Streamline Data Quality Coverage with Soda's Innovative Check Suggestions
Streamline Data Quality Coverage with Soda's Innovative Check Suggestions
Streamline Data Quality Coverage with Soda's Innovative Check Suggestions

Bastien Boutonnet
Bastien Boutonnet
AI Team Lead & Product Management at Soda
AI Team Lead & Product Management at Soda

Baturay Ofluoglu
Baturay Ofluoglu
Machine Learning Engineer at Dataroots
Machine Learning Engineer at Dataroots
Table of Contents
In the ever-evolving world of data management, quality is the linchpin keeping everything sound. Maintaining high-quality data is imperative, whether you're developing intricate machine learning models, or crafting insightful dashboards for pivotal decision-making.
But the path to achieving this objective can seem like an intricate maze, filled with myriad metrics and elements to track and validate. How do you identify what needs to be tested? How can you make your efforts yield your expected outcome? Where should you even start?
Automate the Basics
When it comes to data quality coverage, a few simple checks can make a world of a difference. Regular updates of your data are crucial, and you may want to consider adhering to established Service Level Agreements (SLAs) for consistent updates, paying special attention to columns with human-entered input to confirm they align with a predetermined format.
Routine procedures, like checking for duplicate entries or null values in your important columns, can safeguard the integrity of your data. As obvious as it might seem, it’s not uncommon to find that even those basic quality checks are missing from key data assets. The reason? Where teams don’t have strict data entry or data quality processes in place, people simply forget to check and optimistically hope that it will all be okay. Spoiler alert: it won’t.
Establishing basic data quality coverage shouldn’t be left to chance, or your team’s maturity; it should be systematic and automatic. To this end, and drawing from our experiences working in data teams, we’ve designed the new check suggestions functionality based on what a mature data team would build in-house.
This blog was created with previous versions of Soda Core, so there might be minor code syntax differences. If you have any questions refer to https://docs.soda.io/ |
|---|
Let the Automation Guide You, Not Blind You
At Soda, we believe in the power of declarative data quality testing. That’s why we developed Soda Checks Language (SodaCL) and why we have focused heavily on data testing via explicit, user-declared rules.
But even with this powerful, intuitive language, we don’t expect you to face the world of data quality coverage alone. No, we believe the right degree of automation – call it conversational automation – can help you and your team follow best practices to get from zero to “whew” in just a few minutes. What is the single Soda Library command that does this for you? soda suggest
This powerful feature takes the guesswork out of establishing basic data quality checks. It paves the way for you to easily kickstart the data quality process by profiling your data, then recommending relevant checks. Rather than starting from scratch by asking yourself, “What checks do I need, here?” you can run soda suggest and answer Soda’s yes/no, or multiple-choice questions in the command-line to produce a solid, production-ready file full of checks, ready to run a scan.
Without exaggeration, five minutes is all it takes. Surely, it’s worth it to validate that your dataset contains, complete, valid, fresh, anomaly-free data!
Select Your Suggestions
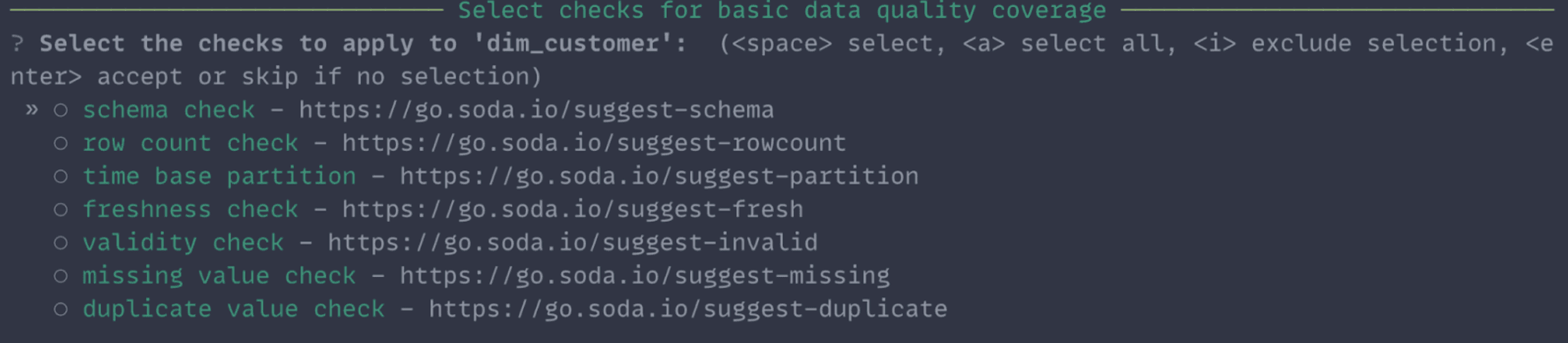
We know that you may not always want suggestions for all check types, so we’ve got you covered. One of the first questions in the check suggestion flow asks you to select the checks for which you’d like suggestions. You can select one or two if that’s all you need. In the screenshot below, we select everything because, honestly, the whole process is quite fast. And why wouldn’t you want more coverage?
Smart Suggestions for Freshness
To prepare a freshness check which validates that your data is timely and not out-of-date, Soda check suggestions first identifies the date/time columns that it can use to gauge freshness, then ranks them according to which are the best to use. For example, in the dim_customer table, Soda correctly detects that date_first_purchase is a more suitable column to test for data freshness than date_of_birth. If this table had a created_at or updated_at column, for example, the algorithm would have selected those as the most suitable columns to gauge freshness.

Further, as you can see on the screenshot above, the freshness suggestion determines a relevant threshold based on the patterns it observes in your dataset. In this case, it determined that the dates in date_first_purchase shouldn't be higher than 19 hours.
Helpful Validity Check Suggestion
Another very helpful check suggestion is for format validity. We all know that string columns can end up being a bit of a catch-all; people store all sorts of data in varchar columns. A format validity check allows you to assert that columns, especially those populated by user input, follow an expected, valid format such as date or currency.
However, because SodaCL supports 40+ validity formats, it can be really time consuming to go through each of your dataset’s string columns to figure out which pattern or format each column should match.
Check suggestions eliminates the guesswork by profiling the columns containing strings and suggesting the most suitable valid format. In the example below, the check suggestion algorithm correctly detects that the “email_address” column should be formatted as an email semantic type. Bravo!
Check suggestions eliminates the guesswork by profiling the columns containing strings and suggesting the most suitable valid format. In the example below, the check suggestion algorithm correctly detects that the “email_address” column should be formatted as an email semantic type. Bravo!

Production-ready file of checks
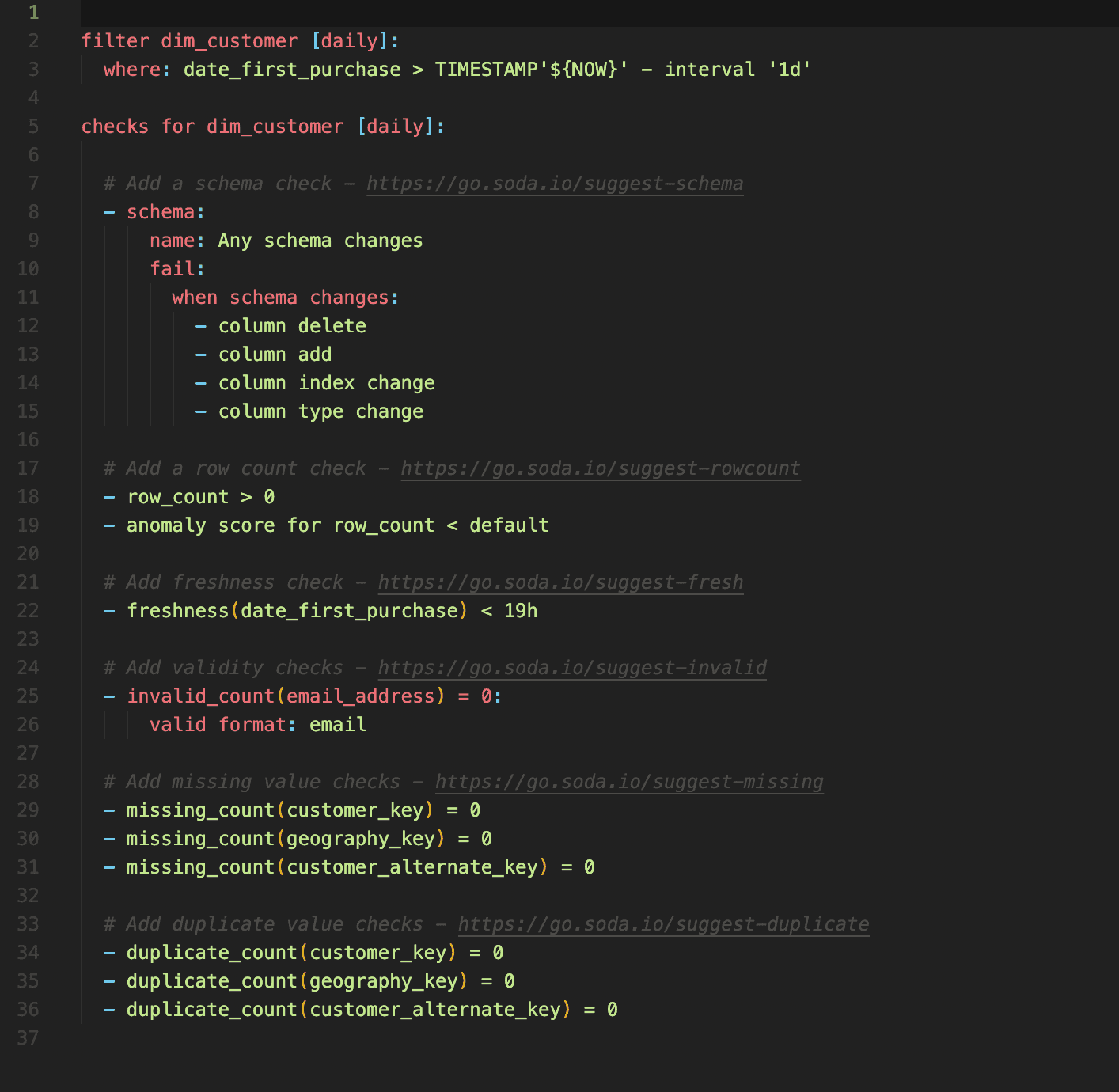
Once you've completed the check suggestion flow, Soda prepares a production-ready checks YAML file, complete with a prompt that asks you if you want to use it to run a scan right away. (Yes, you do!)
In addition to showing you a pretty summary of the checks it suggests, and storing the file locally on your system, you can take this file and put it anywhere you need it. Add these checks to your data pipeline in production to catch data issues before they have a downstream impact. Or, add them to your CICD pipeline to find post-transformation data quality issues before merging into production.
The beauty of this functionality lies in its flexibility; you can plug the checks as-is into your Airflow DAG, or easily modify or expand them according to your needs. You can customize your checks, adjust the thresholds, incorporate filters, and so on.
But Wait, There’s More!
You’ve seen some of our favorite highlights, but check suggestions does quite a bit more. It guides you through the steps to prepare checks for:
schema changes
row counts, and anomaly detection on row counts
missing values, which automatically look for null values
duplicate values
Check out the whole exhaustive list of everything check suggestions does in Soda documentation.
The Magic. Watch it Happen.
Take a look at Soda Library Check Suggestions to watch some of the key elements of the end-to-end check suggestion flow.
What’s Next?
Ensuring robust data quality shouldn’t be a daunting task. In launching check suggestions, Soda has transformed this stultifying task into a simple, guided experience. This powerful feature, paired with our enhanced Soda Library, offers a new level of automation that helps your team systematically and intuitively establish basic data quality coverage.
Our journey doesn’t end here. We have ambitious plans for extending the capabilities of check suggestions to include a greater number of checks and smarter, threshold-based checks to make them more precise and adaptable.
Moreover, our vision includes a plan to include business-oriented users who generally don’t regularly use command-line tools. We're in the process of designing a way to present check suggestions in Soda Cloud in a way that is even more user-friendly.
We enthusiastically encourage you to try check suggestions the next time you need to add data quality coverage to a dataset. If you are new to Soda, take advantage of the 45-day free trial to experience the benefits of automated, intelligent data quality checks. Do yourself a favor and take just a few minutes of your day to eliminate the most basic of data quality headaches by implementing the most basic of data quality checks.
As always, we look forward to your feedback and suggestions; join us in the Soda Community on Slack and let us know what you think! We’re eager to evolve our products, even as our objective to simplify and systemize data quality checks remains unchanged.
Dive into the world of automated data quality checks with Soda to stop bad data disrupting good business.
In the ever-evolving world of data management, quality is the linchpin keeping everything sound. Maintaining high-quality data is imperative, whether you're developing intricate machine learning models, or crafting insightful dashboards for pivotal decision-making.
But the path to achieving this objective can seem like an intricate maze, filled with myriad metrics and elements to track and validate. How do you identify what needs to be tested? How can you make your efforts yield your expected outcome? Where should you even start?
Automate the Basics
When it comes to data quality coverage, a few simple checks can make a world of a difference. Regular updates of your data are crucial, and you may want to consider adhering to established Service Level Agreements (SLAs) for consistent updates, paying special attention to columns with human-entered input to confirm they align with a predetermined format.
Routine procedures, like checking for duplicate entries or null values in your important columns, can safeguard the integrity of your data. As obvious as it might seem, it’s not uncommon to find that even those basic quality checks are missing from key data assets. The reason? Where teams don’t have strict data entry or data quality processes in place, people simply forget to check and optimistically hope that it will all be okay. Spoiler alert: it won’t.
Establishing basic data quality coverage shouldn’t be left to chance, or your team’s maturity; it should be systematic and automatic. To this end, and drawing from our experiences working in data teams, we’ve designed the new check suggestions functionality based on what a mature data team would build in-house.
This blog was created with previous versions of Soda Core, so there might be minor code syntax differences. If you have any questions refer to https://docs.soda.io/ |
|---|
Let the Automation Guide You, Not Blind You
At Soda, we believe in the power of declarative data quality testing. That’s why we developed Soda Checks Language (SodaCL) and why we have focused heavily on data testing via explicit, user-declared rules.
But even with this powerful, intuitive language, we don’t expect you to face the world of data quality coverage alone. No, we believe the right degree of automation – call it conversational automation – can help you and your team follow best practices to get from zero to “whew” in just a few minutes. What is the single Soda Library command that does this for you? soda suggest
This powerful feature takes the guesswork out of establishing basic data quality checks. It paves the way for you to easily kickstart the data quality process by profiling your data, then recommending relevant checks. Rather than starting from scratch by asking yourself, “What checks do I need, here?” you can run soda suggest and answer Soda’s yes/no, or multiple-choice questions in the command-line to produce a solid, production-ready file full of checks, ready to run a scan.
Without exaggeration, five minutes is all it takes. Surely, it’s worth it to validate that your dataset contains, complete, valid, fresh, anomaly-free data!
Select Your Suggestions
We know that you may not always want suggestions for all check types, so we’ve got you covered. One of the first questions in the check suggestion flow asks you to select the checks for which you’d like suggestions. You can select one or two if that’s all you need. In the screenshot below, we select everything because, honestly, the whole process is quite fast. And why wouldn’t you want more coverage?
Smart Suggestions for Freshness
To prepare a freshness check which validates that your data is timely and not out-of-date, Soda check suggestions first identifies the date/time columns that it can use to gauge freshness, then ranks them according to which are the best to use. For example, in the dim_customer table, Soda correctly detects that date_first_purchase is a more suitable column to test for data freshness than date_of_birth. If this table had a created_at or updated_at column, for example, the algorithm would have selected those as the most suitable columns to gauge freshness.
Further, as you can see on the screenshot above, the freshness suggestion determines a relevant threshold based on the patterns it observes in your dataset. In this case, it determined that the dates in date_first_purchase shouldn't be higher than 19 hours.
Helpful Validity Check Suggestion
Another very helpful check suggestion is for format validity. We all know that string columns can end up being a bit of a catch-all; people store all sorts of data in varchar columns. A format validity check allows you to assert that columns, especially those populated by user input, follow an expected, valid format such as date or currency.
However, because SodaCL supports 40+ validity formats, it can be really time consuming to go through each of your dataset’s string columns to figure out which pattern or format each column should match.
Check suggestions eliminates the guesswork by profiling the columns containing strings and suggesting the most suitable valid format. In the example below, the check suggestion algorithm correctly detects that the “email_address” column should be formatted as an email semantic type. Bravo!
Check suggestions eliminates the guesswork by profiling the columns containing strings and suggesting the most suitable valid format. In the example below, the check suggestion algorithm correctly detects that the “email_address” column should be formatted as an email semantic type. Bravo!
Production-ready file of checks
Once you've completed the check suggestion flow, Soda prepares a production-ready checks YAML file, complete with a prompt that asks you if you want to use it to run a scan right away. (Yes, you do!)
In addition to showing you a pretty summary of the checks it suggests, and storing the file locally on your system, you can take this file and put it anywhere you need it. Add these checks to your data pipeline in production to catch data issues before they have a downstream impact. Or, add them to your CICD pipeline to find post-transformation data quality issues before merging into production.
The beauty of this functionality lies in its flexibility; you can plug the checks as-is into your Airflow DAG, or easily modify or expand them according to your needs. You can customize your checks, adjust the thresholds, incorporate filters, and so on.
But Wait, There’s More!
You’ve seen some of our favorite highlights, but check suggestions does quite a bit more. It guides you through the steps to prepare checks for:
schema changes
row counts, and anomaly detection on row counts
missing values, which automatically look for null values
duplicate values
Check out the whole exhaustive list of everything check suggestions does in Soda documentation.
The Magic. Watch it Happen.
Take a look at Soda Library Check Suggestions to watch some of the key elements of the end-to-end check suggestion flow.
What’s Next?
Ensuring robust data quality shouldn’t be a daunting task. In launching check suggestions, Soda has transformed this stultifying task into a simple, guided experience. This powerful feature, paired with our enhanced Soda Library, offers a new level of automation that helps your team systematically and intuitively establish basic data quality coverage.
Our journey doesn’t end here. We have ambitious plans for extending the capabilities of check suggestions to include a greater number of checks and smarter, threshold-based checks to make them more precise and adaptable.
Moreover, our vision includes a plan to include business-oriented users who generally don’t regularly use command-line tools. We're in the process of designing a way to present check suggestions in Soda Cloud in a way that is even more user-friendly.
We enthusiastically encourage you to try check suggestions the next time you need to add data quality coverage to a dataset. If you are new to Soda, take advantage of the 45-day free trial to experience the benefits of automated, intelligent data quality checks. Do yourself a favor and take just a few minutes of your day to eliminate the most basic of data quality headaches by implementing the most basic of data quality checks.
As always, we look forward to your feedback and suggestions; join us in the Soda Community on Slack and let us know what you think! We’re eager to evolve our products, even as our objective to simplify and systemize data quality checks remains unchanged.
Dive into the world of automated data quality checks with Soda to stop bad data disrupting good business.
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by








Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions