Modern Data Quality Testing for Spark Pipelines
Modern Data Quality Testing for Spark Pipelines

Vijay Kiran
Vijay Kiran
Former Lead Data Engineer at Soda
Former Lead Data Engineer at Soda
Table of Contents
⛔️ This feature has been deprecated.
Soda Spark was an extension of Soda SQL that allowed you to run Soda SQL functionality programmatically on a Spark DataFrame. It has been replaced by Soda Library configured to connect Soda to Apache Spark.
As part of the mission to bring everyone closer to their data, Soda has introduced Soda Spark, a modern data testing, monitoring, and reliability tool for engineering teams that use PySpark DataFrames. The latest open source-tool in Soda’s Data Reliability Toolset, Soda Spark was built for data and analytics engineers working in data-intensive environments, where reliable, high-quality data is of paramount importance.
Soda Spark alleviates the pain of maintaining a high level of trust in data in the Spark ecosystem, where engineers typically spend a lot of time building frameworks for data quality checks. Data and analytics engineers can control the tests that screen for bad data – or as we like to call them, silent data issues– and the metrics that evaluate the results. By using the Spark Dialect already available in Soda SQL, the Soda Spark library provides an API to extract data metrics and column profiles according to the queries you write in YAML configuration files.
Data engineers use Soda Spark to write declarative data quality tests to Spark DataFrames and detect problematic data. When you connect Soda Spark to a Soda Cloud account, you can configure alerts that notify your team when your Soda Spark tests fail. Teams get the right information right away to begin triaging, investigating, and quickly resolving issues.
Tutorial: Data Quality Testing for Spark Pipelines
Soda’s Open Source Data Reliability Tools can operate across multiple data workloads, engines, and environments, including Kafka, Spark, AWS S3, Azure Blob Storage, Google Cloud Datastore, Presto, Snowflake, Azure Synapse, Google BigQuery, and Amazon Redshift.
Using Soda Spark is simple: install it via pip and start using the API directly in your PySpark programs. Here’s a small video on how to install, use, and test your Spark DataFrames using Soda Spark.

Alternatively, if you are using a popular Spark execution environment like Databricks, you can also easily use Soda Spark in your Notebooks, and embed the testing directly into your pipelines or schedule testing.
Follow this five-step tutorial to see how you can run tests for data quality of Apache Spark DataFrames running on a Databricks cluster. If you do not already have a Databricks cluster up and running, you can create one from the Databricks Community.
1. To install Soda Spark in your Databricks Cluster, run the following command directly from your notebook:
%pip install soda-spark
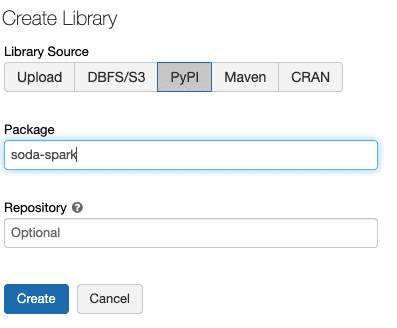
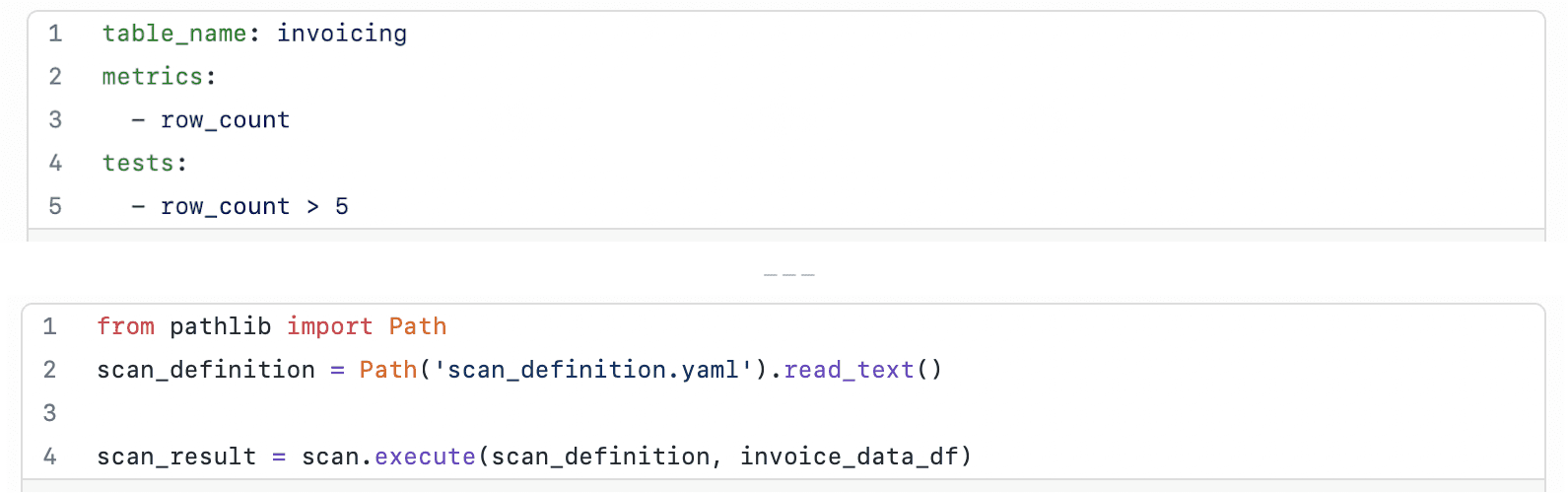
2. Load the data into a DataFrame, then create a scan definition with tests for the DataFrame

3. Run a Soda scan to execute the tests you defined in the scan definition (scan YAML configuration file)
You can define tests in one of two places: 1) in your code as a string or 2) in an external YAML file.
In this tutorial we define tests in an external YAML configuration file and use that file to test a DataFrame’s data quality.
When the Soda scan is complete, you can review the test results and measurements in the command-line (see image below, top), and the output in the Databricks Notebook (see image below, bottom).

4. Check the test results for tests that failed during the scan. In the output example below, no tests failed

This output displays the metrics against which Soda tested your data, the resulting measurements, and each test’s pass or fail status.
5. And now, you can:
configure Soda SQL to send the metrics and test results to Soda Cloud.
join our Soda Slack Community to ask questions and make feature requests.
become a contributor: we are always looking to improve our library. All contributions are welcome!
Our biggest thanks to Cor Zuurmond (GoDataDriven), the first contributor who helped us develop Soda Spark, and Abhishek Khare (HelloFresh) and Anil Kulkarni (Lululemon), for their early testing and valuable feedback! Check out the Soda Spark repo here.
Why Soda Adds the Spark to Your Pipelines
Soda is the data reliability company that provides Open Source (OSS) and Software as a Service (SaaS) tools that enable data teams to discover, prioritize, and resolve data issues. Our OSS Data Reliability Tools and SaaS cloud platform bring everyone closer to their data, resulting in data products and analytics that everyone can trust. The Soda global data community already counts Disney, HelloFresh, and Udemy as major contributors to have deployed Soda’s data reliability tools.
Here are 8 good reasons we think that your team should use Soda to test data quality across your entire data product lifecycle.
1. Out-of-the-Box
Out of the box, Soda supports multiple data sources, provides anomaly detection, visualizations of historical test results, and automated incident management. It is easy to get started and simple to define your tests and expectations.
2. Installation
Easily install Soda Spark via pip, then use the command-line to connect to a data source, discover datasets, and run a scan within a few minutes. You can follow documented examples to set up programmatic scans from the command-line and integrate with data pipeline tools. Soda’s documentation is easy-to-follow and highly rated by the community and stargazers. Using SQL as its Domain Specific Language, there is no need for Admin help and no requirement for familiarity with writing high-level programming languages.
3. Library of Tests
Soda docs provide several examples for using built-in metrics, which are easy to maintain and simplify the complexity of writing data quality tests.
4. Sharing and Collaboration
Use Soda Cloud to invite team members, send notifications to Slack, share data test results, and create and track data quality Incidents. Team members can review scan results and create new monitors in Soda Cloud. Soda Cloud is more inclusive of a non-coder user base so it makes collaboration easier across an organization.
5. Get Started with Good Documentation
Soda has invested in writing and publishing comprehensive, concise, up-to-date documentation for both the Open Source Data Reliability Tools and cloud platform. Soda’s documentation enables data engineers to immediately discover and monitor data issues through a series of fully configurable tests.
6. Cloud Metrics Store
You can define historic metrics so that you can write tests in scan YAML files that test data relative to the historic measurements contained in the Soda Cloud Metric Store. Essentially, this type of metric allows you to access the historic measurements in the Soda Cloud Metric Store and write tests that use those historic measurements.
7. Automated Monitoring
Soda Cloud offers time-series anomaly detection and schema evolution monitoring. In fact, when you onboard a dataset, Soda Cloud automatically creates both an anomaly detection monitor for row count to start learning patterns about your data right away, and a schema evolution monitor to start tracking changes to columns in your dataset.
8. Visualization of Data Monitoring
In Soda Cloud, the full history of metrics and tests can be published and visualized on a Soda Cloud account.
Ready?
Get started with Soda Spark here.
You can get started straight away and be testing your dataframes in just a few steps. Get Soda Spark here.
We’d love to hear how Soda Spark works for you. Join our Soda Community on Slack and let us know what you think.
Check out Cor and Anil’s Soda Spark write-ups to learn even more:
Soda - get ahead of silent data issues, Cor Zuurmond
⛔️ This feature has been deprecated.
Soda Spark was an extension of Soda SQL that allowed you to run Soda SQL functionality programmatically on a Spark DataFrame. It has been replaced by Soda Library configured to connect Soda to Apache Spark.
As part of the mission to bring everyone closer to their data, Soda has introduced Soda Spark, a modern data testing, monitoring, and reliability tool for engineering teams that use PySpark DataFrames. The latest open source-tool in Soda’s Data Reliability Toolset, Soda Spark was built for data and analytics engineers working in data-intensive environments, where reliable, high-quality data is of paramount importance.
Soda Spark alleviates the pain of maintaining a high level of trust in data in the Spark ecosystem, where engineers typically spend a lot of time building frameworks for data quality checks. Data and analytics engineers can control the tests that screen for bad data – or as we like to call them, silent data issues– and the metrics that evaluate the results. By using the Spark Dialect already available in Soda SQL, the Soda Spark library provides an API to extract data metrics and column profiles according to the queries you write in YAML configuration files.
Data engineers use Soda Spark to write declarative data quality tests to Spark DataFrames and detect problematic data. When you connect Soda Spark to a Soda Cloud account, you can configure alerts that notify your team when your Soda Spark tests fail. Teams get the right information right away to begin triaging, investigating, and quickly resolving issues.
Tutorial: Data Quality Testing for Spark Pipelines
Soda’s Open Source Data Reliability Tools can operate across multiple data workloads, engines, and environments, including Kafka, Spark, AWS S3, Azure Blob Storage, Google Cloud Datastore, Presto, Snowflake, Azure Synapse, Google BigQuery, and Amazon Redshift.
Using Soda Spark is simple: install it via pip and start using the API directly in your PySpark programs. Here’s a small video on how to install, use, and test your Spark DataFrames using Soda Spark.
Alternatively, if you are using a popular Spark execution environment like Databricks, you can also easily use Soda Spark in your Notebooks, and embed the testing directly into your pipelines or schedule testing.
Follow this five-step tutorial to see how you can run tests for data quality of Apache Spark DataFrames running on a Databricks cluster. If you do not already have a Databricks cluster up and running, you can create one from the Databricks Community.
1. To install Soda Spark in your Databricks Cluster, run the following command directly from your notebook:
%pip install soda-spark
2. Load the data into a DataFrame, then create a scan definition with tests for the DataFrame
3. Run a Soda scan to execute the tests you defined in the scan definition (scan YAML configuration file)
You can define tests in one of two places: 1) in your code as a string or 2) in an external YAML file.
In this tutorial we define tests in an external YAML configuration file and use that file to test a DataFrame’s data quality.
When the Soda scan is complete, you can review the test results and measurements in the command-line (see image below, top), and the output in the Databricks Notebook (see image below, bottom).
4. Check the test results for tests that failed during the scan. In the output example below, no tests failed
This output displays the metrics against which Soda tested your data, the resulting measurements, and each test’s pass or fail status.
5. And now, you can:
configure Soda SQL to send the metrics and test results to Soda Cloud.
join our Soda Slack Community to ask questions and make feature requests.
become a contributor: we are always looking to improve our library. All contributions are welcome!
Our biggest thanks to Cor Zuurmond (GoDataDriven), the first contributor who helped us develop Soda Spark, and Abhishek Khare (HelloFresh) and Anil Kulkarni (Lululemon), for their early testing and valuable feedback! Check out the Soda Spark repo here.
Why Soda Adds the Spark to Your Pipelines
Soda is the data reliability company that provides Open Source (OSS) and Software as a Service (SaaS) tools that enable data teams to discover, prioritize, and resolve data issues. Our OSS Data Reliability Tools and SaaS cloud platform bring everyone closer to their data, resulting in data products and analytics that everyone can trust. The Soda global data community already counts Disney, HelloFresh, and Udemy as major contributors to have deployed Soda’s data reliability tools.
Here are 8 good reasons we think that your team should use Soda to test data quality across your entire data product lifecycle.
1. Out-of-the-Box
Out of the box, Soda supports multiple data sources, provides anomaly detection, visualizations of historical test results, and automated incident management. It is easy to get started and simple to define your tests and expectations.
2. Installation
Easily install Soda Spark via pip, then use the command-line to connect to a data source, discover datasets, and run a scan within a few minutes. You can follow documented examples to set up programmatic scans from the command-line and integrate with data pipeline tools. Soda’s documentation is easy-to-follow and highly rated by the community and stargazers. Using SQL as its Domain Specific Language, there is no need for Admin help and no requirement for familiarity with writing high-level programming languages.
3. Library of Tests
Soda docs provide several examples for using built-in metrics, which are easy to maintain and simplify the complexity of writing data quality tests.
4. Sharing and Collaboration
Use Soda Cloud to invite team members, send notifications to Slack, share data test results, and create and track data quality Incidents. Team members can review scan results and create new monitors in Soda Cloud. Soda Cloud is more inclusive of a non-coder user base so it makes collaboration easier across an organization.
5. Get Started with Good Documentation
Soda has invested in writing and publishing comprehensive, concise, up-to-date documentation for both the Open Source Data Reliability Tools and cloud platform. Soda’s documentation enables data engineers to immediately discover and monitor data issues through a series of fully configurable tests.
6. Cloud Metrics Store
You can define historic metrics so that you can write tests in scan YAML files that test data relative to the historic measurements contained in the Soda Cloud Metric Store. Essentially, this type of metric allows you to access the historic measurements in the Soda Cloud Metric Store and write tests that use those historic measurements.
7. Automated Monitoring
Soda Cloud offers time-series anomaly detection and schema evolution monitoring. In fact, when you onboard a dataset, Soda Cloud automatically creates both an anomaly detection monitor for row count to start learning patterns about your data right away, and a schema evolution monitor to start tracking changes to columns in your dataset.
8. Visualization of Data Monitoring
In Soda Cloud, the full history of metrics and tests can be published and visualized on a Soda Cloud account.
Ready?
Get started with Soda Spark here.
You can get started straight away and be testing your dataframes in just a few steps. Get Soda Spark here.
We’d love to hear how Soda Spark works for you. Join our Soda Community on Slack and let us know what you think.
Check out Cor and Anil’s Soda Spark write-ups to learn even more:
Soda - get ahead of silent data issues, Cor Zuurmond
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.

Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.

Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.

Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.

Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by







Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions
Trusted by the world’s leading enterprises
Real stories from companies using Soda to keep their data reliable, accurate, and ready for action.
At the end of the day, we don’t want to be in there managing the checks, updating the checks, adding the checks. We just want to go and observe what’s happening, and that’s what Soda is enabling right now.
Sid Srivastava
Director of Data Governance, Quality and MLOps
Investing in data quality is key for cross-functional teams to make accurate, complete decisions with fewer risks and greater returns, using initiatives such as product thinking, data governance, and self-service platforms.
Mario Konschake
Director of Product-Data Platform
Soda has integrated seamlessly into our technology stack and given us the confidence to find, analyze, implement, and resolve data issues through a simple self-serve capability.
Sutaraj Dutta
Data Engineering Manager
Our goal was to deliver high-quality datasets in near real-time, ensuring dashboards reflect live data as it flows in. But beyond solving technical challenges, we wanted to spark a cultural shift - empowering the entire organization to make decisions grounded in accurate, timely data.
Gu Xie
Head of Data Engineering
4.4 of 5
Your data has problems.
Now they fix themselves.
Automated data quality, remediation, and management.
One platform, agents that do the work, you approve.
Trusted by
Solutions