


at
HelloFresh is on a mission to revolutionize the way people eat. With delicious recipes, high-quality ingredients, and convenient meal solutions for every occasion, the company relies on data as a key strategic asset to optimize marketing spend, improve the customer experience, streamline supply chains, and reduce operational costs.
The company’s data organization, with 100 professionals working in cross-functional domain teams and another 50 in central functions, plays a critical role in ensuring that the business operates on trusted, high-quality data.
In 2021, HelloFresh began the transition from a centralized data organization to a data mesh, an organizational model designed to empower teams to produce, access, and use reliable data at scale.
The challenge: scaling data access and reliability across a growing organization
Less than a decade ago, HelloFresh’s data setup was familiar to many growing organizations: a specialized, centralized team focused on warehousing data and producing reports for analysts and executives. This siloed model made the data team the sole keeper of knowledge: what data existed, how it was managed, and how trustworthy it was.
However, as the volume of data and demand for access to it grew, this structure became a bottleneck. As the team struggled to meet demand, data quality suffered, and a lack of reliability and quick access to data began to stagnate innovation.
By early 2020, the team recognized that the constant firefighting due to the lack of data quality standardization and uncertain ownership was unsustainable. To unlock analytical data at scale, they needed to stop solving the same data quality issues repeatedly and create a foundation for scalable, trusted, and decentralized data access.
To enable this, the central team decided to pivot from data warehousing to a data mesh model, which emphasizes domain ownership, self-service capabilities, and shared responsibility for data quality.
The solution: establishing a foundation for trust
To ensure the success of their data mesh initiative, HelloFresh needed to improve data quality and introduce data product thinking, treating datasets as products with defined ownership, service levels, and value to their consumers.
This required a self-service data quality platform that could:
Integrate seamlessly with existing infrastructure
Include built-in governance capabilities
Support global policy monitoring
Enable quick setup of data quality tests across domains
This would allow domain teams to be autonomous while also aligning data quality monitoring across the enterprise to improve feedback loops, innovate faster, and boost business confidence.
After an extensive selection process, HelloFresh chose Soda Cloud as its self-service platform for data quality testing, monitoring, and governance. The team’s goal was to empower analysts and data scientists, those comfortable with SQL but not necessarily with coding, to manage data quality autonomously.
By adopting Soda instead of building an in-house solution, HelloFresh accelerated implementation while benefiting from a ready-to-use interface, automation features, and monitoring tools. From evaluation to beta rollout to realising the tool across cross-functional teams, the implementation took just three fiscal quarters.
Building the data mesh: key components
HelloFresh’s data mesh initiative is built around four main elements:
Domain-oriented, decentralized data teams
Data products
Federated and incentivized data governance
A self-serve data platform
1. Domain-oriented data teams
To decentralize ownership, HelloFresh formed Data Domain Teams made up of Data Engineers, Data Analysts, Data Scientists, and Data Product Managers. Each team became responsible for building and maintaining data products, ensuring compliance, and making their data accessible across the organization.
These teams do not report to a centralized authority but operate under federated governance standards. They use tools like Soda to monitor and maintain quality while adhering to shared expectations.
To support this transition, the original data warehousing group:
Maintained existing commitments while building new cloud infrastructure
Enabled self-service data reporting
Gradually decommissioned legacy systems and redefined Service Level Objectives (SLOs)
2. Data as a product
HelloFresh redefined its relationship with data by treating it as a product: a purposeful, consumable asset managed with the same rigor as any customer-facing product.
Each data product is owned by a Data Product Manager who:
Identifies internal consumers and their needs
Defines Service Level Objective (SLO) to ensure quality and reliability
SLOs at HelloFresh are not strict contracts, but rather alignment tools that clarify expectations between data product owners and data consumers so as to foster trust. An example could be as simple as: “Ensure this dataset is updated every morning at 8:00 AM.” The main goal is to explicitly describe what the data product provides while also ensuring that the data is fit for purpose.
Data Product Managers and engineering teams use Soda to run data quality tests, monitor their data products, and provide evidence of data reliability to stakeholders.
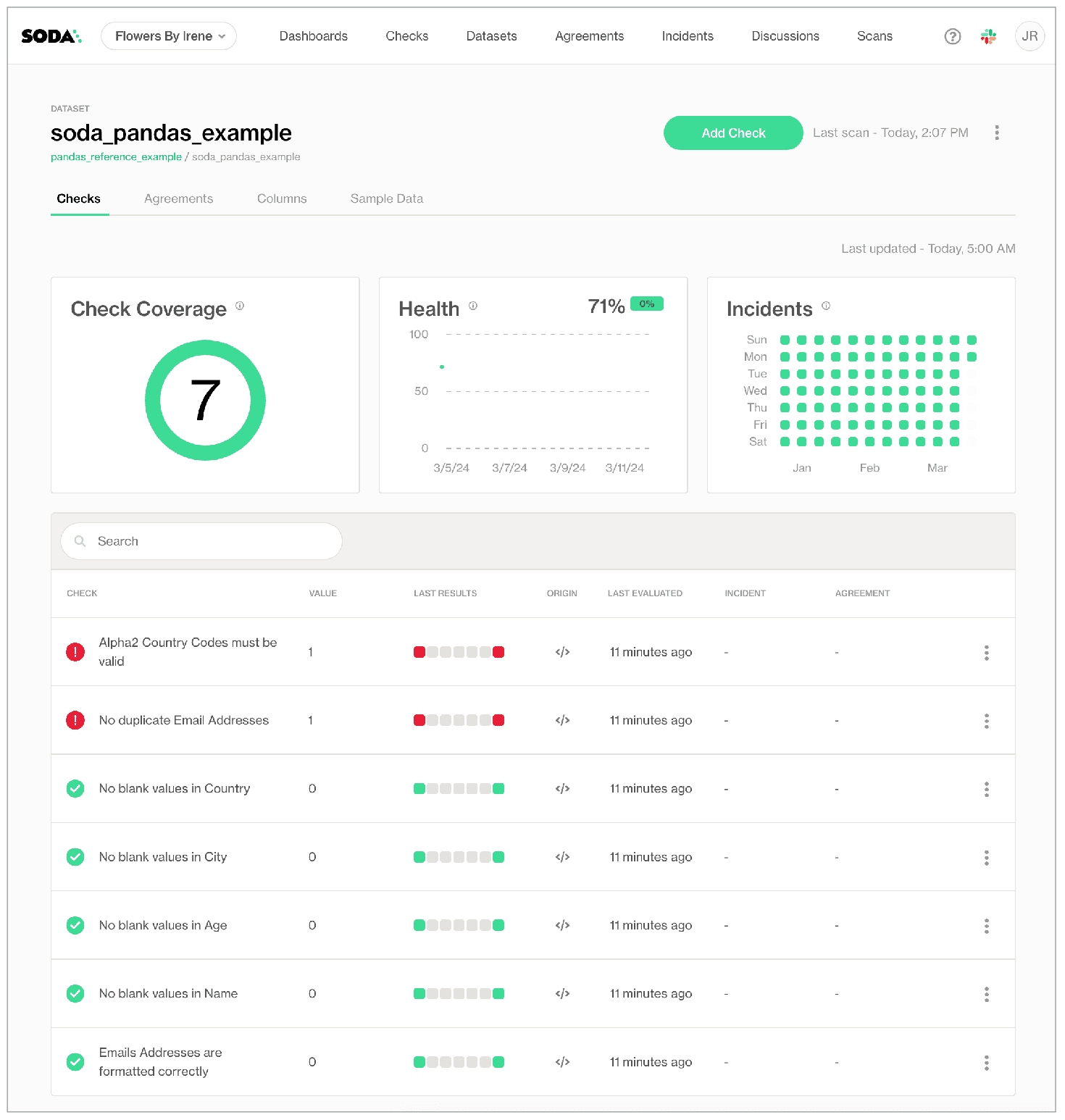
3. Federated and incentivized data governance
HelloFresh reimagined data governance to encourage accountability rather than control. Their approach focused on developing a framework of data quality standards that apply to all data products, helping teams understand the framework, and providing support and clarity about expectations involving the data products.
The central Data Governance Team defines global data quality standards, offers guidelines, and supports domain teams through a Data Product Certification program. This voluntary program gamifies governance by awarding bronze, silver, and gold badges to teams that meet specific data quality, security, and documentation criteria. This approach, described internally as “governance by convenience”, ensures that the right way to test and validate data quality is also the easiest.
Soda is used as the data quality testing tool within this process, and the company plans to automate certification using Soda’s capabilities in the future.
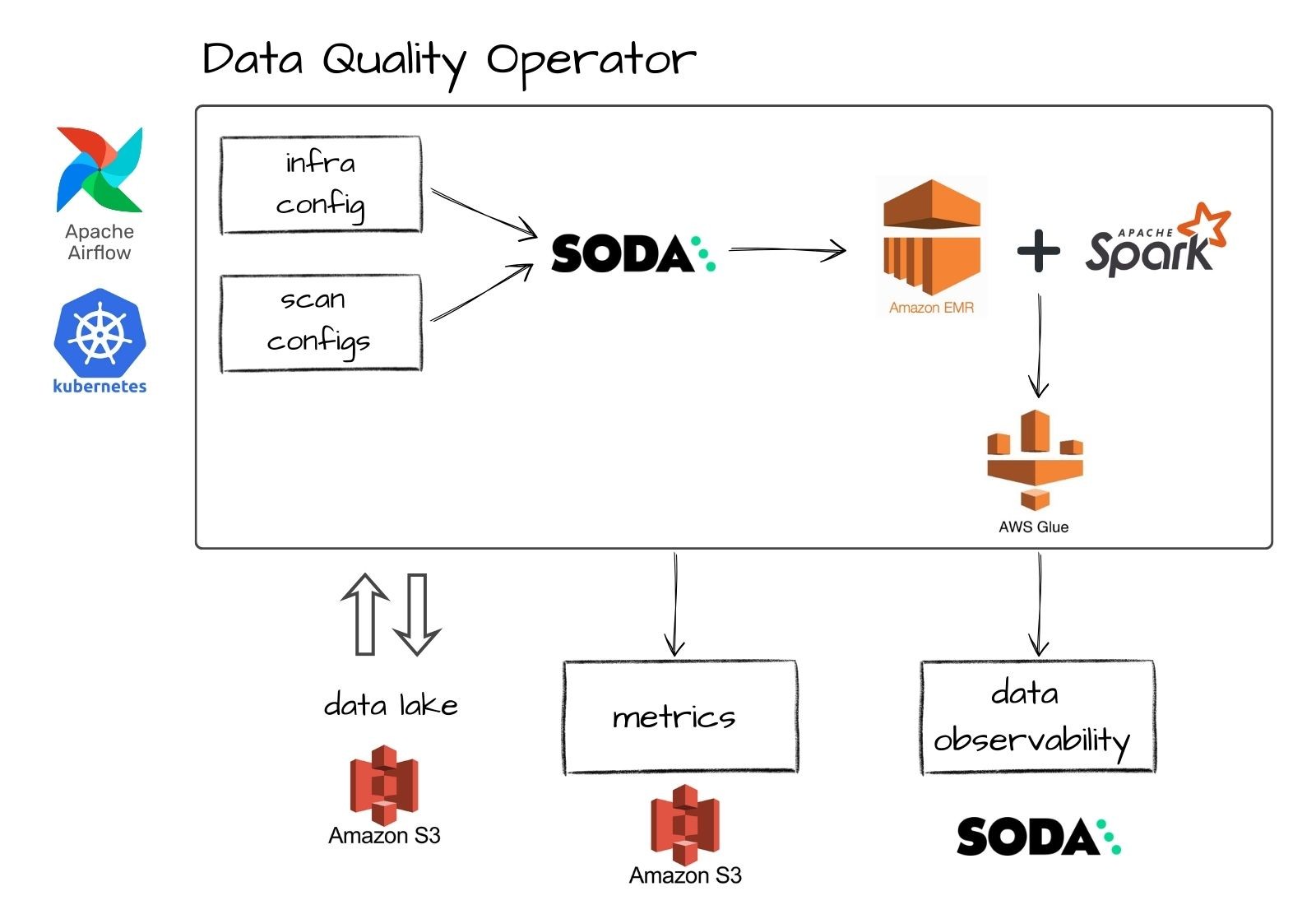
4. Self-serve data platform
HelloFresh discovered that in a data mesh, a self-service data platform must respect the alignment of autonomous, decentralized operations teams and their need for quick and reliable data access. The final step was then building a self-serve data platform that made data discoverable, interoperable, secure, and trustworthy, democratizing access so everyone has the data they need to do their jobs.
To achieve this, HelloFresh prioritized tools that would integrate with existing systems and allow teams to create and monitor tests easily. The company wanted to avoid the overhead and investment necessary to implement and maintain another data pipeline tool. So it was worth leveraging the product of third-party data-quality experts.
Soda’s accessible interface, YAML-based configuration, and out-of-the-box metrics made it an ideal fit. Data analysts and scientists could define data quality checks using familiar SQL queries, while Soda handled the governance and visibility layers across the organization.
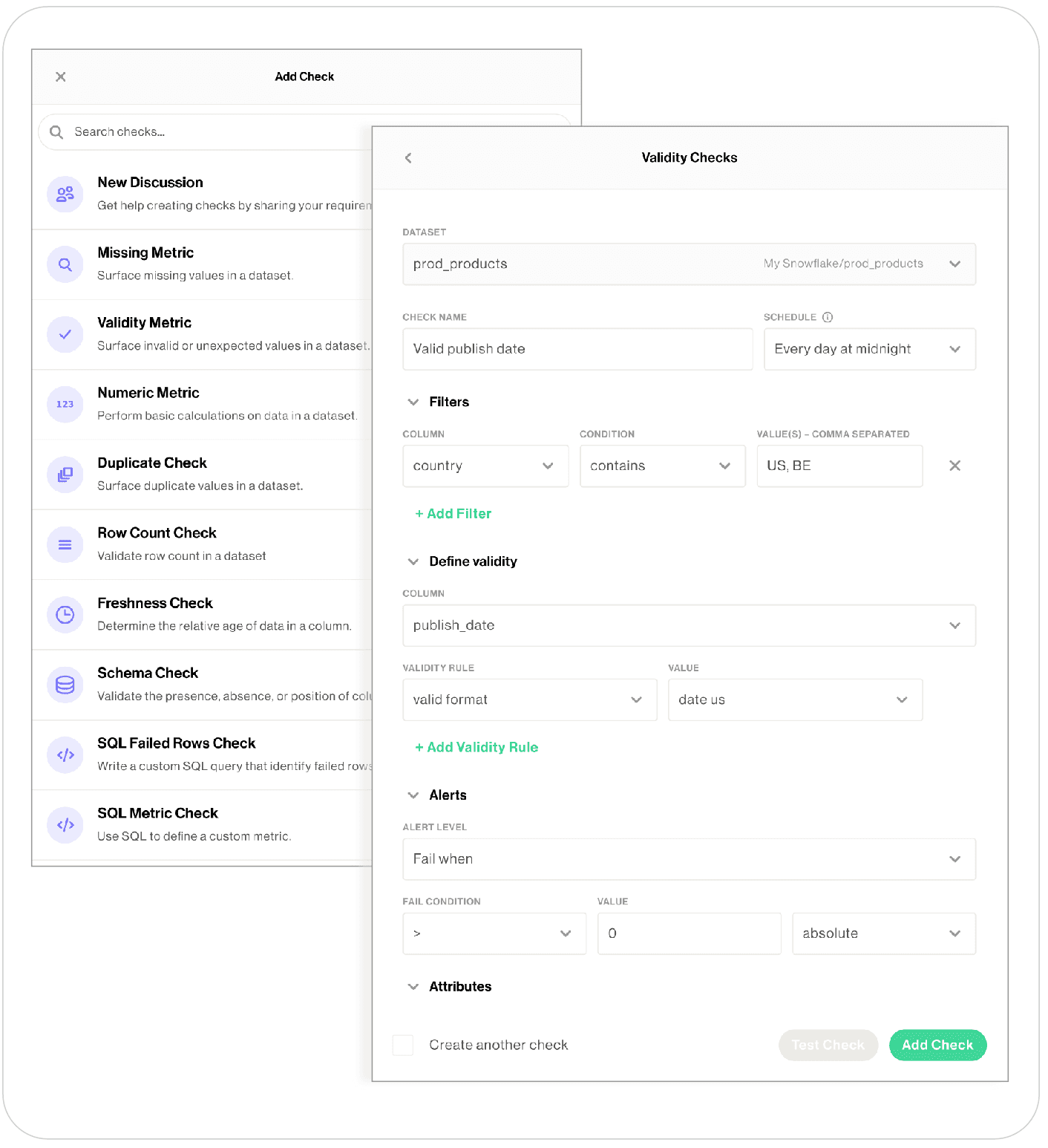
The Impact: a new standard for quality and collaboration
HelloFresh chose Soda to address critical data issues such as quality, governance, and mindset. Now, Soda Cloud provides their core data teams with the tools they need to confidently invest in improving data quality and to maintain a framework that supports:
Autonomy and accountability across domain teams
Standardized and transparent data quality checks
Reduced manual review work
Higher data literacy and trust company-wide
Soda became a key enabler in HelloFresh’s transition to a data mesh model, allowing teams to move faster while maintaining reliability and consistency in their data.
Culture & Engagement
Building trust in data was about more than just bringing in new tools and architecture; it was about listening to the team and understanding what they needed.
During this data mesh implementation process, HelloFresh organized a global hackathon called "In Data We Trust?!" in which cross-functional teams were challenged to create a Standard Data Quality Dashboard.
The event transformed data quality into a collaborative mission rather than a technical issue. Teams investigated how to visualize and compare quality across datasets using six key dimensions — accuracy, completeness, consistency, timeliness, uniqueness, and validity — while reducing the mental load of interpreting reports.
HelloFresh built a culture of data literacy, collaboration, and ownership by involving engineers, analysts, and operations teams in the same challenge, allowing everyone to see data quality as a shared responsibility.
Building trust in data isn’t a one-time project; it’s a culture. And that culture grows faster when teams learn, create, and celebrate together. Read more about the HelloFresh hackathon here.
Looking ahead: getting ready for data analytics at scale
As HelloFresh continues to evolve its data mesh, the company is laying the groundwork for automated data product certification and expanding the reach of its self-serve platform.
Even though moving toward data mesh is more than just "changing the tools we use," the tech choices they've made are quickly helping them reach their goals of making data more accessible to everyone. The shift to distributed data ownership, supported by Soda, has given the organization the confidence to scale its data analytics capabilities sustainably and securely.
Even as the journey continues, HelloFresh has already established the foundation for a future where high-quality, trusted data products empower every team to make better decisions. Their system is now ready to take advantage of the business value and efficiency that shared data ownership can bring.
Discover Soda’s data quality platform to implement data quality into your data mesh.
Disclaimer: This material was created in 2022. Please note that figures and statistics may have changed, and there might be minor code syntax or UI path differences since its publication. |
|---|
Learn more
Data Quality in the Context of a Data Mesh at HelloFresh
Join Mario Konschake, Product Lead Data Platform at HelloFresh, and Maarten Masschelein, CEO at Soda, for a discussion on how HelloFresh implements data quality monitoring in the context of a data mesh.
Engineering Data Reliability into a Data Mesh at Data Innovation Summit
Abhishek Khare, Senior Data Engineer at HelloFresh, and Natasha Lauer, Head of Marketing at Soda, discuss how HelloFresh built and implemented a data quality solution using Soda into their self-serve data platform.
Data Mesh at HelloFresh - Data Mesh Learning Meetup
The HelloFresh team covered their data mesh journey to date and what they have learned along the way.
Get in touch
Schedule a demo with the Soda team or request a free account to find out how much you could optimize your data quality strategy across your entire data ecosystem.










