
%20(1).png)
%20(1).png)

TL;DR
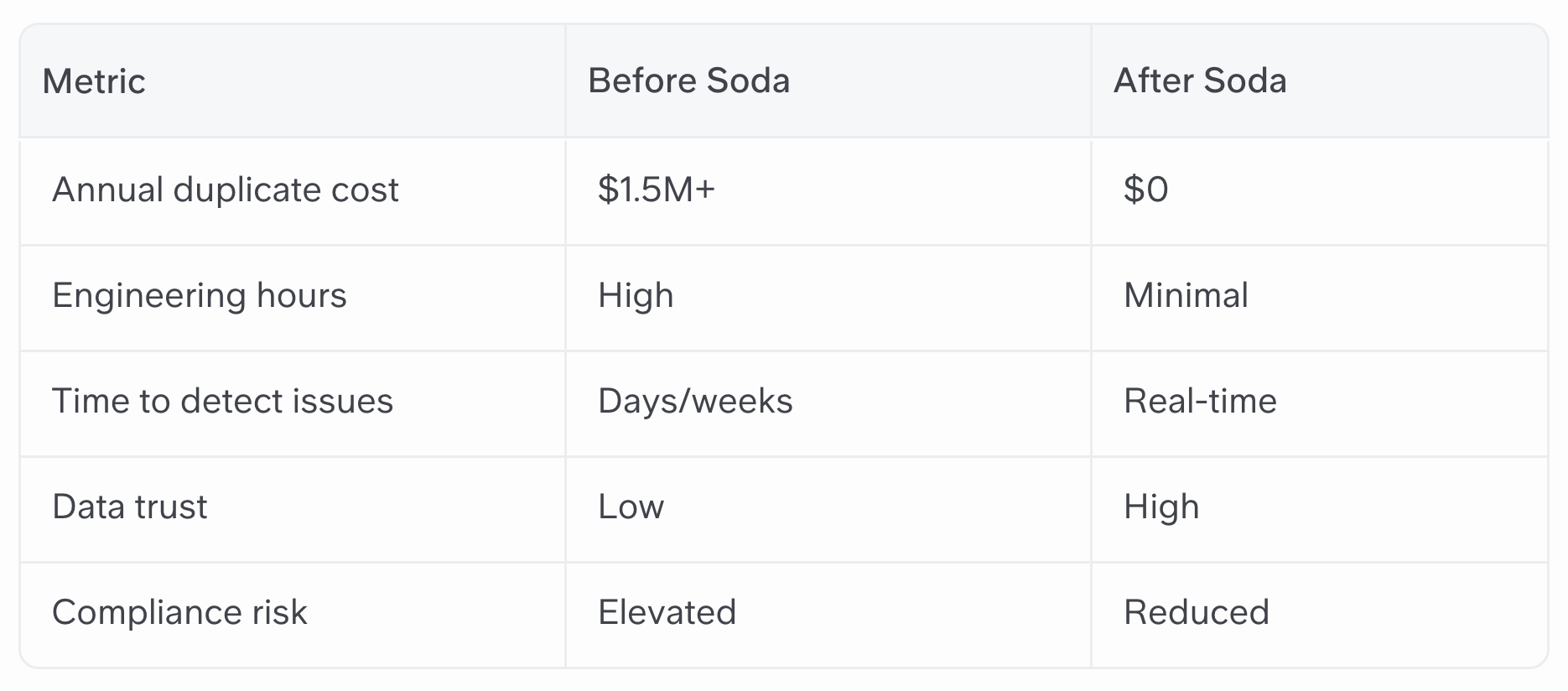
A global financial services firm was unknowingly spending over $1.5 million per year due to silent data duplication in its pipelines. They were able to detect and eliminate over 1,000 duplicate tables using Soda's low-code data quality platform, saving money on compute and storage, reducing engineering effort, and restoring trust in analytics. The implementation took less than a day. And the final result? Real-time monitoring, proactive prevention, and long-term ROI.
The Hidden Cost of Duplicated Data
Whether you’re a data engineer, analytics lead, or business stakeholder, duplicate records in your data pipelines can be a significant, yet often overlooked, source of wasted budget.
Because they don’t crash your dashboards or disrupt your processes, these duplicate entries tend to go unnoticed. In large-scale environments, this "invisible waste" accumulates quickly, especially when you're paying for every gigabyte of data and CPU second in the cloud.
Beyond monetary loss, duplicated data undermines the reliability of dashboards and reports. Business users may unknowingly base decisions on inflated metrics, while data teams are forced to spend valuable time troubleshooting anomalies that could have been prevented.
This cycle not only reduces productivity but also jeopardizes regulatory compliance and audit readiness.
The challenge is clear: without proactive monitoring and prevention, duplicated records can quietly erode both the financial health and the data culture of an organization.
In this article, we'll share a real customer story from a global firm. We will explain how Soda’s low-code approach identified rampant duplication before it could affect the modeling layer, and we will quantify the substantial return on investment (ROI)—spoiler alert: it is measured in seven figures.
We'll keep the technical bits minimal, focus on the business value, and demonstrate how automated data quality monitoring can transform hidden costs into clear savings.
Customer Story: When Copies Become Costly
Meet the customer
This global firm manages trillions of dollars in assets and operates in a highly regulated industry where data quality is critical to business success. Their data engineering team runs thousands of models and pipelines every day, processing massive amounts of transactional data that feeds into dashboards, reports, and compliance processes.
With such a large scale, even minor inefficiencies compound quickly—which is precisely what was happening, unnoticed.
Recently, they have implemented Soda for data testing and monitoring throughout their ecosystem.
Soda has been effective in identifying common issues such as null values, schema drifts, and row spikes. However, there was no ready-made check to flag what turned out to be one of their most costly blind spots: large-scale duplication.
The Challenge: The Scale and Impact of Duplicates
At first glance, nothing seemed wrong. Pipelines were operational. Dashboards looked accurate and models performed as expected. But something still felt off to the team.
The breakthrough came not from a standard alert, but from analytical work. Using Soda to monitor schema drift and row spikes, the team identified a concerning trend: hundreds of tables shared identical row counts and contained the same information, down to the record.
What they found was astonishing: there were over 1,000 duplicate tables — not even in active use — each costing around $4/day to store and process. Multiply that by 365 days, and you’re looking at almost $1.5 million per year.
It became clear that some backup and archive tables were inadvertently being included in production pipelines. In the end, data engineers spent a significant amount of time troubleshooting anomalies that could have been avoided.
While these duplicates weren't causing any immediate issues, they were quietly inflating compute and storage usage on a massive scale. Worse, they distorted key metrics and posed a risk in regulatory reporting.
The Solution: Visibility and Prevention with Soda
With Soda providing the necessary visibility, the data team used their domain expertise to:
- Investigate the anomaly
- Perform a root cause analysis (RCA)
- Understand how the duplicates entered the system
- Design low-code checks to catch and prevent issues going forward
Soda didn’t hand them the solution, but it gave them the signals. It was the team’s know-how that turned those signals into action.
That’s the kind of human-in-the-loop approach that makes modern data quality work.
Lessons learned: Prevention Beats Investigation
Many teams only investigate when something breaks. But costs? They creep in quietly. There’s rarely a single red flag. Just a slow, steady rise in storage and compute bills that goes unnoticed until someone finally asks, “Why are we paying so much?”
So, rather than waiting to discover data quality issues again, our customer set up automated checks to detect duplicates before data reached any models or dashboards.
With Soda’s lightweight, YAML‑driven approach, they:
- Quantified duplicate rates at the row level.
- Flagged entire tables when two tables shared the exact same row count (a strong duplication signal).
Setting up these checks took less than a day of engineering time—no Spark jobs or custom scripts required.
Let's see how they did it:
1. Define a “duplicate_percent” check
checks for {{ table_name }}:
- duplicate_percent(column_name): warn if > 0.1This simple metric computes the percentage of duplicated rows on the specified column(s). A threshold (e.g., 0.1%) triggers warnings.
2. Surface table‑level duplication
checks for {{ table_name }}:
- row_count: warn if equals {{ other_table.row_count }}By referencing another table’s row count, Soda flags when two tables match exactly—an easy way to catch cloned tables.
3. Integrate into existing pipelines
- Plug in the Soda CLI or Python SDK at the end of your ingestion job.
- Soda scans run in seconds, emit JSON reports, and push alerts to Slack or PagerDuty.
That’s it. No heavy orchestration or extra compute clusters. Soda runs where your pipelines already run.
Alerts went out to the data engineering team in real time. And, instead of discovering the problem months later, engineers fixed schema deployments, updated ingestion jobs, and deleted redundant copies within hours.
The Results: From Invisible Waste to Measurable ROI
In short, duplicate records are not just a technical problem; they pose a significant and multifaceted threat to operational efficiency, financial performance, and organizational trust.
Automated data quality checks not only save millions but also cultivate a culture of trust and efficiency. The financial and operational ROI is significant and immediate.
What's next?
With Soda in place, the team continues to:
- Expand automated monitoring to new pipelines.
- Use SodaCL to implement more contractual expectations.
- Explore Soda's AI features to reduce manual rule-writing.
What started as a solution to a single costly problem evolved into a blueprint for proactive data operations.
Key Takeaways
- Duplicates hide in plain sight: They don’t break pipelines, but they bleed your budget.
- Prevention over investigation: Shift‑left metrics monitoring catches issues early.
- Low‑code, high‑impact: A few lines of YAML and a Soda scan integrate seamlessly into any data stack.
- Seven‑figure ROI isn’t fiction: At scale, a simple data quality check can pay for itself many times over
No pipelines were harmed in the making of this blog post. Only wasted tables were deleted.
Want to know what’s hiding in your pipelines?
Schedule a demo with the Soda team to find out how much you could save, not just on duplicates, but across your entire data quality spectrum.










