
.png)


Every organization knows that data can bring a lot of business value. We’re living in the age of Big Data, fully immersed in a data-driven world, etc. But here’s the kicker: less than half of data teams actually manage to deliver real value to their companies. And, let’s be honest, no one talks about that. It doesn’t exactly make us look good.
As data engineers, analysts, or CIOs, we all know what good practices look like. But putting those into action? That’s the tricky part. It’s always easier said than done.
Take Data Quality dimensions: we know they exist in theory, but in practice, we often just hope they stay in the back of our minds. They're usually treated as abstract concepts tied to best practices we think we’re following… unless we’re not. But since no one's really tracking them, and no one’s asking for a quarterly update, they tend to slip under the radar.
In my opinion, the concept behind DQ dimensions is figuring out what can be wrong with data. We're not thinking about them constantly. And we shouldn't, at least actively. On top of everything else, I don't believe I'd have the mental capacity to extrapolate every single action I take into theoretical explanations of why I'm doing it. I doubt I'm the odd one out here. But, when shit hits the fan, it's nice to have something to hold on to that works.
Here's my very own comprehensive list of DQ dimensions that I remind myself of often. By "my very own list" I mean the one on the DAMA Guide to the Data Management. And by "often" I mean whenever I run into inexplicable issues that force me to go back to basics. Later on, we can dive into some automated Data Quality checks and see which dimensions they can cover.
What Are the Core Data Quality Dimensions?
While there are many frameworks for categorizing data quality dimensions — including the DAMA Data Management Body of Knowledge, the ISO 8000 standard, Gartner's Data Quality Framework, and the Conceptual Framework of Data Quality (Wang and Strong 1996) — most converge on similar core concepts.
Framework Comparison:

My 11 DQ Dimensions List, Which Is Probably Not Your List
If this list is one thing, is thorough. Not all use cases will need to cover all these DQ dimensions, nor will it be possible to have checks and automated processes that ensure every dimension is included. However, it's nice to remember them and think about them. At least every once in a while.
%20(1).jpg)
- Completeness: Does the data have missing values? If so, are those acceptable or expected?
- Accuracy: Does my data reflect reality? To know this, do I have enough industry know-how to detect when it doesn't?
- Consistency: Are there any inconsistencies in the data? Is everybody using the same format rules? Aka, does data in one place match relevant data in a different place?
- Currency: Or, as I prefer to call it, "freshness". Is the data up to date? Does it describe reality as it is now?
- Precision: Level of detail of the data element. Does this numeric column need four decimals or is it OK to find truncated values?
- Privacy: Can everybody access this table? Should everybody have access to this table? How can I monitor who has made changes or viewed this dataset?
- Reasonableness: Basically and redundantly: are the values I'm seeing reasonable? Is it unreasonable that sales today are 500% of the average sales in the past 30 days? Or is it December 24th?
- Referential Integrity: There's a lot of talk in the industry about what integrity is as a dimension. But I'll ignore it because I can, and only define referential integrity: whenever a foreign key acts as a unique identifier, the record on the referenced table must a) exist, and b) be unique.
- Timeliness: When is information available? When is information expected? Is data available when needed?
- Uniqueness: Pretty self-explanatory: are there duplicated values?
- Validity: Does the data make sense? Is it usable for (excuse the redundancy) users, or will they get a bunch of errors when trying to validate it?
Not everyone will agree completely with this list, but most people will agree with some of it. That's all that matters. Every use case will require looking at different dimensions, and every industry will have different perspectives on what parts of Data Quality are relevant in the field. However, the basis of Data Quality should look the same for everyone. That's why, on this day and age, we should all set up automated checks when working with considerable amounts of data
Why Implement Data Quality Checks?
Well, firstly because there's simply no way data will be good if we dump it in a data lake and just use it as is. Where's the pride in that. But secondly, and here's how we convince organizations to invest in data teams and give us cool tools and more hands, because Data Quality brings in more money.
Companies with bad Data Quality frameworks are lagging behind. Good data leads to good business decisions and good business practices. It results in great predictions that allow any organization to get ready for market shifts before they happen, and not just react to them. It allows for understanding of user experience and needs. And more importantly: it's cost effective. Good data prevents all the costs associated with fixing inaccurate data and re-analyzing.
1. Better Business Decisions
Data-driven insights and predictions have a very clear foundation. It's on the name. Data. Good data enables organizations to produce actually data-driven decisions.
One of the steps towards good data are Data Quality checks, and it only makes sense to automate them. Not only to spare some poor engineer the manual labor, but also to have consistent checks running regularly and raising alerts as soon as something goes south.
2. Reliable Predictions & Forecasting
When data is good, accurate and relevant, then it's easy for different sections of an organization to make reliable predictions. This is critical to see market shifts when they're headed our way.
Different teams will focus on different aspects of the upcoming future, but they'll all be building their prognosis on the same data. That's why it should be good all across the board.
3. Cost Optimization Through Team Alignment
Communication between teams is essential to any organization's success. Most companies don't have siloed data teams anymore: data engineers are working hand in hand with every non-IT team out there, which leads to endless calls to figure out what they want and need.
To optimize these relationships, it's essential to ensure that everyone is up to date on what's expected of data, what it will be used for and how to get there. Is it alright if a dataset has some incomplete values? What currency will we use across tables?
Relevant questions won't always happen within the data team, nor should they. They'll come from the data users, who will be the ones to show us which dimensions are important. Having open communication with everybody saves time, effort and money, optimizing data processes in general.
4. Peace of Mind with Automated Monitoring
In order to have good data products, we need good data systems. That encompasses every process the data goes through, from collection to analysis and predictions.
We need to keep Data Quality in mind not only when building a pipeline or talking to data consumers about their needs, but even after we're done working with the data. Will it be sustainable in the long run? As it undergoes requests and transformations, will the data still be good? That's where automated checks play their role.
When validating data before, during and after a pipeline, we ensure that a specific data product is to be trusted. And we didn't have to move a muscle, because it all happened automatically. The human touch is still there, in building the pipelines, coming up with the checks, writing them, analyzing the results, figuring out what's wrong. But we get the peace of mind of knowing that, unless there's an alert, data is doing well.
Getting Started with Automated Checks
Anyone who has data can start applying Data Quality checks today. It's an easy process that can (and should) be implemented in every stage of a data system. So everyone is welcome. This tutorial will cover some basic DQ checks to show that anyone can implement these, even with no code experience.
So, let's get started!

Requirements
- A Soda Cloud and create an account for free
- A connected data source (In Soda Cloud, "Your Profile" > "Data Sources" > "New Data Source")
If you're running Soda in your own environment, you can apply these checks with SodaCL (Soda Checks Language).
If, on the other hand, you want a no-code solution, go to "Checks" > "New Check" on Soda Cloud and just... fill out the blanks.
For the sake of simplicity, the following checks are implemented on a toy database in Snowflake. It includes the datasets ACCOUNTS and CUSTOMERS., both with information about transactions and, you guessed it, customers. The checks are written in SodaCL and can be used in any implementation of Soda. For a newbie-friendly approach, this can happen without leaving the Soda UI.
Implementing Checks
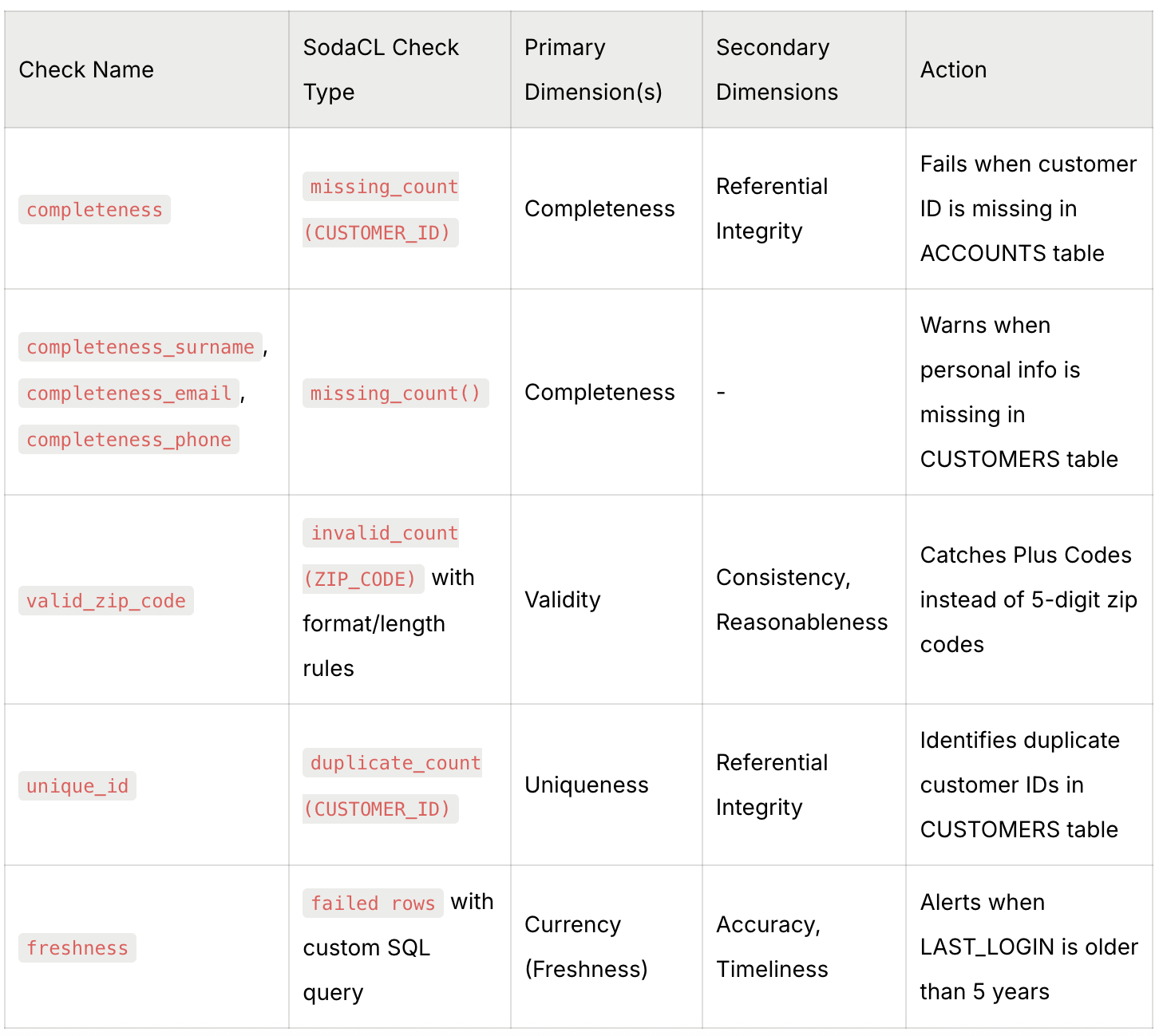
Completeness
The first check, and most common one to include before or after any pipeline, is a completeness check. In this case, I want my check to fail when customer ID is missing because that entry will be unusable.
checks for ACCOUNTS:
- missing_count(CUSTOMER_ID):
name: completeness
fail: when > 0However, I will only want an alert when personal info is not there. No failures are needed, I just want to know if we're missing values and pipelines to keep doing their thing after this check even if there are nulls.
checks for CUSTOMERS:
- missing_count(LAST_NAME):
name: completeness_surname
warn: when > 0
- missing_count(EMAIL):
name: completeness_email
warn: when > 0
- missing_count(PHONE_NUMBER):
name: completeness_phone
warn: when > 0If a check fails, we can further analyze why on our dashboard. Here, when clicking on the completeness check, there's a detailed view of the rows that are missing CUSTOMER_ID:

Validity
Validity has a lot to do with usability. Let's say business stakeholders will use this data to draw sales strategy by region. If they try to get metrics from zip codes, the data team must provide usable zip codes that can be grouped and mapped. In this check, the data team has agreed with the data users that zip codes must contain up to five digit numbers.
The goal is for this check to raise an alert whenever there are any values under ZIP_CODE that don't match the expected format.
checks for CUSTOMERS:
- invalid_count(ZIP_CODE):
valid max length: 5
valid format: integer
name: valid_zip_code
warn: when > 0Like in the previous example, we can further analyze which rows failed the check and raised an alert. In this case, the reason of failure is that some values under ZIP_CODE are Plus Codes written in OLC format, instead of being zip codes written in the expected numeric format.
.png)
Uniqueness
Customer IDs are extremely relevant in this database, so I want to check that they're not duplicated. If they are, this check must fail because all those entries will be unusable until fixed or dropped.
checks for CUSTOMERS:
- duplicate_count(CUSTOMER_ID):
name: unique_id
fail: when > 0The view on the dashboard confirms that there are customer IDs that point towards more than one customer.
.png)
Currency
For currency, or freshness of the data, we will be implementing a custom SQL check. This template can work for any SQL statement, which makes it versatile for every use case scenario. In this case, I want to know how fresh the information of an entry is based on the last time a customer logged into their account. If the log is older than 5 years, then the check raises an alert.
Note that the only SQL snippet written here is the fail query, everything else is SodaCL.
checks for CUSTOMERS:
- failed rows:
samples limit: 100
fail query: |-
SELECT *
FROM CUSTOMERS
WHERE LAST_LOGIN < DATEADD(YEAR, -5, CURRENT_DATE())
name: freshness
warn: when > 0Again, whenever checks fail, we can see the metrics and details on the dashboard. In this case, getting an alert means that there are several logins older than 5 years, which might be relevant information for the business stakeholders.
This type of SQL check is very useful for validations that don't exist by default on Soda Cloud, or even to customize existing checks with specific needs in mind.
How Data Quality Dimensions Map to Automated Checks
As with any relevant question and most good answers: it depends. It depends on the type of data analyzed, on the types of checks, on the expectations that stakeholders have on the data… The three checks we've performed have covered a couple of dimensions. The obvious one is Completeness. No need to explain that one. A not-so-obvious one covered by the completeness check is Referential Integrity. When a table points towards a customer ID and that value is missing, referential integrity is violated, which makes data across datasets unusable.
With the second check (valid_zip_code), we covered, of course, Validity. This dimension must be agreed upon by both data teams and business stakeholders. The validity will depend on the use case of the data, so data consumers need to have a say on what they need and expect. Here, some zip codes are not valid. But why? It's not the case that someone just wrote "my house" instead of a zip code; the code was there, it was simply in the wrong format. And that has to do with Consistency. When agreeing what is valid and what isn't, there's also a conversation on "what should we all be doing?". Should we be inputting zip codes or Plus Codes? Is it better to just input country and region? How much detail do we need on our customers' demographics? (which could also link to Precision. Just saying. It's all connected!). When having consistent data, validity usually follows. Also, a zip code with 10 digits and letters is not Reasonable.
The third check, unique_id validates, of course, Uniqueness. It does so where it matters: in customer IDs. Of course we can check uniqueness all across the board, but why? Age will not be a unique value column in a table with thousands of entries all belonging to different people. But IDs are expected to be unique if we want usable data. Moreover, we are again cross-checking for Referential Integrity; if IDs are not unique, tables that have CUSTOMER_ID as a foreign key will point towards two data points instead of one.
Lastly, what does the freshness check cover? Currency (or Freshness), for starters, since it's looking at how old or new is a piece of data. But freshness checks can also help us understand if data reflects reality as it is now. Accuracy not only has to do with real or inaccurate values, but also with how reality shifts and transforms. Salaries ten years ago are not comparable to current salaries in absolute values. So outdated data can be problematic from a freshness point of view, but also from an accuracy perspective.
Quick Reference: Check-to-Dimension Mapping
The Business Value of Dimensional Approach
Costs reduction
Taking a multi-dimensional approach when figuring out Data Quality across an organization means, firstly, reductions in costs. Why? Because less unusable data leads to less money spent on cloud storage. Less hotfixes lead to less operational costs (and less mental health costs within the data team, let's be real). This only means there will be more money and energy for improvement, growth, tackling that low-priority issue that's been on the To-Do list for months. Win-win-win!
Reliable predictions
When it comes to business advantages, besides cost reduction, having a data system that keeps Data Quality dimensions in mind, and Data Quality in general, also leads to more reliable analysis and/or predictions downstream. The data team will be happy, sure, but Sales will also be happy that their predictions are actually accurate, and Product will be satisfied with the metrics they're collecting, and every non-data team that isn't actively writing SQL queries but somehow uses data will enjoy life instead of hopping onto calls to fix broken dashboards.
Data Governance
When Data Quality is enforced, Data Governance follows. Things like compliance, management, security and monitoring become a lot easier if data users are accessing trustworthy information.
Money
And then, we come full circle. All this (less costs in data, data that can be trusted, better insights, happy teams, smooth processes) lead to the big selling point of today's blog: More Money. When a company uses trustworthy data, their image improves, their business outcomes are better and their revenue grows. All wins for everybody.
Conclusion
Data Quality checks are essential to any organization that wants to stay ahead of the game (in fact, more than 50% of orgs don't even measure how much bad data costs them). Just like a good Data Engineer tends to have industry know-how, good Data Quality needs to take context into account, which gives businesses the power of getting the data-driven insights that they yearn for.
Analyzing the dimensions of Data Quality is a way of deciding what's relevant and what's not. By having different checks that cover all relevant dimensions, we can rest assured that the data will be good. And who doesn't love good data?
Good data provides good insights and, above all, trustworthiness. Data that can be trusted is any Data Engineer's goal, as well as any non-data team's dream. Nobody wants datasets that aren't accurate because there's no valuable action that can be taken from them. A dataset with 99% completeness is worthless if 50% of the data is duplicated. So, by ensuring all Data Quality dimensions, we also ensure that any person looking at the data trusts its contents.
Our value as data experts is, of course, data that can be trusted, but also the added value that comes with it. Better data leads to better decisions, better outcomes, more growth and, ultimately, more money. That's the line we sell to our organizations to get better software (or keep the one that already works).
The implementation of Data Quality tools like Soda is a must for every organization today, and working through the lens of the dimensions of Data Quality can help data and non-data teams alike to achieve their goals.
Frequently Asked Questions
Which framework should I use: DAMA, ISO 8000, or Wang & Strong?
Choose based on your organization's needs. DAMA is comprehensive and widely adopted in data management. ISO 8000 is ideal for compliance-focused industries. Wang & Strong works well for academic or research contexts. Most frameworks overlap significantly in core concepts.
Can one check cover multiple data quality dimensions?
Yes! Most automated checks validate multiple dimensions simultaneously. For example, a missing value check covers both completeness and referential integrity when dealing with foreign keys.
How do data quality dimensions relate to data governance?
Data quality dimensions provide the measurable criteria for data governance policies. They help define SLAs, establish monitoring thresholds, and create accountability for data quality across teams.
How often should data quality checks run?
This depends on data criticality and change frequency. Real-time checks for mission-critical pipelines, hourly/daily for operational data, and weekly/monthly for historical or reference data are common patterns.










