
We have significantly improved the capability of Soda Cloud Metrics Store and now there is Soda Metric Monitors. Go here for more information: https://docs.soda.io/data-observability/metric-monitoring-dashboard
Soda Cloud Metrics Store supercharges a data engineer’s ability to test and validate data quality. It captures historical information about the health of data to support the intelligent testing of data across every workload and help data teams prevent data issues having a downstream impact.
The historical values provide a baseline understanding of what good data looks like. Based on those historical values, data and analytics engineers can test and validate data with dynamic threshold systems like change-over-time and anomaly detection, as part of a comprehensive end-to-end workflow that helps detect and resolve issues, and automatically alert the right people at the right time.
In this blog, we talk to Dirk and dive a little deeper into the Cloud Metrics Store main capabilities. Dirk is the feature lead for the Cloud Metrics Store.
Q: Why is testing important for data quality?
Dirk: Soda was built to address data availability, to help data teams discover, analyze, and resolve data quality issues. In order to discover these data issues, data engineers need to test data to ensure that their transformations keep running as expected.
The first place that you need to test data is at the point of ingestion. When ingesting data you want to be sure that all of the data has successfully moved from its source to the target destination. The second place that you need to test data is at the point of transformation. With transformation testing you will typically check pre- and post-conditions, such as schema checks, null checks, valid value checks, and referential integrity checks.
When this is done correctly, it results in good test coverage. I’m sure you’ve heard often enough that testing data needs to become a standard practice in data engineering, just as unit testing is in software engineering. This is why it needs to happen.
Q: So tell us the compelling use case to have and use historic metrics.
Dirk: Of course, it’s relatively straightforward. When writing tests and validations for data quality, you might find that a simple fixed-threshold test isn’t sufficient. Let me sketch an example for you.
Let’s imagine that you want to implement a test into your data pipeline to test if the row count in your dataset is stable or changing. Setting this up with tests running in a stateless environment is pretty hard because firstly, it’s difficult to define. Secondly, a test like this will require regular updates which are not only unwieldy to manage but also costly and timely to maintain and quickly become unreliable.
To solve this problem, it’s been common practice for data engineers to build their own homegrown solutions that involve complex algorithms, storage systems, and inevitably require quite some resources and time to build and maintain.
At Soda, we wanted to find another way so that data teams can focus on building trusted data products and organizations can confidently use their data.
We realized that the happily-ever-after solution involved using historical information on the health of the data. In Soda Cloud the historical information is captured as part of the metric measurements used in tests. We could now start to leverage these measurements to write change-over-time tests.
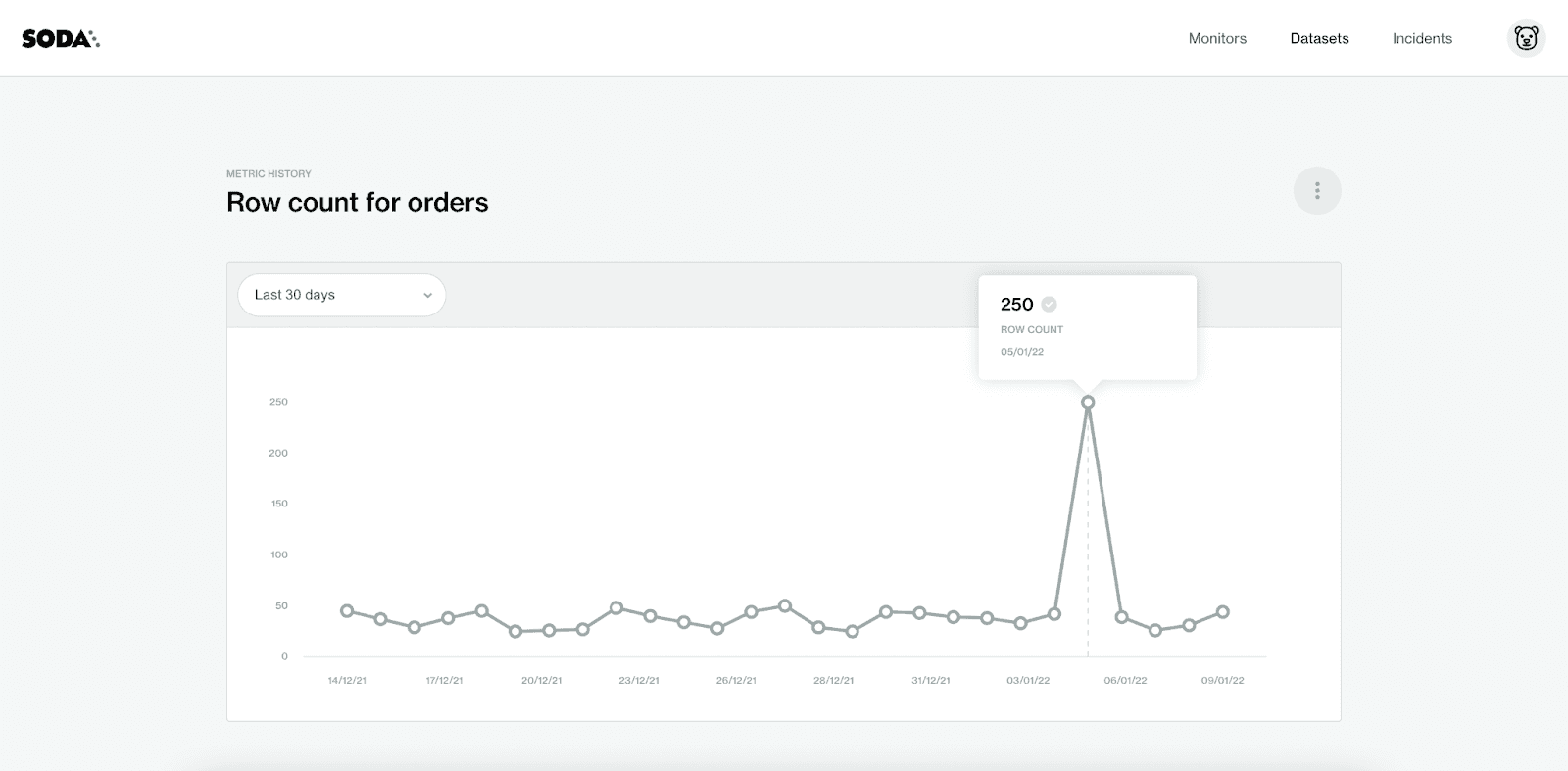
The Metric History for the monitor ‘Row count for orders’ for the last 30 days.
Q: That does sound like happily-ever-after. Can you break it down for us?
Dirk: By making the stored measurements for a metric available to data engineers, we are able to provide advanced testing-as-code capabilities that enable data teams to get ahead of data issues in a more sophisticated way than ever before.
Going back to the row count test: using the historical measurements of the row count tests means that you can implement this test into your data pipeline in a simple - dare I say easy - and reliable way.
When a Soda Scan is executed, the results appear in a table of ‘Monitor Results’. The measurements resulting from each test that is executed against the data are stored in the Cloud Metrics Store. You can access the historic measurements and write tests that use those historic measurements.
Let me delve in further. We’re still using this scenario where you need to implement a test into your data pipeline to test if the row count in your dataset is stable or growing.
Let’s test for “row_count > 5”.
When Soda scans a dataset, it performs a test. During a scan, Soda checks the metric (row_count) to determine if the data matches the parameters that were defined for the measurement (> 5). As a result of the scan, each test either passes or fails.
The measurements from each test are in the Cloud Metrics Store. Test results are displayed in a graph and users can easily visualize how their data changes over time. Is the dataset stable? Is it growing? Could it even be shrinking? And by how much?
Q: How do you define the historic metrics to write tests?
Dirk: We’ve tried to keep it simple and leverage the practice of advanced testing-as-code. The feedback from our community is that Soda is best-in-class because it allows data engineers to run data reliability and data quality checks (tests + validations), as code.
To do all this, we introduced historic measurements syntax. You can write tests in scan YAML files that test data against the historic measurements contained in the Cloud Metrics Store. Take a look at this example where you can see how the historic metrics are used to test if your dataset is growing:
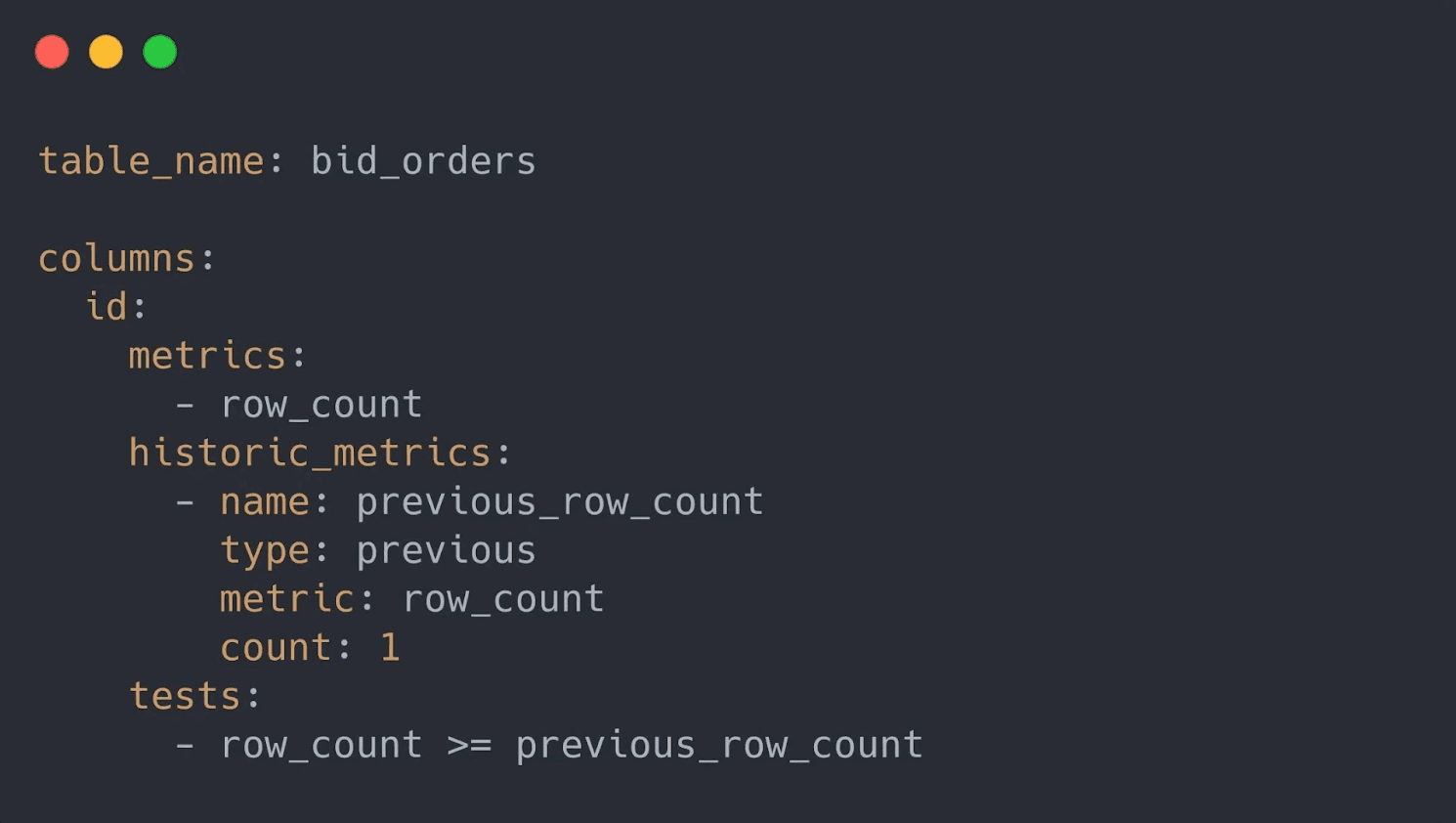
This example demonstrates how the test relies on a dynamic variable referring to the “row_count” of the previous scan, “previous_row_count”. The previous scan is accessible in the Cloud Metrics Store. Using a few additional lines in the YAML file, it’s easy to test if a data is changing in size.
Q: Does this test example work for every scenario so that I could aggregate to track moving averages?
Dirk: No, unfortunately test scenarios like the one earlier don’t always work for every scenario, because they’re testing against a single previous measurement. Come on, we couldn't make it that simple and easy!
Most, if not all, of you reading this know that when you’re dealing with data in production, the characteristics are often more complex. To add to the complexity of the characteristics, you’re dealing with “data noise” which makes it hard to rely on simple fixed-threshold tests which likely create false positives. And no-one thrives on alert fatigue!
I have a real-life example. One of the things that I love about my engineering role at Soda, is that I’m working with data engineers - and practitioners - who have experienced most of the problems we’re solving for every day. Those data issue-firefighters are in my office and together we’re building the very best platform that will change how easily data teams work together to make reliable data available 24/7.
One of the team, let’s call him Smokey Bear, was working on a project where his team was dealing with a system which relied on high-throughput data. For this team, every millisecond of latency had a direct and negative impact on the project’s revenue.

Smokey Bear's debut poster. Art by Albert Staehle.
Over time, Smokey and his team noticed that their revenue was decreasing, but they were unable to find the root cause. As they trawled through the data, they eventually discovered that the average of a column contained the system’s latency. The column average had been increasing, little by little, over time. Because it had been deemed acceptable for the latency to rise and fall over time, there was no check in place to test the average of the column against historical data.
As they worked to resolve the data issue, Smokey and his team realized that the problem could have been detected earlier if they had implemented a simple moving average in their data tests. However, the need to integrate a test that included previous measurements was not where they could invest their time and resources.
I know – if only Smokey and team had known about Soda’s Cloud Metrics Store because this is exactly the type of scenario that will put Soda’s historic metrics feature to the test.
With a few lines of the YAML syntax, Smokey could use an aggregate over multiple previous measurements. Soda takes the complexity away to make implementing a single moving average simple.

Using a few lines of the YAML syntax, you can calculate a delta based on the average of the last seven measurements. When the delta exceeds the fixed threshold, the test fails and the pipeline will stop. The bad data is efficiently quarantined for inspection before it is made available for data products and downstream consumers.
When data products, such as report or ML models, break down, teams are unable to make data-informed decisions with confidence and trust in the data erodes, and so I think now’s a good time to call out that Soda works across the entire data product lifecycle. We’ve worked hard to make it easy for data engineers to test data at ingestion and for data product managers to validate data before consumption in tools like Snowflake.
All checks can be written as code in an easy-to-learn configuration language. Configuration files are version controlled, and used to determine which tests to run each time new data arrives into your data platform. Soda supports every data workload, including data infrastructure, science, analysis, and streaming workloads, both on-premise and in the cloud.
Q: How can a data team get started?
Dirk: If you’re new to Soda, you can quickly (and easily!) get started for free. You’ll need to install Soda Tools, available as open source, and connect Soda Cloud, a free account available as a trial version. Existing users can get going with the historic metrics documentation. If you need help, contact the Soda Team in our Soda Community on Slack.
I’d love to know what you think and how you’ve used this feature in your project. Whether it’s utilizing previous measurements in your pipeline tests or implementing dynamic thresholds, please share your experience!
Q: What other features augment the Soda Cloud Metrics Store?
Dirk: Oh well, almost everything because we’re building the complete data quality workflow so that data teams can achieve end-to-end data observability. Our platform is built for everyone in a modern data team to get involved in finding, analyzing, and resolving data issues. I may have a particular favorite in Soda Incidents because it completes the workflow to detect and resolve issues.
Q: What are you excited about?
Dirk: There’s a lot happening at Soda and in the big world of data management! Our newest integration, dbt + Soda, brings the powerful capabilities of Soda Incidents (and actually the entire Soda Cloud platform) to the powerful transformation tool that is dbt. The coolest thing that excites me the most, is the new language that we are working on. That promises to be a game-changing capability for everyone: low code for the win!
And there’s much, much more. Stay connected and up-to-date in the Soda Community on Slack.
Read more about how to get started with Cloud Metrics Store in our Soda Documentation.
Thank you Dirk and team!











