
We’re really pleased to announce the latest feature of the Soda Cloud platform: Soda Incidents, a workflow to streamline your data operations.
Data products are transforming the way every business operates. Built using ever-increasing volumes of data from different sources, they are accelerating the shift towards digital automation. Once in production, data products need grooming and maintenance to address inevitable changes to data schemas and structures, broken transformation logic, and concept drift, all of which impact reliability, quality, and ultimately trust in data.
As they work to maintain the quality of data products, data and analytics engineers often find themselves firefighting data issues when reports or machine learning models break. When an alarm bell rings, it’s a mad scramble to find out what has broken and what has been impacted.
When “data downtime” strikes, we empathize with data engineering teams fighting the fire and their downstream data consumers who are desperate for resolution. Not only is data downtime frustrating, it’s a waste of everyone’s time and money to constantly cycle through a break-fix loop instead of focusing on work that adds value to the business.
From Data Downtime to Data Availability
Have you ever wondered about the full cost and impact of data downtime? When we’ve asked this question of our community, we hear about costs such as disruption to the business, loss of revenue, productivity loss, and increased skepticism in the trust of data. Depending on the type of organization, data downtime can even impact regulatory or compliance mandates, customer retention, and employee satisfaction.
For every organization that relies on data to drive revenue through confident decision-making, that nurtures happy customers and employees, every minute of “data uptime” – when good-quality data is accurate and available – matters.
Soda was built to address data availability, to help data teams discover, prioritize, and resolve data quality issues. We’ve been eager to simplify this cumbersome process with a comprehensive end-to-end workflow to detect and resolve issues, and automatically alert the right people at the right time. Thus, we introduce Soda Incidents.
This blog was created with previous versions of Soda Cloud, so there might be minor UI path differences. If you have any questions, refer to https://docs.soda.io/ |
|---|
Welcome, Soda Incidents
Soda Incidents enables data teams to effectively manage data reliability and quality incidents, whether those are in a dataset or at the record level. It alleviates the fear of not knowing, and the pain of finding out too late that a data quality issue has had a downstream impact.
Soda Incidents simplifies the process to detect, triage, diagnose, and resolve data issues across the entire data product lifecycle. Our data reliability and observability tools are built by data engineers and product owners, all of whom have first-hand experience with building reliable systems that produce high-quality data.
In collaboration with Soda Cloud early adopters and in reviewing industry best practices, our team identified three key pillars of good incident management: defined roles and responsibilities, coordination between team mates; and clear communication.
Further, good incident management must be efficient and operate at scale: when a data quality issue occurs, everyone must be able to efficiently respond under pressure. Another key component to the process is to carry out a retrospective or post-mortem to discover what went wrong, understand why it went wrong, and the lessons learned to avoid the incident from happening again in the future.
The Complete Data Quality Workflow
We built an operations workflow for incident management that incorporates best practices from incident management in the infrastructure and application layer and enables organizations to configure Soda to meet their specific business requirements.
It all begins when you create a monitor in Soda Cloud and add an alert to notify you when a data quality test fails. When your team receives an alert via Slack or email, you can log in to review the failed test and click to open a new Incident. The built-in workflow enables you to assign a Lead Investigator and Status to the Incident to track your team’s progress in investigating, and resolving the data quality issue.
Watch the 1-minute walkthrough.
Assign and Conquer
Good incident management and resolution depends on everyone understanding their role. By making sure everyone’s role is clear, you can manage who is doing what and in turn, get more done. During the scramble of data downtime, knowing who is responsible for what determines how quickly you can get back to business as usual.
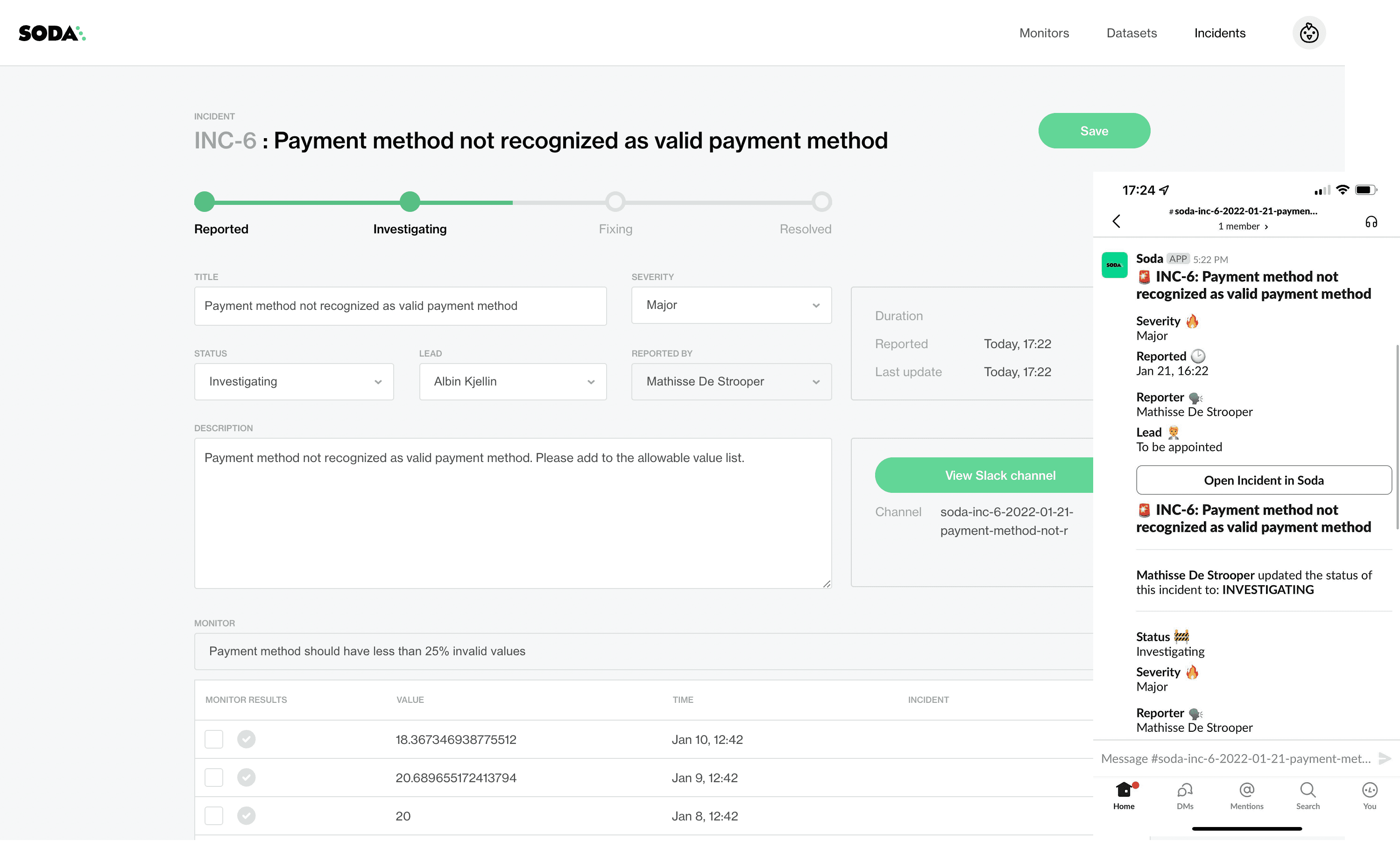
For each Incident, a Lead Investigator takes ownership of the Incident and ensures that the team takes action to diagnose, analyze, and resolve the issue. Notably, the Reporter of an Incident is not assigned as the Lead Investigator by default. We did this on purpose to empower any team member to spin up an Incident without having to own the investigation.
At Soda we’re really good at building tools that help data teams create trusted data products; we are not in the business of building issue trackers. We know that tools like Jira and OpsGenie are widely used and exhaustively address end-to-end issue tracking. It would have been absurd to go to the extreme of building yet another issue tracker so instead, we built Soda Incidents to integrate with existing tools.
In the coming months, we’ll be releasing more integrations with popular issue trackers - let us know if you have a favorite!
Teamwork Makes the Data Work
Data quality is a team sport: if everyone monitors data quality, Incidents need to be accessible by everyone in your organization. It needs to be simple for people to get involved and bring everyone closer to data they know they can trust.
With this in mind, we purposefully selected Slack as the first tool to integrate with Soda Incidents. Soda Cloud already integrates with Slack to send notifications, and we know it is a tool-of-choice for many organizations’ internal communication and collaboration.
Our research shows that data teams are already using Slack to work through technical issues so extending Slack to investigate data quality issues felt right. From within an Incident, click to open a new Slack channel so your team can immediately begin collaborating to resolve a specific data quality issue. Working in Slack, it’s easy for team members to ask questions, trigger ideas, and surface intrinsic technical information that only one person knows.

Measuring Time To Respond & Resolve (MTTR)
As your team works their way through the investigation, you can update the Status of an Incident, change the Lead Investigator, and add or remove monitor results that are related to the Incident. Soda Cloud pushes each change to the Incident’s Slack channel. This is how everyone stays on the same page and stakeholders stay informed on progress.
And when the fire is out, when the team is able to breathe easy and close the Incident, Soda Cloud automatically archives the channel in Slack. There it stays, awaiting the day when a similar issue arises and a team can access the details that will help them fix an issue even faster.
What starts with a data failure at source, ends with a community of specialists, such as analytics engineers, data stewards, and data managers, who work together to keep the data in pristine condition.
After incorporating Soda Incidents into your team’s data quality practices, consider leveraging Soda’s Reporting API to build dashboards using Key Performance Indicators that help you understand Soda’s impact on data quality in your organization. Use the API to:
assess data quality test coverage in your organization
gauge the overall “Data quality health” of datasets
find out how often your team uses Soda Cloud to check on data quality
(Almost) Every Data Issue Has A Silver Lining
With every investigation and every issue resolved, there are lessons to be learned for next time. When you set the Status of an Incident to Resolved, Soda Cloud prompts you to record Resolution Notes, encouraging you to review your incident data and capture any associated intrinsic knowledge that helped resolve the issue.
This input can help you identify trends and anomalies, or any common causality for your data incidents, leading to insights that enable you to improve your systems and operations even more.
Watch the 30-second demo.
What’s Next?
We are excited by the possibilities that Soda Incidents offers our users, helping them manage data quality incidents with a true end-to-end workflow, from detection right through to resolution. We’re working adding the capability to update the Status of an Incident in Slack.
Soon, we’ll be announcing our newest integration that enables you to leverage all the data tests you created in dbt. Soda Cloud can ingest all those dbt test results and display them alongside the data quality monitors you created in Soda Cloud. Run your dbt pipeline, schedule Soda SQL to run soda ingest, and instantly see all your test results in one place. Bet you can’t wait to see the time-series charts from your dbt test results in Soda Cloud!
Give Soda Incidents a try! Existing Soda Cloud users can get started straight away and we’d love to hear your feedback: join the conversation in our Slack Community (no surprise there).
Incidentally - pun intended - that’s where you’ll find up-to-date info on the availability of our exciting new features and the completely-evolved, coming-soon, new version of Soda SQL. 🤫🎉
Haven’t signed up to use Soda Cloud yet? What are you waiting for – it’s free! Sign up today.











