as the foundation for contracts fits with the shift-left motion that is going on in data. It means driving the data management processes as much as possible from engineering artefacts that are managed by engineers, to the source (a.k.a. upstream). This enables faster detection of problems and more options to quarantine bad data before it causes harm to data applications.
Use Cases for Data Contracts
Data contracts serve many important use cases.
The API for data: Consumers that are searching for data with which to build new products need to understand what data is available and how it can be used. In that sense, data contracts become the system of record for operational metadata that can be surfaced in data catalogs.Protecting storage: Databases have schemas to prevent bad data from entering storage. Kafka has schema registries to prevent bad data from entering topics. In the same way, analytical datasets will get contracts to prevent bad data from being stored.Protecting usage: Consumers can add (or let others add) data quality checks that are relevant to their usage. Users often have much more intimate knowledge about the data or about specific requirements. Letting them add data quality checks enables them to protect their usage.
The API for data: Consumers that are searching for data with which to build new products need to understand what data is available and how it can be used. In that sense, data contracts become the system of record for operational metadata that can be surfaced in data catalogs.
Protecting storage: Databases have schemas to prevent bad data from entering storage. Kafka has schema registries to prevent bad data from entering topics. In the same way, analytical datasets will get contracts to prevent bad data from being stored.
Protecting usage: Consumers can add (or let others add) data quality checks that are relevant to their usage. Users often have much more intimate knowledge about the data or about specific requirements. Letting them add data quality checks enables them to protect their usage.
Soda's Data Contracts Strategy
At Soda, we have a history of building an execution engine for data quality checks. This started with the release of Soda SQL in 2021 and Soda Core in 2022 (Apache 2.0). This OSS engine is the perfect basis for data contract enforcement.
Today, there are already multiple variations of data contract languages used and in the making. In order to reach as many users as possible, we decided to make it very easy to become the data quality enforcement engine of choice for all those contract language variations.
We focused on simplicity and ease-of-adoption. New to data contracts? Just get started with this release as a standalone tool. Already using another data contract specification? You can plug-and-play Soda as we ignore any other contract section. Already using Soda Core/Library? Data contracts only adds a new capability and it interoperates nicely with existing Soda deployments.
Soda remains committed to providing open source software to the data community. We believe that the best way for the community to learn, iterate, and evolve is to get started in OSS.
How Does It Work?
Let's start by taking a look at an example Soda contract:
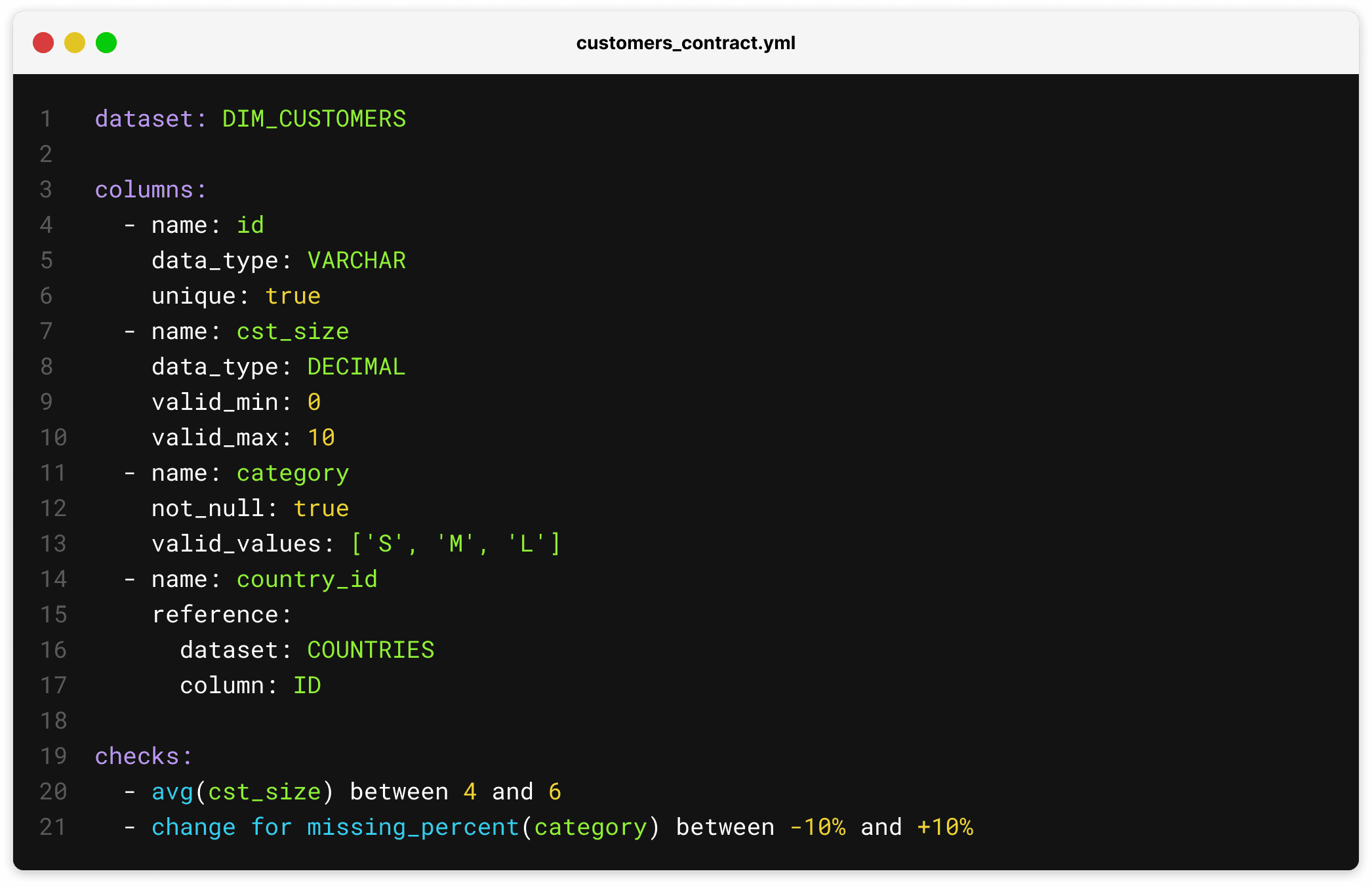
Note that the columns section is specifying the full schema. The schema of the dataset must match the specified schema exactly, which ensures that the contract is always a valid and complete representation of the dataset. Also, note how the checks section exposes the full power of SodaCL enabling users to add any data quality check.
In order to execute or "enforce" a contract, please refer to the docs on how contract files can be executed programatically.
Deployment Considerations
We recommend that the Contract YAML file is colocated in the same git repository as the software producing the new data for that dataset. This implies that after the data is produced, the contract (from the same repo version) is verified. It is easier to manage evolution this way.
For instance, in CI/CD, you can try out new versions of the contract without any versioning of the contract other than git. This reduces the need for a contract registry and all the hassle that comes with matching contract enforcement with the right contract version. It also reduces the need to have constructs for upcoming and deprecated columns.
Very similar to software APIs, backwards compatibility is really important. As a data producer, you cannot just release new versions of a dataset that are not compatible with previous versions. Adding columns is okay, but removing columns or changing the data types is very risky and will break your consumer's data products. Having a contract will force the producer to document the schema and other dataset properties. Storing this in git will create a version history of the contract. The history in git will help make these changes visible. Even tooling can be envisioned in which, upon a commit that has a change, a contract will check if the change is considered backwards compatible or not.
In this usage of contracts where pipeline code and contracts are in the same repo, publishing the contract has to be done when a new version of the software is being released. Usually in case of CI/CD, that is triggered when a branch is merged to main, and, in case of changes to contract files, ensure that the new version of the contract is pushed to all other systems that depend on it.
What's Next?
As our very first, experimental iteration of data contracts, we aim to explore how our early adopters will adopt it in the context of their own data products. We're extremely eager for feedback and, indeed, would be happy to arrange an online session so we can dig into how data contract management will work in real life. Join us on Soda Community and share your story, question, or request in the #soda-core-channel!
In the next few weeks, we will revamp the current implementation of data contracts in Soda Cloud (called Agreements) to be more focused on UI based check creation and its integration into this data contract capability.
Where to Learn More
To download and play with the release, check out the docs
Talk to us on our Soda community on Slack in the #soda-core channel
Soda Data Contracts in Action
Tom Baeyens, CTO and Co-founder of Soda, takes 6 minutes to explain what a data contract is and three key use cases. He also provides an insight into Soda's data contract strategy, and a preview of Soda Data Contracts in action.
Soda Data Contracts got even better.
Go here to learn more: The World's First Collaborative Data Contracts











