
It's been two years since we released Soda SQL, and just over one year since we released Soda Core with SodaCL, our domain-specific checks language. Since then, our open-source library has earned almost 1400 stars on GitHub, 750 teams in production, and 2000 community members on Slack, many of whom have contributed to the library.
Over the past year, we’ve expanded Soda Core to support everything an organization needs to be successful, which includes dozens of data sources and check types. With Soda Core standing strong and working well, we’ve started focussing on the next big thing: Soda Library.
Soda Library takes data quality testing to the next level by extending Soda Core and adding tons of convenience and automation features. Soda Library aims to become the place for all our features that are linked to our commercial offering. Take checks that require the metrics store for example. These were never usable in Soda Core anyways, so we will gradually move these to the new Soda Library as well.
Available now, this new extension to Soda Core enables data teams to configure check templates, generate check suggestions, and utilize group by checks.
We’re proud to have co-designed each of these features with our community of Soda power-users. These features address challenges that our customers were facing in taking their data quality testing to the next level. If your organization has challenges with Soda Core, please reach out to us so we can organize a design sprint.
For our existing open-source Soda Core users, there will be no changes or disruptions. Soda Core will remain free to use and the source code will always be publicly accessible. Soda continues to support Soda Core but our team will not be actively developing Soda Core-only features in the near term, unless there’s a good case for them. We continue to welcome contributions to the OSS project, and will keep releasing updates as Soda Core remains a foundational element that everything else is in our product stack built on. If it suits your needs, please enjoy!
This blog was created with previous versions of Soda Core and Soda Cloud, so there might be minor code syntax and UI path differences. If you have any questions, refer to https://docs.soda.io/ |
|---|
Upgrade to Soda Library
Soda Core users can upgrade their pipelines very easily. Simply uninstall Soda Core, then install the library from the command-line without changing any configurations, checks, or integrations.
Questions? Join our community or reach out to your Soda Customer Engineer.
Let's explore what's new with Soda Library.
New feature: Check Suggestions
We’re absolutely thrilled to release Check Suggestions, an helpful CLI assistant that profiles your data and suggests checks for you to adopt. This is a great tool for both new and experienced users alike. Have no fear, help is here!
Instead of writing your own data quality checks from scratch, check suggestions prompts you through a series of questions about your dataset so that it can leverage the built-in Soda metrics and prepare quality checks tailored to your data.
The result of the check suggestions is a YAML file that you can easily add to the testing you’re already doing in production (e.g. Airflow) and during development (e.g. Git).
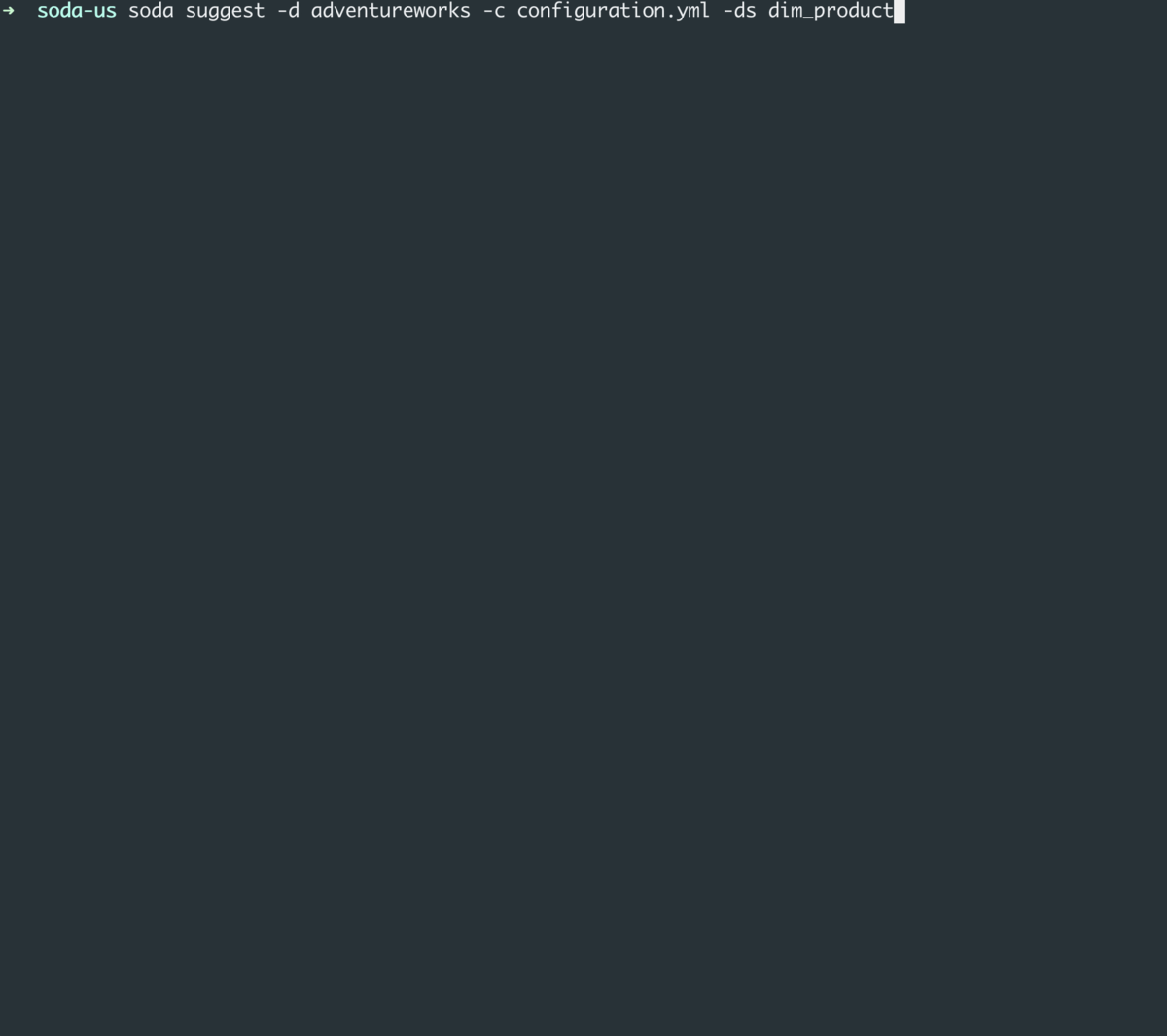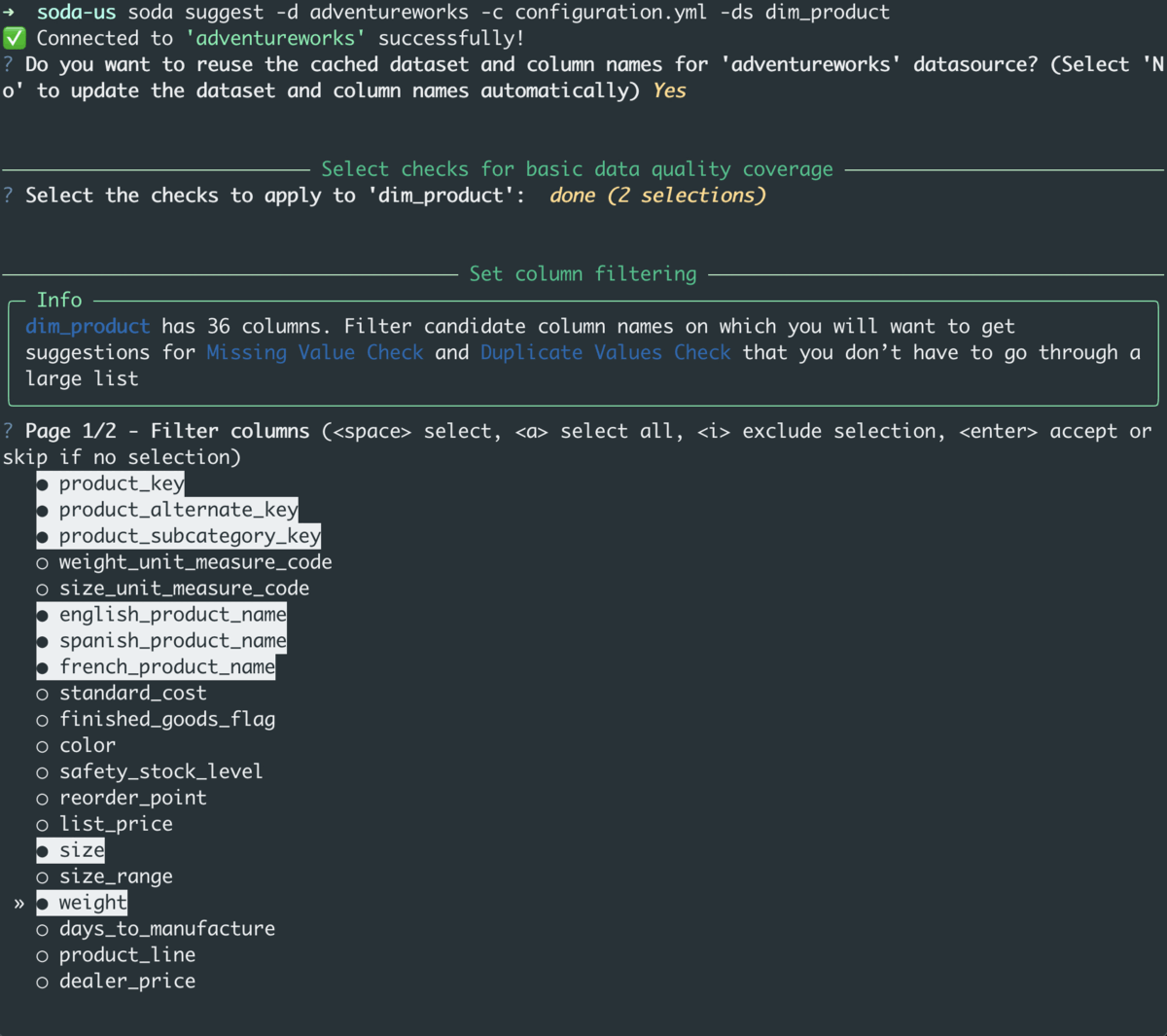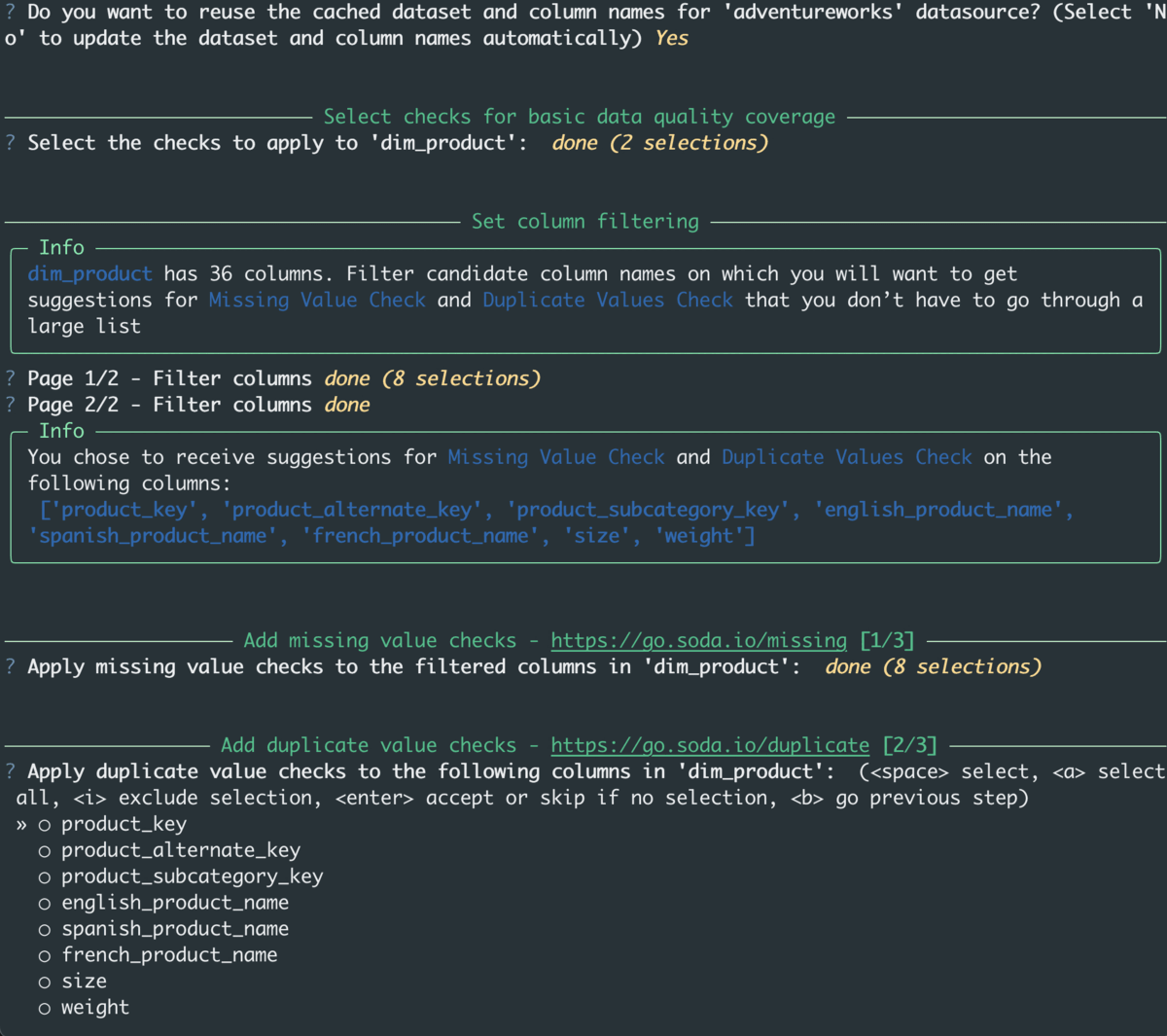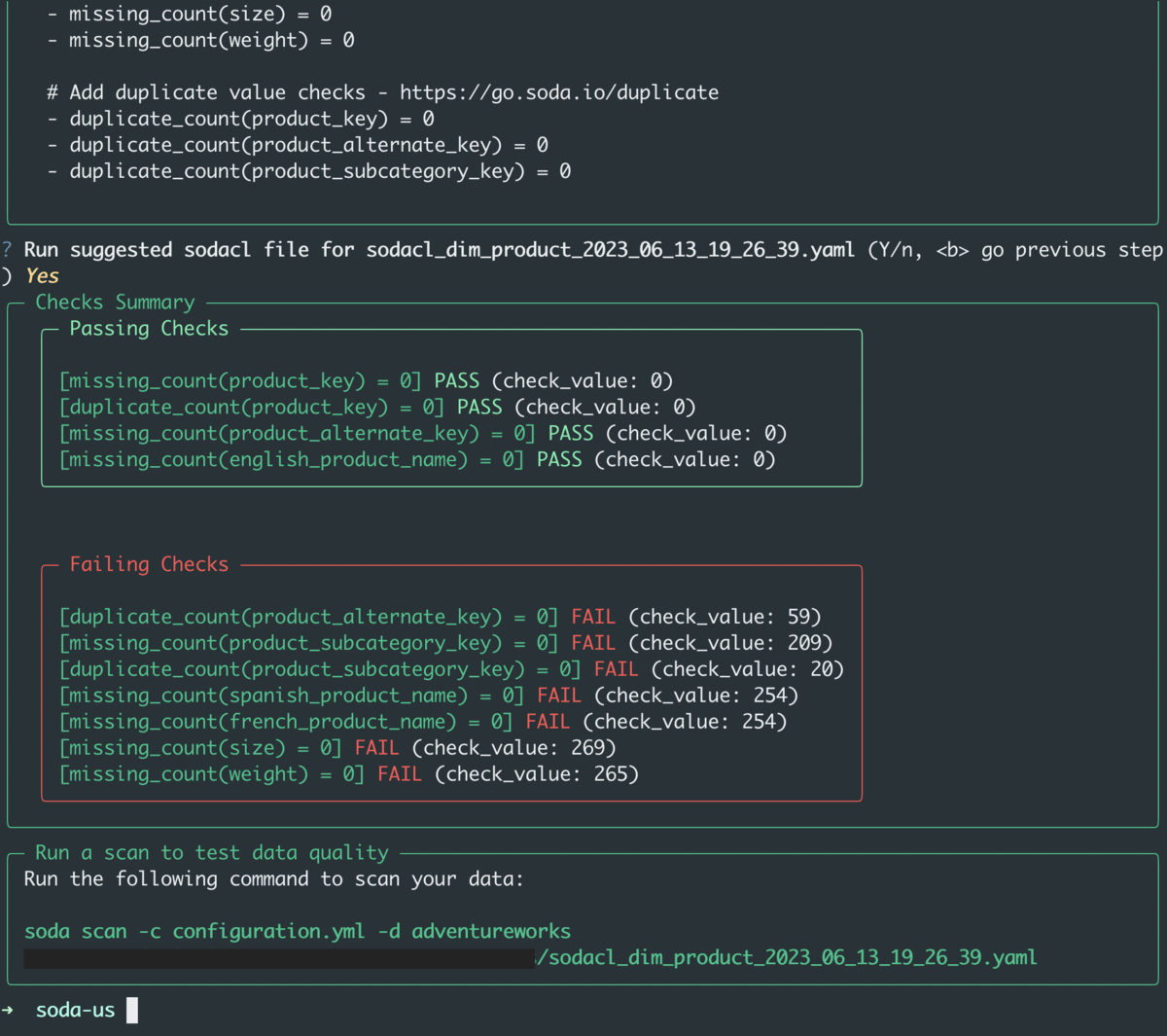
Docs: Check Suggestions
New feature: Group By and Group Evolution
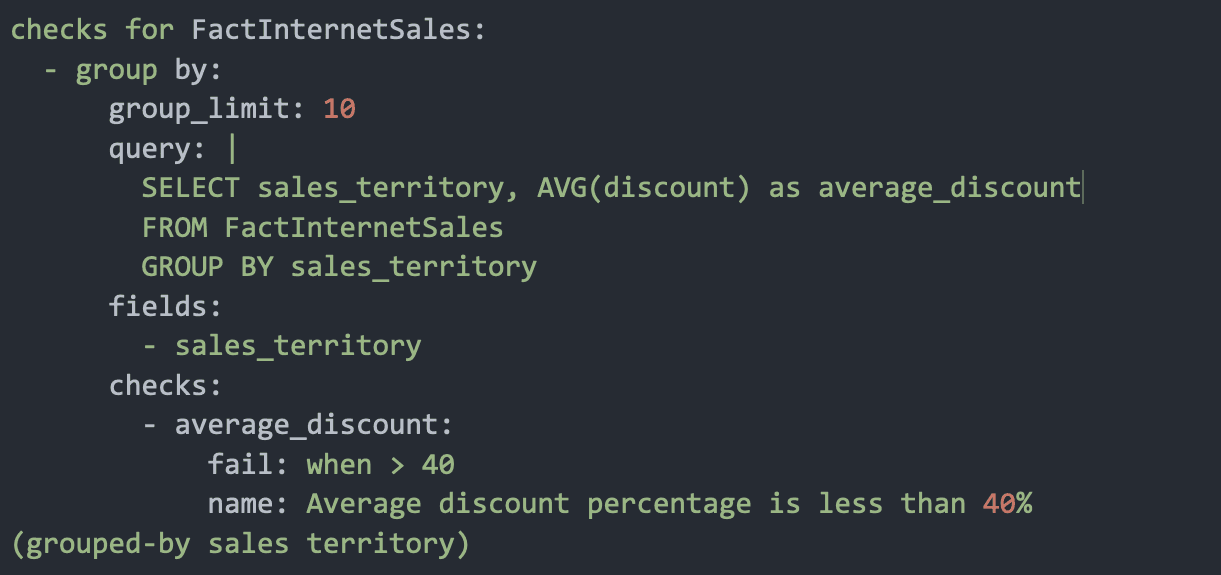
For results that are better when grouped together, we’re pleased to offer SodaCL’s newest configuration and check: Group By and Group By Evolution. This often-requested feature allows data teams to apply checks to every group.
This check finds all groups in a dataset dynamically and then performs one or multiple checks on each group. This allows you to scale checks across critical dimensions.
Add a Group By configuration to specify the categories into which Soda must group the check results. When you run a scan, Soda groups the results according to the unique values in the column you identified in fields.
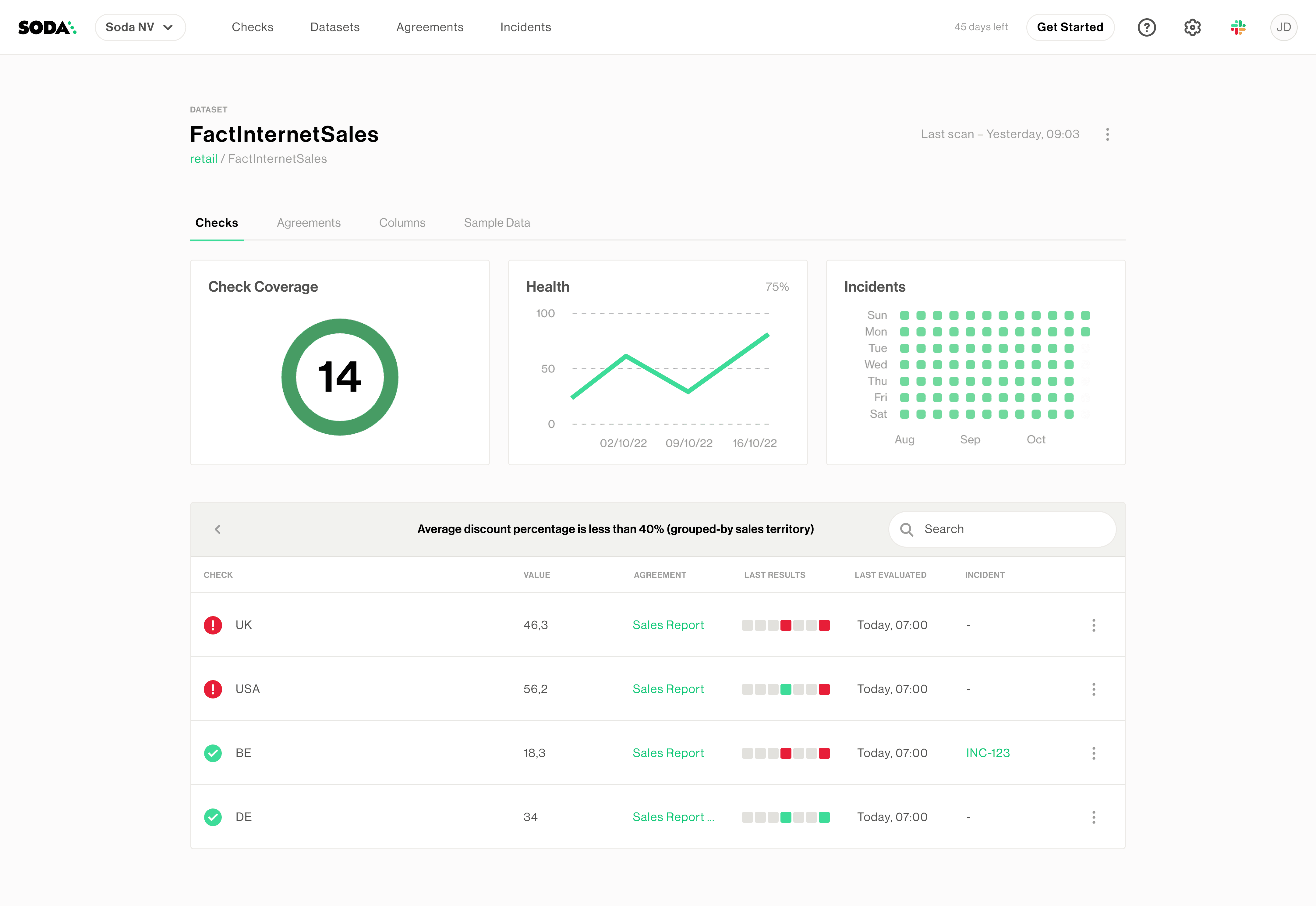
Docs: Group By
Use a Group Evolution check to validate the presence or absence of a group in a dataset, or to check for changes to groups in a dataset relative to their previous state. Soda Cloud’s Metric Store keeps track of the historical state to facilitate alerts for changes to categorical groups.
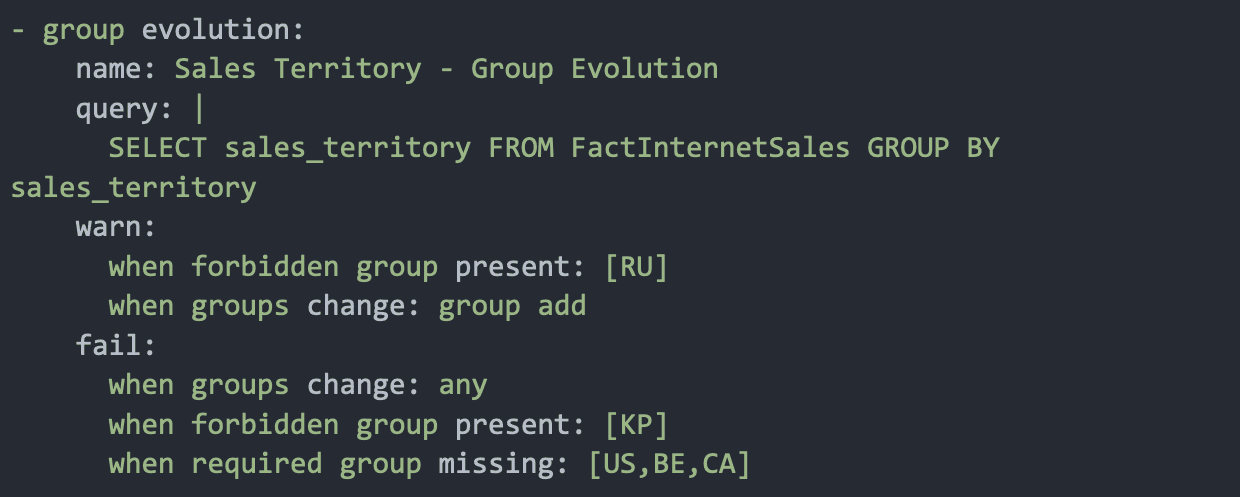
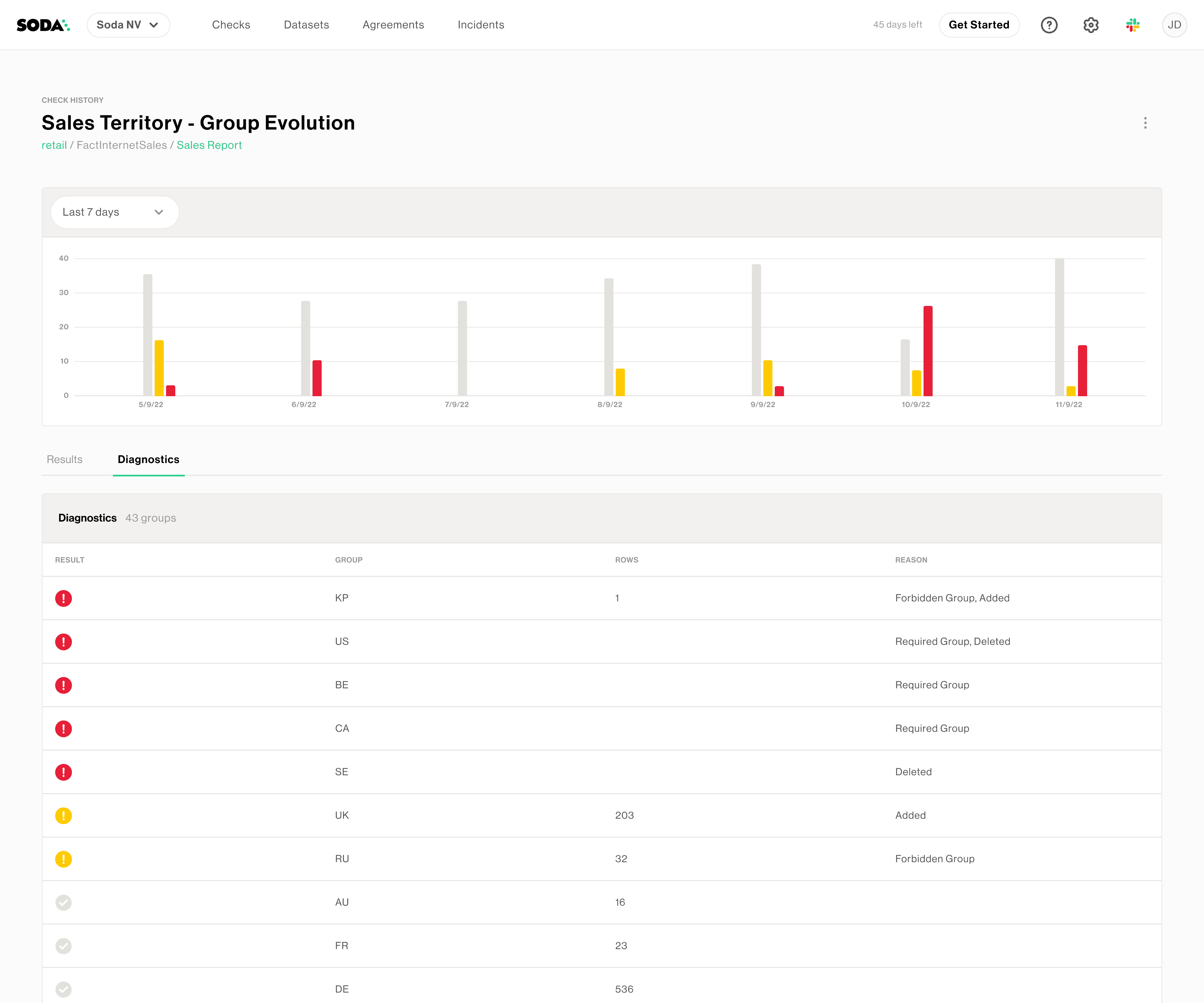
Docs: Group Evolution Check
New feature: Check Template
Ever wanted to create a library of checks for everyone in your organization to reuse?
Wait no more! Now you can write once and apply often.
Today, you can take advantage of Soda Library’s support for check templates. This new SodaCL configuration allows you to prepare a user-defined metric in a template YAML file, then use the metric as often as you like in various checks and YAML files.
Use a SQL query to define a template that executes a specific check for data quality.

Then, use the check template in a checks YAML file to define thresholds for the check. Soda accesses the template during a scan.

Docs: Check Template
What's next?
At Soda, we’re going into the summer laser-focused on helping our customers scale the use of Soda across their organizations.
In a few weeks, we’ll announce a brand new way for data consumers to self-serve and easily get involved when it comes to defining data quality expectations, so that data engineers can focus on the reliability of their pipelines, and ultimately the development of new data products.
When it comes to the future of Soda Library, we plan to add more check types, and make it easy for users to use the CLI to configure our commercial products like Soda Cloud and Soda Agent.
Meet us in Las Vegas or San Francisco, June 26 to June 29
We’ll be releasing more AI-powered features later this June. If you're attending Data & AI Summit in San Francisco (booth #21) or Snowflake Summit in Las Vegas (booth #1131-C), please come and meet Team Soda to learn more.
Discover Soda Library
For all Licensed Customers and Free Trial Users, you can now migrate to Soda Library. You'll need to install Soda Library from the command-line or upgrade your Soda Agent to seamlessly shift to Soda Library without changing any configurations, checks, or integrations.
If you're new to Soda, you can get started here. We think you'll love it.











